文章目录
- 1 要点
- 1.1 概述
- 1.2 一些概念
- 1.3 代码
- 1.4 引用
- 2 基础知识
- 2.1 符号
- 2.2 信息传递神经网络 (MPNN)
- 3 方法
- 3.1 子图提取
- 3.1.1 基于节点的策略
- 3.1.2 基于图的策略
- 3.2 随机游走返回概率编码
- 3.3 子图信息注入的信息传递
1 要点
1.1 概述
题目:子结构感知图神经网络 (Substructure aware graph neural networks, SAGNN)
背景:尽管图神经网络 (GNN) 在图学习方面取得了巨大成就,但由于GNN的传播范式与一阶Weisfeiler-Leman图同构测试算法 (1-WL) 的一致性,导致其难以突破1-WL表达能力的上限。
思路:通过子图更容易区分原始图。
方法:提出子结构感知图神经网络 (SAGNN):
- 剪切子图 (Cut subgraph):通过连续且有选择地去除边获得;
- 随机游走编码范式扩展到子图上跟节点的返回概率,以捕获结构信息并将其作为节点特征,以提高GNN的表达能力;
- 理论证明所提出的SAGNN相较于1-WL的强结构感知能力。
1.2 一些概念
- 1-WL:一种图同构测试算法,用于判断两个图是否同构。传统GNN的表达能力与1-WL算法相当,也就是说,GNN不能区分1-WL不能区分的图;
- EgoNetwork:一种图的子结构,它由一个中心节点和它的邻居节点,以及它们之间的边组成;
- k k k跳内的节点集:与根节点之间的最短路径长度不超过 k k k的所有节点的集合;
- 边介数中心性 (EBC):通过一条边的最短路径的数量或比例,用于衡量边在图或网络中的重要性;
1.3 代码
https://github.com/BlackHalo-Drake/SAGNN-Substructure-Aware-Graph-Neural-Networks
1.4 引用
@inproceedings{Zeng:2023:1112911137,
author = {Ding Yi Zeng and Wan Long Liu and Wen Yu Chen and Li Zhou and Ma Lu Zhang and Hong Qu},
title = {Substructure aware graph neural networks},
booktitle = {{AAAI}},
pages = {11129--11137},
year = {2023},
url = {https://ojs.aaai.org/index.php/AAAI/article/download/26318/26090}
}
2 基础知识
2.1 符号
令 G = ( V , E , X ) G=(V,E,\mathbf{X}) G=(V,E,X)表示一个无向连通图,其中 V V V是节点的有限集、 E E E是边的有限集,以及 X = [ x 1 , x 2 , … , x n ⊤ ] \mathbf{X}=[\text{x}_1,\text{x}_2,\dots,\text{x}_n^\top] X=[x1,x2,…,xn⊤]是节点特征。
2.2 信息传递神经网络 (MPNN)
MPNN提供了一种通过消息传统机制的统一试图,以抽象GNN。在MPNN中,节点到节点的信息是通过迭代地将相邻节点的信息聚合到中心节点来传播。形式上,给定
G
G
G中的节点
i
i
i,其
t
t
t轮迭代的隐藏表示为
h
i
t
\mathbf{h}_i^t
hit、邻居节点为
N
(
i
)
N(i)
N(i)、边
e
i
j
\mathbf{e}_{ij}
eij连接了节点
i
i
i和
j
j
j,则标准信息传递范式表示为:
c
i
t
=
∑
j
∈
N
(
i
)
ϕ
t
(
h
i
t
,
h
j
t
,
e
i
j
)
,
(1)
\tag{1} \mathbf{c}_i^t=\sum_{j\in N(i)}\phi^t(\mathbf{h}_i^t,\mathbf{h}_j^t,\mathbf{e}_{ij}),
cit=j∈N(i)∑ϕt(hit,hjt,eij),(1)
h
i
t
+
1
=
σ
t
(
c
i
t
,
h
i
t
)
,
(2)
\tag{2} \mathbf{h}_{i}^{t+1}=\sigma^t(\mathbf{c}_i^t,\mathbf{h}_i^t),
hit+1=σt(cit,hit),(2)其中
ϕ
t
\phi^t
ϕt和
σ
t
\sigma^t
σt分别表示聚合和更新函数。
3 方法
MPNN在足够深度和宽度的表达能力方面仍然不能超过1-WL,而区分更大的图则需要更强的表达能力。基于子图比原始图更容易区分这一事实,本文讲图同构问题概括为子图同构问题,并依次介绍所提出的SAGNN的三个步骤:a) 子图提取;b) 子图随机游走返回概率编码;以及
c
\text{c}
c) 子图信息注入。具体如图1。
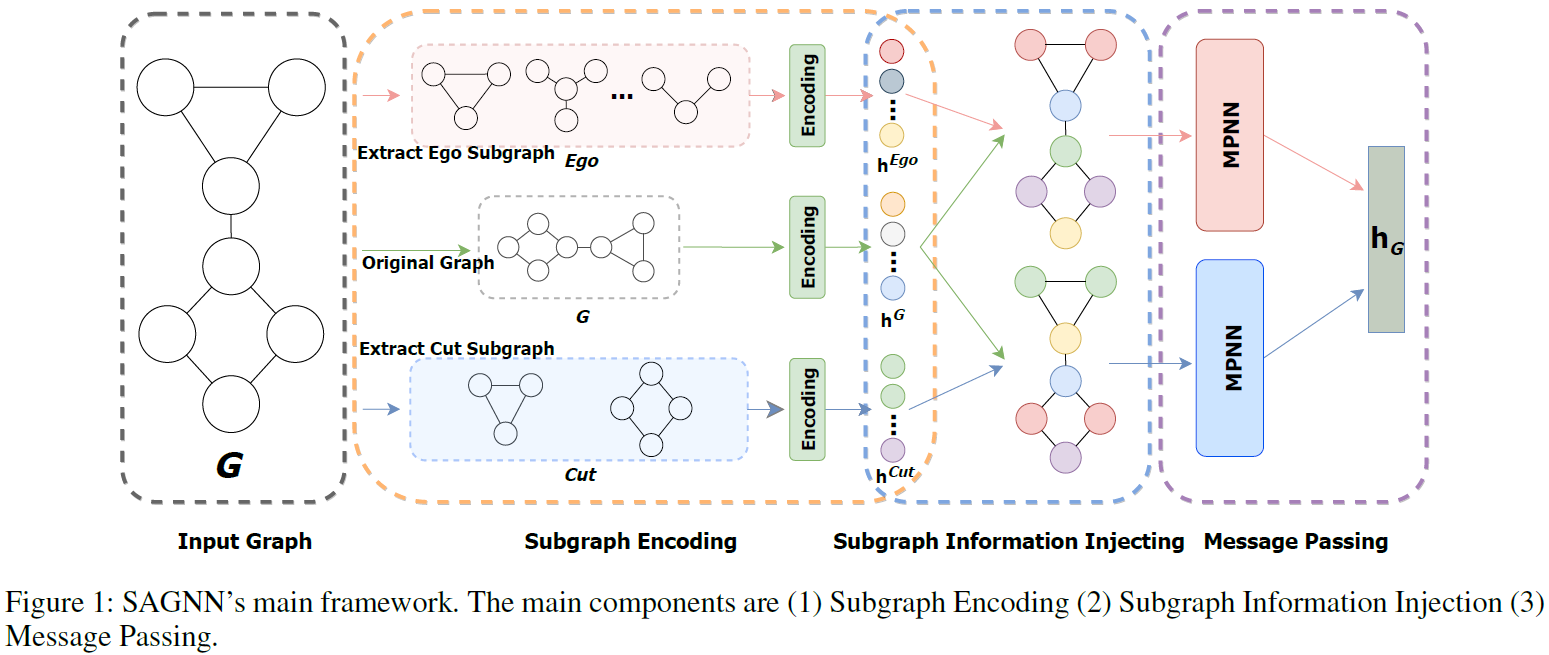
3.1 子图提取
子图提取是模型表达的关键步骤,其被分为基于节点和基于图的策略。
3.1.1 基于节点的策略
该策略定义为基于单个节点的子图提取,即不需要完整图的信息。通常而言,在当前策略中。子图的数量等于原始图中节点的数量,其中EgoNetwork是最常用的策略。
令 N ( v ) N(v) N(v)表示根节点 v v v的邻居节点的集合, N k ( v ) N_k(v) Nk(v)表示 k k k跳内节点集。 E g o ( v ) k Ego(v)_k Ego(v)k是以节点 v v v为根节点的的k跳EgoNetwork,其对应节点是根节点 v v v的k跳 N k ( v ) N_k(v) Nk(v)内的邻居。
3.1.2 基于图的策略
该策略需要整张图的信息以获取子图,其子图的数量与原始图中的节点数无直接联系。最简单的策略是随机删除一个边或者一个节点,但这很难提升模型的表示能力,且在高密度强规则图中的性能很差。为了提升GNN的表达能力,本文提出了剪切子图。
定义1 C u t ( v ) b Cut(v)_b Cut(v)b子图定义为 b b b个块中包含节点 v v v的块,其通过从原始图中去除边获得:首先计算原始图中所有边的边介数中心性 (Edge betweenness centrality, EBC),并持续去掉图中具有最大EBC的边,直到图被划分为 b b b块。
- b = 1 b=1 b=1时 C u t ( v ) b Cut(v)_b Cut(v)b等价于原始图。随着 b b b的增加, C u t ( v ) b Cut(v)_b Cut(v)b的大小及其包含的信息级别均下降;
- b b b等于节点数时, C u t ( v ) b Cut(v)_b Cut(v)b等价于节点;
- C u t ( v ) b Cut(v)_b Cut(v)b是包含节点 v v v的连通图。
3.2 随机游走返回概率编码
在子图中计算返回概率,可以有效应对图编码的随机游走的时间开销大或者表达欠缺的问题。具体地,在子图
G
s
u
b
G_{sub}
Gsub中,节点
v
v
v的随机游走返回概率编码定义为:
p
v
G
s
u
b
=
[
R
G
s
u
b
1
(
v
,
v
)
,
R
G
s
u
b
2
(
v
,
v
)
,
…
,
R
G
s
u
b
S
(
v
,
v
)
]
T
,
\boldsymbol{p}_v^{G_{sub}}=\left[ \boldsymbol{R}^1_{G_{sub}}(v,v), \boldsymbol{R}^2_{G_{sub}}(v,v),\dots,\boldsymbol{R}^S_{G_{sub}}(v,v) \right]^T,
pvGsub=[RGsub1(v,v),RGsub2(v,v),…,RGsubS(v,v)]T,其中
R
G
s
u
b
s
(
v
,
v
)
\boldsymbol{R}^s_{G_{sub}}(v,v)
RGsubs(v,v)是
s
s
s步随机游走在子图
G
s
u
b
G_{sub}
Gsub中从节点
v
v
v开始的概率。基于此,分别获得对Ego子图和Cut子图的返回概率
p
v
E
g
o
\boldsymbol{p}_v^{Ego}
pvEgo和
p
v
C
u
t
\boldsymbol{p}_{v}^{Cut}
pvCut。接下来,使用一个线性层将返回概率编码为子图隐藏表示向量
h
v
E
g
o
\mathbf{h}_v^{Ego}
hvEgo和
h
v
C
u
t
\mathbf{h}_v^{Cut}
hvCut。注意,单个节点的Ego编码是所有包含当前节点的Ego子图编码的汇聚。
3.3 子图信息注入的信息传递
为了注入子图信息并捕捉全局结构信息,本文同时拼接了子图隐藏表示向量和对应于原始图
G
G
G的节点
v
v
v的结构隐藏表示
h
v
G
\mathbf{h}_v^{G}
hvG。最终获取的子图信息注入特征定义为:
h
v
E
,
0
=
[
x
v
,
h
v
E
g
o
,
h
v
G
]
,
h
v
C
,
0
=
[
x
v
,
h
v
C
u
t
,
h
v
G
]
.
(4)
\tag{4} \mathbf{h}_v^{E,0}=[\mathbf{x}_v,\mathbf{h}_v^{Ego},\mathbf{h}_v^G],\mathbf{h}_v^{C,0}=[\mathbf{x}_v,\mathbf{h}_v^{Cut},\mathbf{h}_v^G].
hvE,0=[xv,hvEgo,hvG],hvC,0=[xv,hvCut,hvG].(4)信息传递通道包括Ego通道和Cut通道,分别定义为:
c
v
E
,
t
=
∑
u
∈
N
(
v
)
ϕ
E
t
(
h
v
E
,
t
,
h
u
E
,
t
,
e
v
u
)
,
(5)
\tag{5} \mathbf{c}_{v}^{E,t}=\sum_{u\in N(v)}\phi_E^t(\mathbf{h}_v^{E,t},\mathbf{h}_u^{E,t},\mathbf{e}_{vu}),
cvE,t=u∈N(v)∑ϕEt(hvE,t,huE,t,evu),(5)
c
v
C
,
t
=
∑
u
∈
N
(
v
)
ϕ
C
t
(
h
v
C
,
t
,
h
u
C
,
t
,
e
v
u
)
,
(6)
\tag{6} \mathbf{c}_{v}^{C,t}=\sum_{u\in N(v)}\phi_C^t(\mathbf{h}_v^{C,t},\mathbf{h}_u^{C,t},\mathbf{e}_{vu}),
cvC,t=u∈N(v)∑ϕCt(hvC,t,huC,t,evu),(6)
h
v
E
,
t
+
1
=
σ
E
t
(
c
v
E
,
t
,
h
v
E
,
t
)
,
h
v
C
,
t
+
1
=
σ
C
t
(
c
v
C
,
t
,
h
v
C
,
t
)
,
(7)
\tag{7} \mathbf{h}_v^{E,t+1}=\sigma_E^t(\mathbf{c}_v^{E,t},\mathbf{h}_{v}^{E,t}),\mathbf{h}_v^{C,t+1}=\sigma_C^t(\mathbf{c}_v^{C,t},\mathbf{h}_{v}^{C,t}),
hvE,t+1=σEt(cvE,t,hvE,t),hvC,t+1=σCt(cvC,t,hvC,t),(7)其中
ϕ
t
\phi^t
ϕt和
σ
t
\sigma^t
σt分别是汇聚和更新函数。最终,全局图表示
h
G
\mathbf{h}_G
hG通过全局池化获得:
h
G
=
POOL
(
{
h
v
E
,
L
,
h
v
C
,
L
∣
v
∈
V
}
)
.
(8)
\tag{8} \mathbf{h}_G=\text{POOL}(\{ \mathbf{h}_v^{E,L},\mathbf{h}_{v}^{C,L}|v\in V \}).
hG=POOL({hvE,L,hvC,L∣v∈V}).(8)