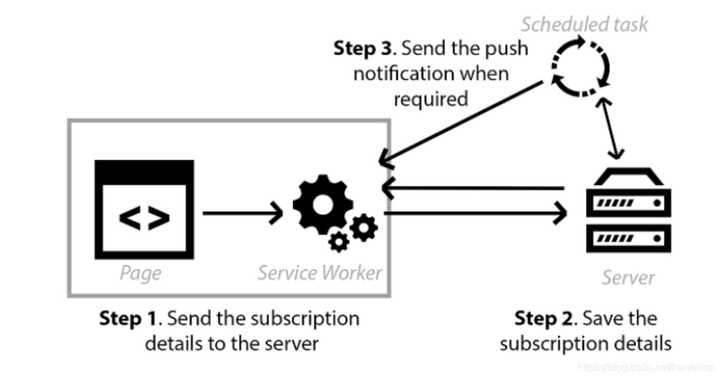
5G 时代,意味着数据通信将会拥有更高的速率、更大的容量和更低的时延。随着数据量的爆发式增长,对海量数据存储和实时分析成为数据淘金者的刚需,数据量暴增导致数据间的关联分析也越来越频繁。如何快速对数据进行分析,并获取其中有价值的信息;能够在亿级明细大表间关联分析,有很好的实时效率,通常存在以下问题:
-
分析慢、成本高:数据分析前对数据要进行大量的加工处理,将数据转换成维度模型、星型模型或雪花模型,利用分析数据库对单个大宽表具有很好的性能特征来保障分析的性能,而数据加工处理需要较多的成本。
-
占用资源多:大表关联时通常有一个表的数据要全部加载到内存,导致内存溢出(OOM)的情况时有发生。
常规处理方式
汇聚各业务系统的数据时,利用类似 ETL 工具对数据进行清洗、整合,然后再利用数据编排类的工具,将相同维度的数据整合成大表,如下场景:
场景一:数据分析
按月度统计各区域用户的通话时长、通话费用、欠费总额、信用度、积分总额等信息。这其中通话时长、通话费用在 A 表中;欠费总额在 B 表中;信用度与积分分别在 C 与 D 的表中,其中 A、B、C、D 都是过亿的大表,如果编排数据,实现此需求的 SQL 为:
select 月份、地区、移动号码、sum(通话时长)、sum(通话费用)、sum(欠费总额)、sum(信用度)、sum(积分) from A left join B on a.ph=b.ph,left join C on a.ph=c.ph, left join D on d.ph=d.ph where month=202305 group by 月份、地区、移动号码;由于 A、B、C、D 都过亿的大表,直接执行此 SQL,会出现运行时间过长或资源不足导致无法获取统计的结果。
场景二:数据分布探查
实时查看数据组成的分布情况,来确认是否可以使用此批数据做进一步的数据加工处理。比如查看已完成的订单数据的百分比,基于“p_order(订单表)”(亿级)与“f_order(竣工表)”(亿级)来关联分析来统计已完成的订单占比:
Selectorder_type订单类型,
sum(case when b.oder_status<>finished then 1 else 0 end) as processing,
sum(case when b.oder_status=finishedthen 1 else 0 end) as processedfrom p_order a leftjoin f_order b ona.orderid=b.orderid wherea.status=’OOA’group by a.order_type;由于竣工表、订单表都过亿的大表,如不做特殊的保障,执行过程中时长会超 60s 以上,实时查看的目标很难达成。
分析提速思路
将原有大表关联计算,通过合理的数据拆分成无数个小表,利用有限的资源多并发异步来提升分析效率。将原本大表间计算拆分成无数小表间的计算,从而有效保障计算的时效性,其实现过程中如下图所示:
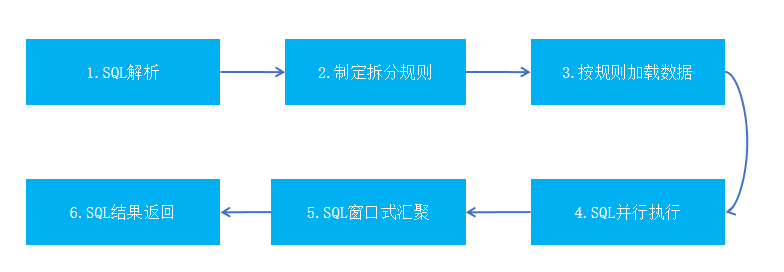
第一步:SQL 解析
利用 ANTLR 的特性解析 SQL 语句,从复杂的 SQL 中找出表以及关联关系。ANTLR 可以根据 SQL 语法规则生成解析器,并将其转化为对应的语法树,从树中获取 SQL 语句中的各个部分,例如 SELECT、FROM、WHERE 等关键字,以及它们对应的表、列、函数、运算符等信息。具体步骤如下图:

1)定义 SQL 语法规则:通过定义 SQL 语法规则,包括 select、update、insert 和 delete 四种语句类型,以及表达式、条件运算符等。
2)生成解析器代码:根据 SQL 语法规则,使用 ANTLR 生成对应的解析器代码,并将其转换成对应的语法树(AST)。
3)解析输入的 SQL 语句:通过解析器解析输入的 SQL,并将 SQL 变成 AST 树,如:
Selectorder_type订单类型, sum(case when b.oder_status<>finished then 1 else 0 end) as processing,
sum(case when b.oder_status=finishedthen 1 else 0 end) as processed
from p_order a leftjoin f_order b ona.orderid=b.orderid and b.stat=’00A’ wherea.name like ’n%’group by a.order_type;生成的语树如下:
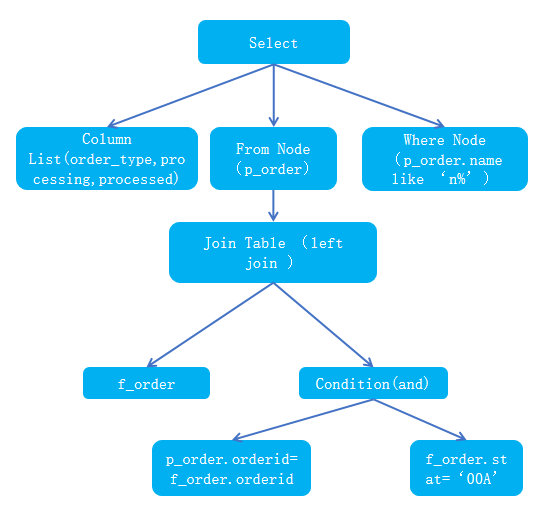
4)获取关联的表:从语法树找到树节点上的表以及表间的关联关系,如表 p_order、f_order 以及表间的关联关系 left join。
5)获取关联关系条件:从语法树中找到 condition 节点、表及关联关系的条件等,如:condition(and),找到条件 p_order.orderid=f_order.orderid and f_order.stat=‘00A’。
第二步:制定拆分规则
依据解析出来的库表、关联关系、字段等信息,从事先准备的数据中找出关联关系中最大范围的关联条件也即第一性关联条件,接合资源情况计算折分规则:
1)首先计算各节点的最佳并行数,其公式:

说明:
Ncpu : CPU 核心数
Ucpu : CPU 利用率,0-100%
W : I/O 等待时间
C : CPU 运行时间
W/C: CPU 运算时间比率
2)然后计算最佳参与计算数据量,其公式为:
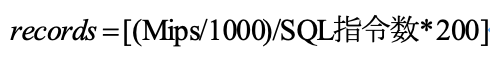
说明:
records:各节点的数据量的最佳值
MIPS:每秒执行多少百万条指令
MIPS/1000: 表示毫秒级内的百万条指令
SQL 指令数:表示一条 SQL 可转换成指令的个数
200:表示 200 毫秒,要保障秒极计算,需要拆分 SQL 在大部分在 200s 完成,留部分时间做数据汇聚类计算。
根据公式,如当前节点 cpu 是 MIPS:900MHz、复杂 SQL 大概转化成 100 个指令、6 个并发,200s 内并行计算时单节点与单窗口数据量最佳值为:
节点的数据量=(900Hhz/1000)/100*200=180 万
可同并行的窗口数为:
节点 2 的单个窗口数据量=180 万/6=30 万
3)依据范围分区制定规则:根据节点的并行数、计算数据量与单个窗口的数据量等参数制定数据拆分的规则,保障同维度关联的数据尽量落地同一个节点或就近的节点,范围分区较符合拆分的要求,拆分如下:
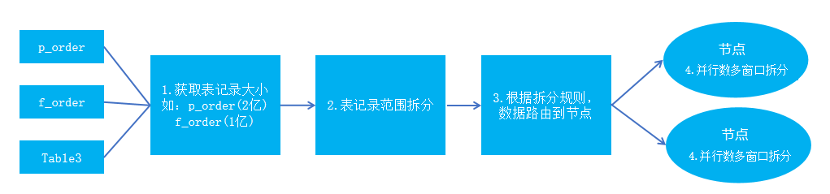
从缓存中获取表的记录数大小;
表记录范围拆分,根据第一性字段的值轮循拆分,其每次拆分的数据量不超过各节点的最佳的计算数据量的值,拆分过程按顺序加载数据到各节点上,当最后一个节点加载完后,表的数据还没有加载完成,会继续回到第一个节点轮循按顺序,直到拆分并加载完成所有的记录;
根据各节点计算出来范围来约定数据的范围,然后根据约定范围将数据路由到各节点;
数据路由到各节点上后,为保障数据的计算性能,会再次将数据拆分成多个窗口,拆分规则为: 1)记录窗口可载的记录数=节点的数据范围/并行数;2)根据节点的数据、并行数、每个并行窗口可加载的数据,根据第一性字段再平无分配加载条件,如 orderid>=0 and orderid<20w,可再次拆分为: (20w-0)/5=4w,其数据加载规则为:窗口 1=[0,4w),窗口 2=[4w,8w),窗口 3=[8w,12w),窗口 3=[12w,16w),窗口 5=[16w,20w]。
第三步:按规则加载数据
数据加载过程依据表间的第一性关联规则,对关联的字段值根据规则进行拆分,对拆分后的数据并发进行加载,同时为保障加载过程的高效性,将数据划分多份来并行、异步、预先初始化、队列管控等方式来保障加载的效率,如图所示:
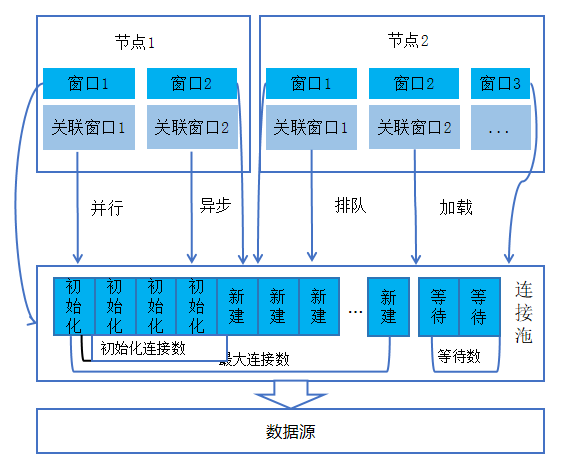
1) 节点数据加载的并行数:依据节点的窗口数、关联的表,其计算公式为:
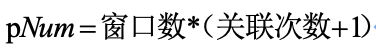
关联次数:表示 SQL 中同第一性条件关联的次数;
pNum:单节点数据加载的并行数;
依据节点可用的资源与并行数计算并初始化最小连接数。
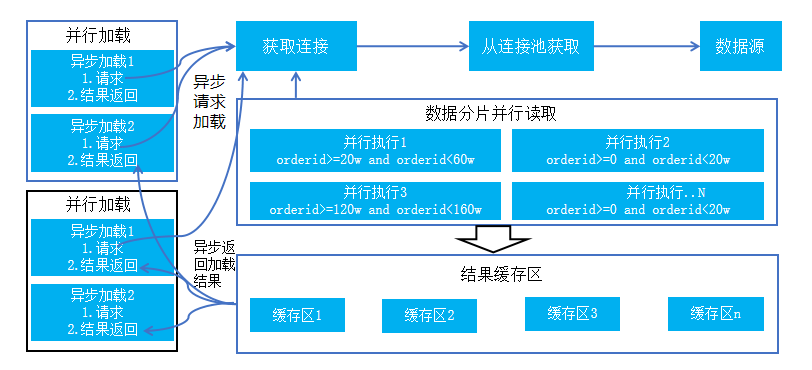
2) 节点并行异步加载:各节点分别在同一时刻并行异步加载数据,其实现逻辑如下描述:
第四步:SQL 并行执行
数据加载后,数据按分区及数据窗口的方式存储在各个分布式的节点上,同时会在各节点上自动构建执行区域,执行区的资源依据配置的参数与实际的资源对比,最小化的获取可用资源;参与计算的数据根据就近原则,先从本地窗口加载相关的数据,如果本地没有才选择最近的节点。

数据加载到各节点的窗口后,根据规则拆分的 SQL 语句,按分区并发行执行,其拆分 SQL 执行过程:
初始化并行执行区:根据计算出的”并行数“,初始化 SQL 的执行区个数;
SQL 引擎:采用业界性能最优的 ClickHouse_SQL、sparkSQL 为查询计算引擎,并在引擎中增加钩子 hook 函数,hook 函数在 SQL 执行完成后调用;
各并行执行区的 SQL 拼接与执行:根据之前加载数据时候的拆分条件在原来关联 SQL 基础上增加 where 条件来限定计算的范围,保障可以很精确的执行数据,如上述的 SQL 增加“p_order.orderid>0 and p_order.orderid<20w”后,并行执行;
执行结果返回:执行结果数据会存到新的窗口中,并调用钩子函数 hook,在 hook 函数,对新键的窗口进行标识与状态更新如:name:collw(标识:汇聚窗口),status:unuse(状态:未被使用),对已经参与计算的窗口状态标识为:status:used(已使用)。
第五步:SQL 窗口式汇聚
分区执行 SQL 产生的结果集相对比较分散,需要将各分区执行的 SQL 结果集进行汇聚,计算真正的结果。在汇聚的过程中依据一定的规则要求:首先会配置每个汇聚窗口的大小,然后获取各节点的空闲资源,各节点可以划分的汇聚窗口数量=空闲资源/配置大小,依据 SQL 结果集的大小尽量将相关的多个数据集汇聚一个汇聚窗口。如下图所示:
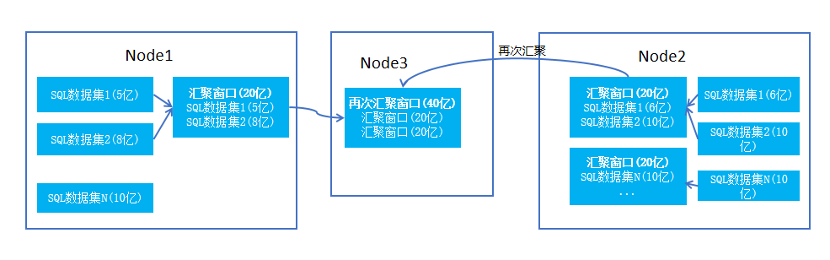
每个窗口的数据经过初步的关联、过虑与计算等后,汇聚窗口内数据已满足了 SQL 要求,如果没有汇聚类的操作是可以直接返回结果;当有汇聚之类的操作时,并且汇聚字段非分拆分字段,如:sum(f2) group by type(类型字段非拆分字段),其 group by 的值有可能跨不同窗口与节点,此时需要对数据多次汇聚才能得到最终的结果。两者在执行过程对原有 SQL 进行相应的调整,将关联的 SQL 变成单表的 SQL:
原有 SQL:
Selectorder_type, sum(case when b.oder_status<>finished then 1 else 0 end) as processing,
sum(case when b.oder_status=finishedthen 1 else 0 end) as processed
from p_order a leftjoin f_order b ona.orderid=b.orderid and b.stat=’00A’ wherea.name like ’n%’group by a.order_type;单表 SQL:(去掉原有 SQL 关联与过虑条件)
Selectorder_type , sum(processing) as processing,sum(processed) as processedfrom [table] group by order_type;复制代码
1)并行执行调整后的 SQL,并发执行调整后的 SQL 会再次生成新的窗口数据,由于是单表计算并且无复杂的计算逻辑,可以高效地保障执行性能。
2)执行结果返回,结果数据会存到新的窗口中,并调用钩子函数 hook 对新键的窗口进行标识与状态更新。
第六步:SQL 结果返回
将原本复杂关联的 SQL 变成了对单个大表的操作,依据原有 sql 中是否有聚合类的操作,选择不同的返回方式:
1)无聚合操作:只有关联与过滤类的操作,在第一次关联执行完成后,即可进行数据的返回,如下:

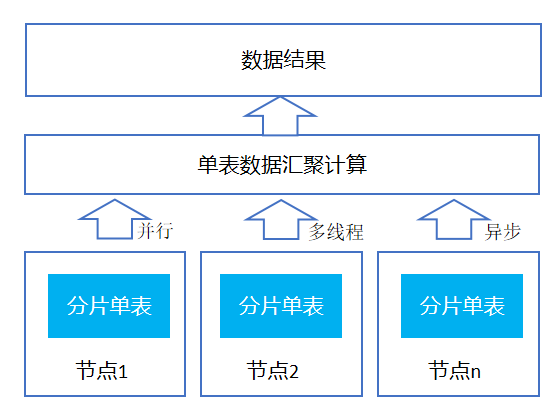
2)有聚合操作:如有 sum,count,avg,group by 等算子操作
经过汇聚计算后,最终每个节点的所有数据都合并成一个表,但由于有参与汇聚的数据可能在不同的节点,需要再次根据汇聚字段进分布式汇聚计算后返回数据,如下:
提速成效
总结一下,查看已完成的订单数据的百分比,基于“p_order(订单表)”(2 亿级)与“f_order(竣工表)”(1 亿级)来关联分析来统计已完成的订单占比;以及只查看两个表关联的详细数据的执行情况:
-
关联查询语句,如下 SQL:
selectb.order_type,a.orderid ,a.name,b.stat from p_order a leftjoin f_order b ona.orderid=b.orderid and b.stat=’00A’ wherea.name like ’n%’group by a.order_type;
-
统计分析语句,如下 SQL:
selectorder_type, sum(case when b.oder_status<>finished then 1 else 0 end) as processing, sum(case when b.oder_status=finishedthen 1 else 0 end) as processed from p_order a leftjoin f_order b ona.orderid=b.orderid and b.stat=’00A’ wherea.name like ’n%’group by a.order_type;
-
执行的效果对比:
通过对比分析,对大表按约定的规则进行适当的转换,将原来大表关联分析操作,转换成小表进行;将原本需要关联汇聚的操作变成单表汇聚的计算操作,在单表操作下不管数据量多大,基本上都可以做到秒级响应,满足很多复杂业务场景下的数据分析需求,提升数据使用需求的快速响应能力。







![[github-100天机器学习]day2 simple linear regression](https://img-blog.csdnimg.cn/740f485a014f4d4781a83af908cd3e66.png)