最近看了一些图像生成的论文和博客,觉得要总结一下。本文主要介绍图像生成技术,包括研究背景、研究意义、相关应用、以及所用到的技术。
目录
一、背景与意义
二、图像生成应用
2.1 图像到图像的转换
2.2 文本到图像的生成
2.3 图像超分辨率
2.4 风格迁移
2.5 交互式图像生成
三、图像合成技术
3.1 生成对抗网络
3.2 变分自编码器
参考文献
一、背景与意义
通常深度学习(监督学习)需要依靠大量数据来训练网络,数据量越多,训练出来的网络具有更好的泛化性能。然而,收集数据需要耗费人力和财力,这使得研究人员只能针对各别相对重要的任务收集足量的数据。因此,大部分视觉任务的训练数据目前依旧处于缺失或不足的状态。这使得该任务的深度学习网络不具备足够的泛化能力,无法很好地应用落地。
大多数视觉任务具有相同的特点:数据采集困难,这一特点阻碍了研究人员利用深度学习算法去解决任务。因此,如何采集数据或增大数据量成为了解决大多数视觉问题的首要任务。针对没有训练数据或数据量太少的问题,研究人员提出了无监督训练,图像生成(数据增广)等方法。

图1.1 图像生成示例
图像生成任务旨在基于用户需求,自动生成对应的图像。(意义)
- 一方面,图像生成的研究能够快速构造服务于深度学习训练的海量数据,生成场景任务所需的数据,进一步促进了计算机对于图像信息的理解。
- 另一方面,图像生成的发展也带来了图像编辑、图像恢复、文本图像转化等有趣且重要的应用,如图1.2所示。可见,图像生成作为计算机视觉领域的重要研究方向,具有巨大的应用潜力。

图1.2 图像生成的部分应用
根据生成图像内容进行分类,图像生成任务可分为单物体图像生成与多物体场景图像生成两种。单物体图像生成仅需要关注单个对象的生成细节,场景图像的生成往往需要考虑多个实例物体,物体间需要满足合理恰当且适应于用户需求的语义布局关系,因而场景图像生成任务复杂性较高,挑战性较强,且具有丰富的理论研究意义。
通过场景图像生成技术,计算机可以创造用户指定场景的虚拟艺术作品,也可以根据用户需求自动实现多物体的平面设计及家具布局,因而场景图像生成还具有广泛的实际应用价值。
二、图像生成应用
图像生成应用广泛应用于多个领域,通过算法和模型生成逼真、创新的图像内容。这些应用包括图像合成与修复、图像增强与超分辨率、图像风格转换、图像生成与填充以及视频生成与动态场景合成等。
图像生成与填充应用中,通过生成对抗网络等技术生成新的图像样本,扩充数据集、数据增强,提高深度学习模型的泛化能力和性能,同时也可以根据给定的部分图像生成完整的图像,填充缺失区域。
2.1 图像到图像的转换
图像到图像的转换,是将输入图像转换为具有特定目标属性或风格的输出图像。这项技术通过训练模型来学习输入图像和目标图像之间的映射关系,从而实现图像的转换和修改。
图像到图像的转换示例,如图2.1所示,有驾驶场景的从简单草图生成真实场景图,有地图场景的卫星图生成道路拓扑图,有灰度图生成彩色图等。
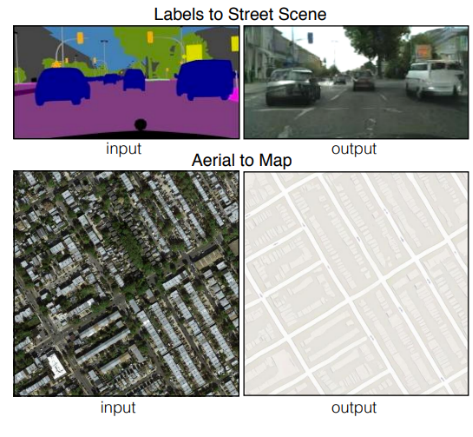

图2.1 图像到图像的转换示例
基于深度学习的图像到图像转换,成为的主流方法。以下是一些常见的基于深度学习的技术:
a. 生成对抗网络(GAN):GAN是一种用于生成新图像的神经网络模型。它由生成器和判别器组成。生成器试图生成逼真的输出图像,而判别器则试图区分生成的图像和真实的图像。通过对抗性训练,生成器逐渐学习到如何生成与真实图像相似的输出。
b. 自编码器(Autoencoder):自编码器是一种用于学习数据的低维表示的神经网络模型。在图像到图像转换中,可以使用自编码器进行特征提取和重建。通过将输入图像编码为低维表示,然后将其解码为输出图像,自编码器可以学习到输入图像的特征表示和重建能力。
c. 条件生成模型:条件生成模型是在生成过程中引入额外的条件信息。在图像到图像转换中,条件可以是输入图像的特征、风格或语义信息。通过将条件信息与生成模型的输入进行联合训练,可以实现更精确和可控的图像转换。
这些图像到图像的转换任务使用了各种机器学习和深度学习技术,包括卷积神经网络CNN、生成对抗网络GAN、图像优化算法等。这些技术的发展使得图像的转换和修改变得更加精确、高效和灵活,为图像处理和应用提供了强大的工具和方法。
2.2 文本到图像的生成
它可以从文本描述中生成图像,其步骤类似于图像到图像的翻译。文本到图像生成示例,如图2.2,输入一段文字,模型分析文字含义生成相应的图片。

图2.2 文本到图像的生成示例
文本到图像的生成过程通常包含以下步骤:
1、文本表示:首先,将输入的文本描述转换为计算机可理解的向量表示。这可以通过将单词映射为词向量(如Word2Vec、GloVe)或使用预训练的语言模型(如BERT、GPT)来实现。这样可以捕捉文本中的语义和上下文信息。
2、图像生成模型:基于文本描述生成图像的关键是设计一个有效的图像生成模型。常用的模型包括卷积神经网络CNN、循环神经网络RNN和生成对抗网络GAN。这些模型通过学习文本和图像之间的映射关系,以生成与文本描述相匹配的图像。
3、训练过程:在训练过程中,模型接收文本描述作为输入,并尝试生成与描述相符的图像。模型通过最小化生成图像与真实图像之间的差异来不断优化自身的参数。这通常涉及到使用损失函数(如像素级别的损失或感知损失)来度量生成图像的质量。
4、评估和改进:生成的图像需要经过评估和改进的过程。评估可以使用人类评价,如主观评分或比较实验,以及客观评价指标,如图像质量评估指标。根据评估结果,可以对生成模型进行调整和改进,以提高生成图像的质量和准确性。
目前将具有代表性的基于深度学习的文本到图像生成方法总结归纳如图2.3所示。

图2.3 文本到图像生成方法总结
文本到图像的生成技术在很多应用领域都具有潜在的应用价值。例如,它可以用于辅助虚拟场景的构建、帮助人们将想法和描述转化为可视化的形式、辅助创作艺术作品等。随着深度学习和自然语言处理领域的不断发展,文本到图像的生成技术也将不断进步和完善。
2.3 图像超分辨率
图像超分辨率,指的是通过算法和技术将低分辨率图像转换为高分辨率图像的过程。简而言之,它可以使图像的细节更加清晰和精确。图像超分辨率的目标是增加图像的空间分辨率,即增加图像中可见细节的数量和清晰度。这对于许多应用非常重要,如图像放大、视觉增强、医学图像分析等。
超分辨率是从较小的图像创建高分辨率图像的过程,比如一张分辨率为640x480的图像,通过此技术,生成一张2560x1920的超高清图像。效果示例如图2.4所示。

图2.4 图像超分辨率示例
图像超分辨率的方法有几种,以下是其中几种常见的方法:
A.插值方法:
插值是一种简单而直接的图像超分辨率方法。它通过在已知像素之间填充新像素来增加图像的分辨率。最简单的插值方法是线性插值,即使用相邻像素的加权平均值来生成新的像素值。更高级的插值方法,如双线性插值、双三次插值等,可以提供更好的图像细节保留和平滑效果。
B.基于边缘的方法:
基于边缘的方法利用图像中的边缘信息来增加分辨率。边缘是图像中颜色或亮度变化的地方,通常表示物体的边界或细节。通过识别和增强边缘,可以从低分辨率图像中恢复出更多的细节,并生成高分辨率图像。
C.基于深度学习的方法:
近年来,深度学习在图像超分辨率方面取得了重要的突破。通过使用深度神经网络,如卷积神经网络CNN和生成对抗网络GAN,可以学习从低分辨率图像到高分辨率图像的映射。这些模型通过大量的训练样本学习图像的特征和结构,并生成高质量的超分辨率图像。
- && 典型的卷积神经网络超分辨率模型包括SRCNN和ESPCN。这些模型通过多个卷积层和上采样操作逐步增加图像的分辨率,并利用大量的训练数据来学习图像的细节和结构。
- && 生成对抗网络方法在图像超分辨率中取得了重要的突破,其中ESRGAN,是一个广泛应用的模型。它通过堆叠多个生成器和判别器的层来增强超分辨率图像的质量和细节。
基于深度学习的图像超分辨率方法的关键在于大规模的训练数据和合适的网络架构。通常,使用高分辨率图像和相应的低分辨率图像对进行训练,使网络能够学习到图像中的特征和纹理信息。此外,为了提高超分辨率图像的质量,还可以使用损失函数,如均方误差和感知损失函数,来引导网络的训练过程。
图像超分辨率技术在许多领域都有广泛的应用。例如,在数字摄影中,它可以帮助改善图像质量和放大图像细节;在视频处理中,它可以提高视频的清晰度和细节呈现;在医学图像中,它可以帮助医生更准确地诊断和分析图像。
总的来说,图像超分辨率是一项重要的技术,可以通过不同的方法和算法将低分辨率图像转换为高分辨率图像,提高图像的清晰度和细节。
2.4 风格迁移
风格迁移可以将一个图像的风格与另一个图像的内容相结合,生成具有新颖艺术风格的图像。这项技术通过结合机器学习和深度学习的方法,让计算机能够理解和应用不同图像之间的风格和内容。
风格迁移是将不同风格迁移到任何图像的过程,示例效果如图2.5所示。

图2.5 风格迁移示例
风格迁移方法主要包括基于优化的方法和基于神经网络的方法两类。基于优化的风格迁移方法,使用了卷积神经网络CNN和图像优化算法。这些方法通过最小化损失函数来优化生成图像的像素值,使其同时匹配内容图像和风格图像的特征统计信息。
基于神经网络的风格迁移方法使用了生成对抗网络GAN和卷积神经网络CNN等深度学习模型,通过训练网络来学习风格迁移的映射关系。
风格迁移技术在艺术创作、图像编辑和设计等领域有着广泛的应用。它可以让我们将不同风格的艺术特征应用到自己的图像中,创造出个性化的艺术作品。此外,风格迁移还可以用于图像增强、图像风格转换和虚拟现实等方面,为图像处理带来了新的可能性。
2.5 交互式图像生成
交互式图像生成,它允许用户通过与计算机系统进行实时的、双向的交互来生成图像。与传统的图像生成方法相比,交互式图像生成赋予用户更多的控制权和参与度,使其能够直接参与图像的创作过程。
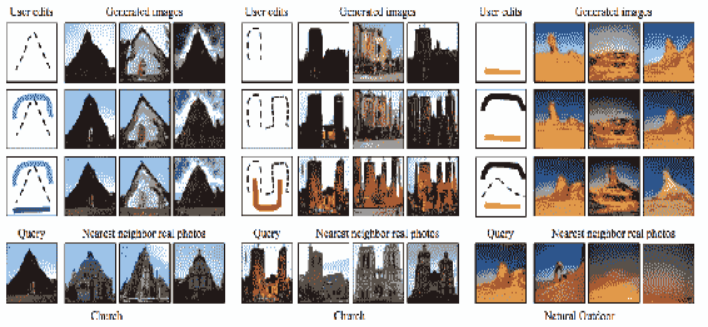
图2.6 交互式图像生成示例
如图2.6所示,图像是根据编辑的形状和颜色生成的。底部的绿色笔触创建了草原,矩形创建了摩天大楼。图像将被生成并通过用户的进一步输入进行微调。生成的图像还可以用于检索可以利用的最相似的真实图像。提供交互式图像生成是一种直观搜索图像的全新方法。
交互式图像生成方法通常结合了计算机视觉、计算机图形学和人机交互等领域的技术。深度学习生成模型是常见的交互式图像生成方法,如生成对抗网络GAN和变分自编码器VAE,可以用于交互式图像生成。这些模型可以通过与用户进行实时的交互,根据用户的输入和反馈来生成图像。用户可以通过向模型提供不同的输入,如文字描述、草图或引导图像,来指导生成过程。
交互式图像生成不仅可以用于个人艺术创作和娱乐,还可以在设计、虚拟现实和人机界面等领域发挥重要作用。它提供了一种更直接、灵活和创造性的方式,让用户参与到图像生成的过程中,实现个性化和定制化的图像创作。
三、图像合成技术
图像合成技术可以分为传统算法和深度学习算法,其中传统算法包括基于规则的合成方法、图像融合、基于纹理的合成等。
基于规则的合成方法:基于规则的合成方法使用预定义的规则和算法来生成合成图像。这些规则可以包括几何变换(如平移、旋转、缩放)、颜色调整、纹理重复等。例如,在图像编辑软件中,可以使用图层混合模式、蒙版、滤镜等功能来合成图像。基于规则的合成方法适用于简单的合成任务,可以在不需要大量数据和复杂模型的情况下进行合成。
图像融合:图像融合是将两个或多个图像的某些部分或特征进行融合,生成一个具有两者特点的合成图像。常见的图像融合方法包括像素级融合、多重曝光、平均融合、拉普拉斯金字塔融合等。像素级融合通过像素级别的操作,如逐像素求平均、逐像素加权融合等,将两个或多个图像融合在一起。多重曝光是将多张图像的亮度信息进行叠加,以获得综合的效果。拉普拉斯金字塔融合使用金字塔结构和拉普拉斯金字塔图像表示,通过合成图像的不同层级和频率信息进行融合。
基于纹理的合成:基于纹理的合成方法使用已有的纹理样本来生成新的纹理图像。这些方法可以通过模型或统计学方法来捕捉和重建纹理特征。其中,基于马尔可夫随机场(MRF)的方法使用概率模型来建模纹理特征的统计分布,并通过采样和优化算法生成新的纹理图像。另一种方法是使用纹理合成算法,通过分析纹理样本的局部特征和结构信息,生成具有相似纹理特征的合成图像。
基于深度学习的图像合成算法,主要有生成对抗网络GAN、变分自编码器VAE等。目前主流图像合成算法,是基于生成对抗网络实现的。
生成对抗网络,由生成器和判别器组成。生成器负责生成逼真的图像,判别器则用于评估生成的图像的真实性。通过对生成器和判别器进行对抗性训练,生成对抗网络可以学习到数据的分布并生成逼真的合成图像。
变分自编码器,是一种基于概率图模型的生成模型,用于学习输入数据的潜在表示并生成新的样本。它可以学习到数据的潜在变量表示,并使用这些变量生成新的图像。
3.1 生成对抗网络
生成对抗网络(Generative Adversarial Networks,GANs)是一种深度学习模型,用于生成逼真的合成数据,如图像、音频或文本等。
GAN由两个主要组件组成:生成器(Generator)和判别器(Discriminator)。生成器负责生成逼真的合成数据,而判别器负责评估输入数据是真实数据还是生成器生成的数据。

图3.1 GAN模型结构
训练过程中,生成器和判别器相互对抗地进行训练。生成器通过接收一个随机噪声向量作为输入,经过一系列的转换和映射操作,生成与真实数据相似的合成数据。判别器则接收真实数据和生成器生成的数据,并将它们区分开来。生成器的目标是尽可能地欺骗判别器,使其无法区分真实数据和生成数据,而判别器的目标是尽量准确识别出真实数据和生成数据。

图3.2 GAN结构
如图3.2所示,显示了GAN的训练过程。在a中,通过更新判别分布(蓝色虚线)使其能够区分输入是来自真实分布(黑色虚线)还是生成数据分布(绿色实线)。在b中,判别器经过训练可以区分真假数据,并且很容易完成任务。在图c中,固定判别器,只训练生成器,使其生成假数据的分布更接近真实数据分布。更新一直持续到判别器无法区分为止(d)通过反复迭代训练生成器和判别器,GAN能够逐渐提升生成器生成的合成数据的质量和逼真度,使其接近真实数据的分布。训练过程中的动态博弈促使生成器和判别器相互竞争和提高,最终达到一个动态平衡点。
在图像生成领域中,有许多基于GAN的算法,下面介绍其中几种常见的算法:
- 原始GAN(GAN):最早提出的生成对抗网络,由生成器和判别器组成。生成器负责生成逼真的图像样本,判别器负责将生成的图像与真实图像进行区分。通过对抗性训练,生成器和判别器相互竞争和优化,使生成器生成更逼真的图像,判别器更准确地区分真实和合成图像。
- 条件GAN(cGAN):cGAN在原始GAN的基础上引入了条件信息,使生成器能够生成特定条件下的图像。通过给生成器和判别器提供条件向量,例如标签或文本描述,可以生成具有特定属性的图像。cGAN被广泛应用于图像到图像的转换任务,如图像风格转换和语义分割到图像的转换。
- Deep Convolutional GAN(DCGAN):它是一种基于卷积神经网络的GAN变体,专门用于图像生成。它在生成器和判别器中使用了卷积层和反卷积层,并使用批归一化和LeakyReLU等激活函数,以稳定训练和生成高质量图像。
- Wasserstein GAN(WGAN):它通过使用Wasserstein距离(Earth-Mover距离)作为损失函数来改进GAN的训练稳定性。WGAN关注生成器生成的图像与真实图像之间的分布差异,使得生成器生成的图像更接近真实分布。此外,WGAN还使用了权重剪裁等技巧来减轻训练中的模式崩溃问题。
- Progressive GAN(PGAN):它是一种渐进式训练的GAN方法,用于生成逐渐增加分辨率的图像。它从低分辨率开始训练生成器和判别器,然后逐渐增加分辨率,同时将之前训练的模型作为初始参数。通过渐进式训练,PGAN能够生成更高质量和更细节的图像。
除了上述算法,还有许多其他的GAN变体和改进方法,如CycleGAN、StarGAN、StyleGAN等。这些算法在图像生成领域中发挥重要作用,不断推动着图像生成的质量和多样性的提升。
看一表格:GAN衍生变体分类

3.2 变分自编码器
变分自编码器(Variational Autoencoder,VAE)是一种基于概率图模型的生成模型,用于学习输入数据的潜在表示并生成新的样本。
VAE的基本思想是将输入数据编码为潜在空间中的潜在变量,然后从潜在空间中解码生成新的样本。与传统的自编码器不同,VAE引入了概率分布的概念,通过对潜在变量的建模,使得VAE能够对数据分布进行学习和采样。
VAE的结构包括编码器(Encoder)和解码器(Decoder),如图3.3所示。编码器将输入数据映射到潜在空间中的潜在变量,通常表示为均值和方差的参数。这些参数用于定义潜在变量的概率分布,通常假设为高斯分布。

图3.3 GAN结构
在训练过程中,VAE通过最大化观测数据的边缘似然来学习模型的参数。为了实现这一点,VAE引入了重参数化技巧,通过从潜在变量的概率分布中采样得到实际的潜在变量值。这样,通过将潜在变量通过解码器进行解码,可以生成与原始输入数据相似的新样本。VAE不仅可以用于生成新的样本,还可以用于数据压缩和潜在空间的可视化。通过在潜在空间中对潜在变量进行插值和操作,可以实现对生成样本的控制和编辑。
总结一下,变分自编码器是一种概率图模型,用于学习数据的潜在表示和生成新的样本。它通过编码器将输入数据映射到潜在空间中的潜在变量,并通过解码器从潜在变量中生成新的样本。通过最大化观测数据的边缘似然来训练模型,并通过重参数化技巧进行采样。变分自编码器在生成模型和数据压缩等任务中具有广泛的应用。

参考文献
[1] 孙书魁,范 菁,曲金帅,路佩东.生成式对抗网络研究综述[J].计算机工程与应用.2022
[2] 王宇昊,何 彧,王 铸.基于深度学习的文本到图像生成方法综述[J].计算机工程与应用.2022
[3] 肖贺文.知识图谱指导的场景图像生成[D].大连理工大学.2022
[4] 宗雨佳.两阶段草图至图像生成模型与应用实现[D].大连理工大学.2021
[5] 文强.基于循环生成对抗网络的图像生成技术研究[D].华南理工大学.2020
分享完成,谢谢~