1、 Hadoop运行环境搭建
1.1、修改主机名和hosts文件
1)修改主机名称
sudo hostnamectl set-hostname <newhostname>
sudo hostnamectl set-hostname hadoop101
sudo hostnamectl set-hostname hadoop102
sudo hostnamectl set-hostname hadoop1032)配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts (此步操作三台机子都要执行)
[root@hadoop102 ~]# vim /etc/hosts添加如下内容
172.25.249.xxx hadoop102
172.25.249.xxx hadoop103
172.25.249.xxx hadoop1043)配置mac的hosts文件
47.97.164.xxx hadoop102
47.98.116.xxx hadoop103
121.40.67.xxx hadoop1044)开通以下端口
因为采用了阿里云服务器,访问需要开通端口
| 服务 | 端口 |
| Cloudera Manager Server(WebUI) | 7180 |
| HDFS NameNode(WebUI) | 9870 |
| SecondaryNameNode | 9868 |
| Yarn ResourceManager(WebUI) | 8088 |
| JobHistory Server(WebUI) | 19888 |
| HBase Master(WebUI) | 16010 |
| HiveServer2 (WebUI) | 10002 |
| HUE Server(WebUI) | 8888/8889 |
| Oozie Server | 11000 |
| Sentry Server | 51000 |
| Spark Master/Worker/History Server | 18080/18081/18088 |
| Kerberos | 88 |
| MySQL | 3306 |
1.2、环境前期准备 (以下操作三台机子都要执行)
1)联网情况检测
[root@hadoop102 ~]# ping www.baidu.com
PING www.a.shifen.com (180.101.50.188) 56(84) bytes of data.
64 bytes from 180.101.50.188 (180.101.50.188): icmp_seq=1 ttl=50 time=16.8 ms
64 bytes from 180.101.50.188 (180.101.50.188): icmp_seq=2 ttl=50 time=16.1 ms
64 bytes from 180.101.50.188 (180.101.50.188): icmp_seq=3 ttl=50 time=16.1 ms
64 bytes from 180.101.50.188 (180.101.50.188): icmp_seq=4 ttl=50 time=16.2 ms
2)安装epel-release
注:Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于是一个软件仓库,大多数rpm包在官方 repository 中是找不到的)
[root@hadoop102 ~]# yum install -y epel-release3)关闭防火墙,关闭防火墙开机自启
[root@hadoop102 ~]# systemctl stop firewalld
[root@hadoop102 ~]# systemctl disable firewalld.service注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安全的防火墙
4)创建shuidi用户,并修改shuidi用户的密码 ,密码:******
[root@hadoop102 ~]# useradd shuidi
[root@hadoop102 ~]# passwd shuidi5)配置shuidi用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop102 ~]# vim /etc/sudoers修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows members of the 'sys' group to run networking, software,
## service management apps and more.
# %sys ALL = NETWORKING, SOFTWARE, SERVICES, STORAGE, DELEGATING, PROCESSES, LOCATE, DRIVERS
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
shuidi ALL=(ALL) NOPASSWD:ALL注意:shuid这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了shuid具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以shuid要放到%wheel这行下面。
6)在/opt目录下创建文件夹,并修改所属主和所属组
(1)在/opt目录下创建module、software文件夹
[shuidi@hadoop102 ~]$ sudo mkdir /opt/module
[shuidi@hadoop102 opt]$ sudo mkdir /opt/software(2)修改module、software文件夹的所有者和所属组均为shuidi用户
[shuidi@hadoop102 opt]$ sudo chown shuidi:shuidi /opt/module
[shuidi@hadoop102 opt]$ sudo chown shuidi:shuidi /opt/software(3)查看module、software文件夹的所有者和所属组
[shuidi@hadoop102 opt]$ cd /opt/
[shuidi@hadoop102 opt]$ ll
总用量 8
drwxr-xr-x 2 shuidi shuidi 4096 6月 30 16:24 module
drwxr-xr-x 2 shuidi shuidi 4096 6月 30 16:25 software1.3、编写集群分发脚本xsync
1)xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析
①rsync命令原始拷贝:
rsync -av /opt/module root@hadoop103:/opt/②期望脚本:
xsync要同步的文件名称
③说明:在/home/shuidi/bin这个目录下存放的脚本,shuidi用户可以在系统任何地方直接执行。
(3)脚本实现
①在用的家目录/home/shuidi下创建bin文件夹
[shuidi@hadoop102 ~]$ mkdir bin②在/home/shuidi/bin目录下创建xsync文件,以便全局调用
[shuidi@hadoop102 bin]$ cd /home/shuidi/bin
[shuidi@hadoop102 bin]$ vim xsync在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done③修改脚本xsync具有执行权限
[shuidi@hadoop102 bin]$ chmod +x xsync④测试脚本
[shuidi@hadoop102 bin]$ xsync xsync1.4、 SSH无密登录配置
(1)hadoop102上生成公钥和私钥:
[shuidi@hadoop102 .ssh]$ pwd
/home/shuidi/.ssh
[shuidi@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
[shuidi@hadoop102 .ssh]$ ssh-copy-id hadoop102
[shuidi@hadoop102 .ssh]$ ssh-copy-id hadoop103
[shuidi@hadoop102 .ssh]$ ssh-copy-id hadoop104(2)hadoop103上生成公钥和私钥:
[shuidi@hadoop103 .ssh]$ pwd
/home/shuidi/.ssh
[shuidi@hadoop103 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
[shuidi@hadoop103 .ssh]$ ssh-copy-id hadoop102
[shuidi@hadoop103 .ssh]$ ssh-copy-id hadoop103
[shuidi@hadoop103 .ssh]$ ssh-copy-id hadoop104(3)hadoop104上生成公钥和私钥:
[shuidi@hadoop104 .ssh]$ pwd
/home/shuidi/.ssh
[shuidi@hadoop104 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
[shuidi@hadoop104 .ssh]$ ssh-copy-id hadoop102
[shuidi@hadoop104 .ssh]$ ssh-copy-id hadoop103
[shuidi@hadoop104 .ssh]$ ssh-copy-id hadoop1041.5、安装JDK
环境变量配置说明
Linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/*.sh,~/.bashrc,~/.bash_profile等,下面说明上述几个文件之间的关系和区别。
bash的运行模式可分为login shell和non-login shell。
例如,我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell。而当我们执行以下命令ssh hadoop103 command,在hadoop103执行command的就是一个non-login shell。
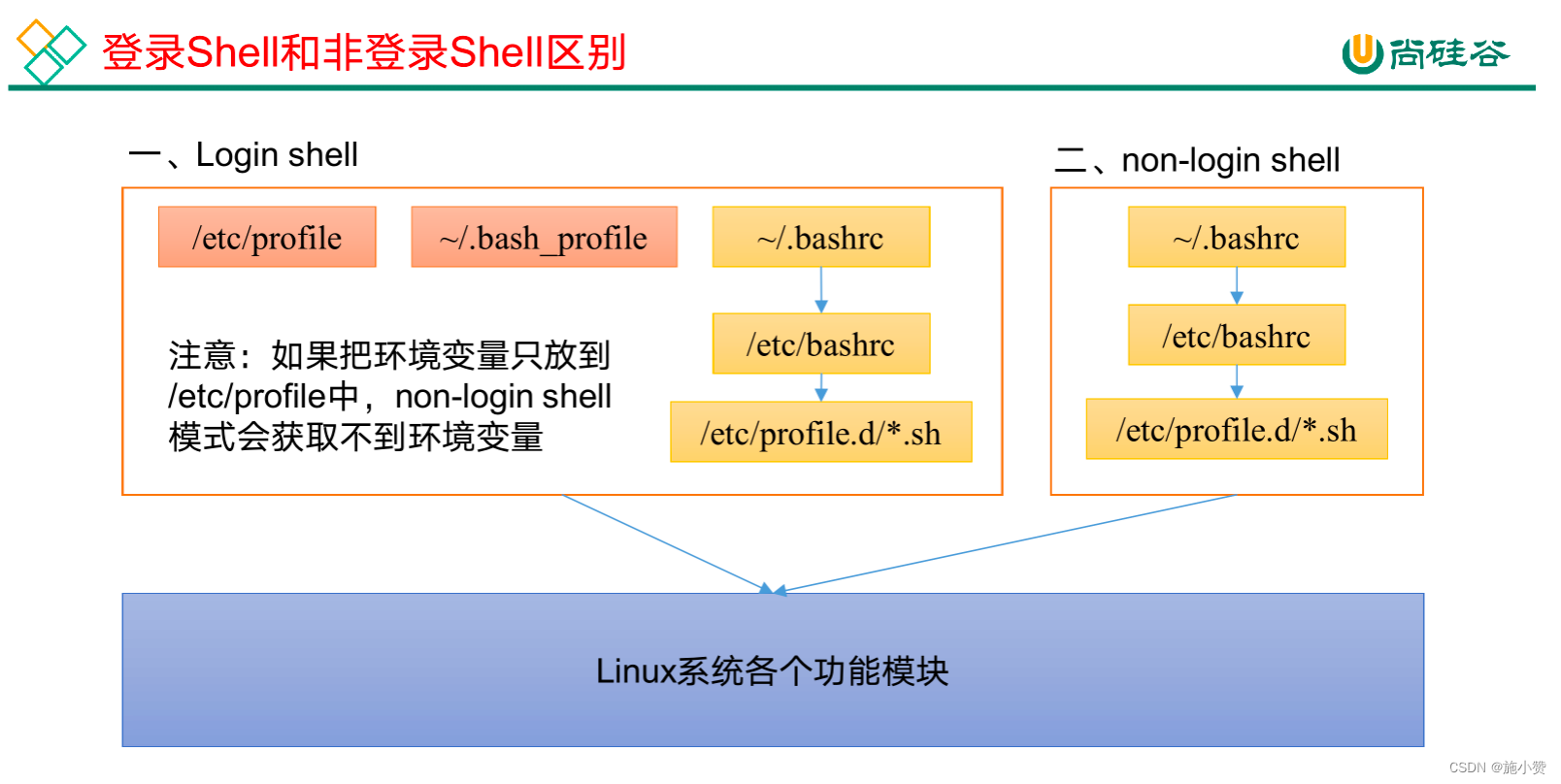
这两种shell的主要区别在于,它们启动时会加载不同的配置文件,login shell启动时会加载/etc/profile,~/.bash_profile,~/.bashrc。non-login shell启动时会加载~/.bashrc。
而在加载~/.bashrc(实际是~/.bashrc中加载的/etc/bashrc)或/etc/profile时,都会执行如下代码片段,

因此不管是login shell还是non-login shell,启动时都会加载/etc/profile.d/*.sh中的环境变量。
(1)新建/etc/profile.d/my_env.sh文件
[shuidi@hadoop102 hadoop]$ sudo vim /etc/profile.d/my_env.sh添加如下内容,然后保存(:wq)退出
#JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin(2)让环境变量生效
[shuidi@hadoop102 hadoop]$ source /etc/profile.d/my_env.sh6)测试JDK是否安装成功
[shuidi@hadoop102 hadoop]$ java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)7)分发JDK
[shuidi@hadoop102 hadoop]$ xsync /usr/local/jdk1.8.0_1918)分发环境变量配置文件
[shuidi@hadoop102 hadoop]$ sudo /home/shuidi/bin/xsync /etc/profile.d/my_env.sh9)分别在hadoop103、hadoop104上执行source
[shuidi@hadoop103 hadoop]$ source /etc/profile.d/my_env.sh
[shuidi@hadoop104 hadoop]$ source /etc/profile.d/my_env.sh2、模拟数据
2.1、使用说明
1)将application.yml、gmall2020-mock-log-2021-10-10.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
(1)创建applog路径
[shuidi@hadoop102 profile.d]$ mkdir /opt/module/applog(2)上传文件到/opt/module/applog目录
2)配置文件
(1)application.yml文件
可以根据需求生成对应日期的用户行为日志。
[shuidi@hadoop102 applog]$ vim application.yml修改如下内容
# 外部配置打开
logging.config: "./logback.xml"
#业务日期 注意:并不是Linux系统生成日志的日期,而是生成数据中的时间
mock.date: "2020-06-14"
#模拟数据发送模式
#mock.type: "http"
#mock.type: "kafka"
mock.type: "log"
#http模式下,发送的地址
mock.url: "http://hdp1/applog"
#kafka模式下,发送的地址
mock:
kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092"
kafka-topic: "ODS_BASE_LOG"
#启动次数
mock.startup.count: 200
#设备最大值
mock.max.mid: 500000
#会员最大值
mock.max.uid: 100
#商品最大值
mock.max.sku-id: 35
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 10
#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#购物券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"(2)path.json,该文件用来配置访问路径
根据需求,可以灵活配置用户点击路径。
[
{"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20 },
{"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":40 },
{"path":["home","mine","orders_unpaid","trade","payment"],"rate":10 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","trade","payment"],"rate":5 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","home"],"rate":5 },
{"path":["home","good_detail"],"rate":10 },
{"path":["home" ],"rate":10 }
](3)logback配置文件
可配置日志生成路径,修改内容如下
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.atgugu.gmall2020.mock.log.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" >
<appender-ref ref="console" />
</root>
</configuration>3)生成日志
(1)进入到/opt/module/applog路径,执行以下命令
[shuidi@hadoop102 applog]$ java -jar gmall2020-mock-log-2021-10-10.jar(2)在/opt/module/applog/log目录下查看生成日志
[shuidi@hadoop102 log]$ ll
总用量 84
-rw-rw-r-- 1 shuidi shuidi 84624 6月 30 17:52 app.2023-06-30.log2.2、集群日志生成脚本
在hadoop102的/home/shuidi目录下创建bin目录,这样脚本可以在服务器的任何目录执行。
[shuidi@hadoop102 log]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/usr/local/jdk1.8.0_191/bin:/home/shuidi/.local/bin:/home/shuidi/bin(1)在/home/shuidi/bin目录下创建脚本lg.sh
[shuidi@hadoop102 bin]$ vim lg.sh(2)在脚本中编写如下内容
#!/bin/bash
for i in hadoop102 hadoop103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-10-10.jar >/dev/null 2>&1 &"
done 注:
①/opt/module/applog/为jar包及配置文件所在路径
②/dev/null代表Linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出2:输出到屏幕(即控制台) /proc/self/fd/2
(3)修改脚本执行权限
[shuidi@hadoop102 bin]$ chmod 777 lg.sh(4)将jar包及配置文件上传至hadoop103的/opt/module/applog/路径
(5)启动脚本
[shuidi@hadoop102 module]$ lg.sh
========== hadoop102 ==========
========== hadoop103 ==========(6)分别在hadoop102、hadoop103的/opt/module/applog/log目录上查看生成的数据
[shuidi@hadoop102 logs]$ ls
app.2020-06-14.log
[shuidi@hadoop103 logs]$ ls
app.2020-06-14.log3、Hadoop部署
1)集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop102 | hadoop103 | hadoop104 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
链接: https://pan.baidu.com/s/1XYEF8OAKTV5TE-if8vcpdg 提取码: pwjc
3)进入到Hadoop安装包路径下
[shuidi@hadoop102 ~]$ cd /opt/software/4)解压安装文件到/opt/module下面
[shuidi@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/5)查看是否解压成功
[shuidi@hadoop102 software]$ ls /opt/module/hadoop-3.1.3
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share6)重命名
[shuidi@hadoop102 software]$ mv /opt/module/hadoop-3.1.3 /opt/module/hadoop7)将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[shuidi@hadoop102 hadoop]$ pwd
/opt/module/hadoop(2)打开/etc/profile.d/my_env.sh文件
[shuidi@hadoop102 hadoop]$ sudo vim /etc/profile.d/my_env.sh在profile文件末尾添加hadoop路径:(shitf+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin(3)保存后退出
:wq(4)分发环境变量文件
[shuidi@hadoop102 hadoop]$ sudo /home/shuidi/bin/xsync /etc/profile.d/my_env.sh(5)source 是之生效(3台节点)
[shuidi@hadoop102 hadoop]$ source /etc/profile.d/my_env.sh
[shuidi@hadoop103 hadoop]$ source /etc/profile.d/my_env.sh
[shuidi@hadoop104 hadoop]$ source /etc/profile.d/my_env.sh4、配置集群
1)核心配置文件
配置core-site.xml
[shuidi@hadoop102 hadoop]$ cd $HADOOP_HOME/etc/hadoop
[shuidi@hadoop102 hadoop]$ vim core-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为shuidi -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>shuidi</value>
</property>
<!-- 配置该shuidi(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.shuidi.hosts</name>
<value>*</value>
</property>
<!-- 配置该shuidi(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.shuidi.groups</name>
<value>*</value>
</property>
<!-- 配置该shuidi(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.shuidi.users</name>
<value>*</value>
</property>
<!-- 默认配置下存在未授权漏洞,攻击者可以在未授权的情况下远程执行代码。需立即修复加固。禁止匿名访问,在配置文件<bin_path>/etc/hadoop/core-site.xml中增加或修改配置项:-->
<property>
<name>hadoop.http.authentication.simple.anonymous.allowed</name>
<value>false</value>
</property>
</configuration>2)HDFS配置文件
配置hdfs-site.xml
[shuidi@hadoop102 hadoop]$ vim hdfs-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>3)YARN配置文件
配置yarn-site.xml
[shuidi@hadoop102 hadoop]$ vim yarn-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn单个容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>4)MapReduce配置文件
配置mapred-site.xml
[shuidi@hadoop102 hadoop]$ vim mapred-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5)配置workers
[shuidi@hadoop102 hadoop]$ vim /opt/module/hadoop/etc/hadoop/workers在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
5、 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1)配置mapred-site.xml
[shuidi@hadoop102 hadoop]$ vim mapred-site.xml在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>6、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
1)配置yarn-site.xml
[shuidi@hadoop102 hadoop]$ vim yarn-site.xml在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>7、 分发Hadoop
[shuidi@hadoop102 hadoop]$ xsync /opt/module/hadoop/8、群起集群
1)启动集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[shuidi@hadoop102 hadoop]$ bin/hdfs namenode -format(2)启动HDFS
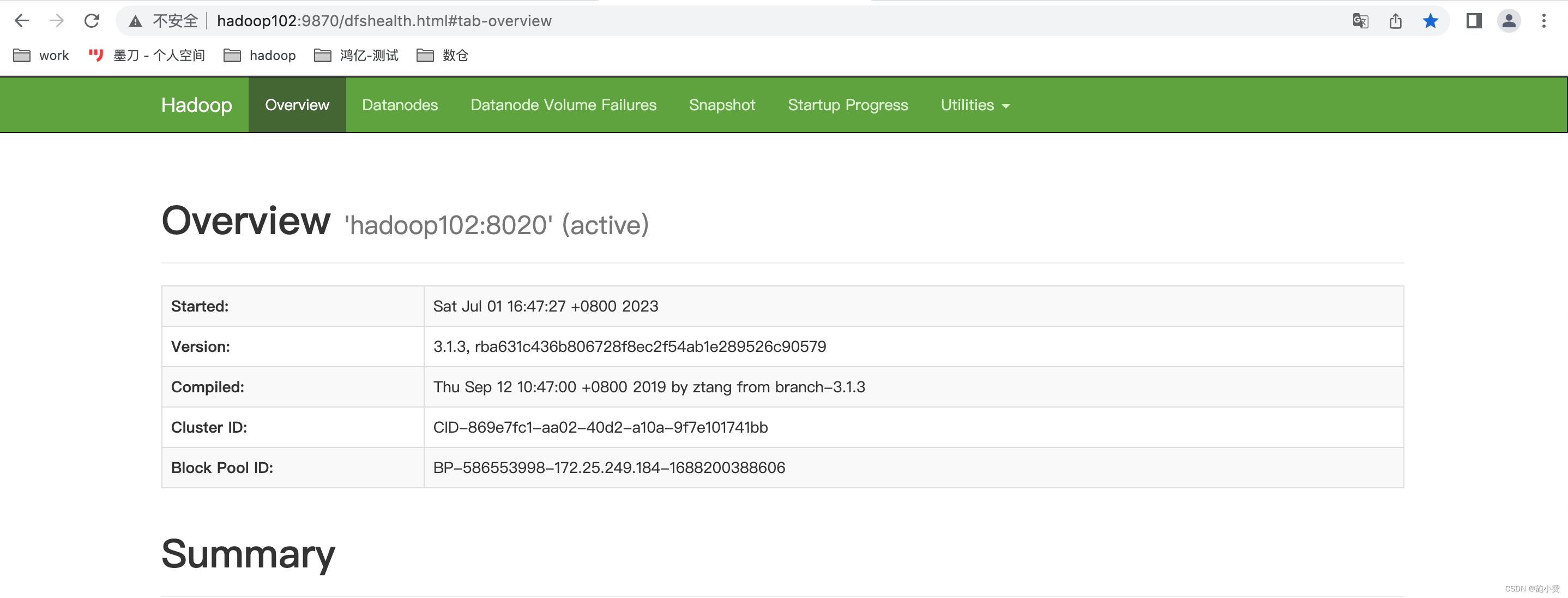
[shuidi@hadoop102 hadoop]$ sbin/start-dfs.shWeb端查看HDFS的Web页面:
http://hadoop102:9870/
(3)在配置了ResourceManager的节点(hadoop103)启动YARN
[shuidi@hadoop103 hadoop]$ sbin/start-yarn.sh
Web 端查看 YARN 的 ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看 YARN 上运行的 Job 信息
(4) 在 hadoop102 启动历史服务器
[shuidi@hadoop102 hadoop]$ mapred --daemon start historyserver查看 JobHistory http://hadoop102:19888/jobhistory
(5)Web端查看SecondaryNameNode
(a)浏览器中输入:http://hadoop104:9868/status.html
(b)查看SecondaryNameNode信息(有点问题,居然是空的)

9、Hadoop群起脚本
[shuidi@hadoop102 bin]$ pwd
/home/shuidi/bin
[shuidi@hadoop102 bin]$ vim myhadoop.sh输入如下内容:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac保存后退出,然后赋予脚本执行权限
[shuidi@hadoop102 bin]$ chmod +x myhadoop.sh10、查看三台服务器 Java 进程脚本:jpsall
[shuidi@hadoop102 bin]$ cd /home/shuidi/bin
[shuidi@hadoop102 bin]$ vim jpsall输入如下内容
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done保存后退出,然后赋予脚本执行权限
[shuidi@hadoop102 bin]$ chmod +x jpsall分发/home/shuidi/bin 目录,保证自定义脚本在三台机器上都可以使用
[shuidi@hadoop102 bin]$ xsync /home/shuidi/bin/jpsall 11、项目经验
(1)项目经验之HDFS存储多目录
①生产环境服务器磁盘情况
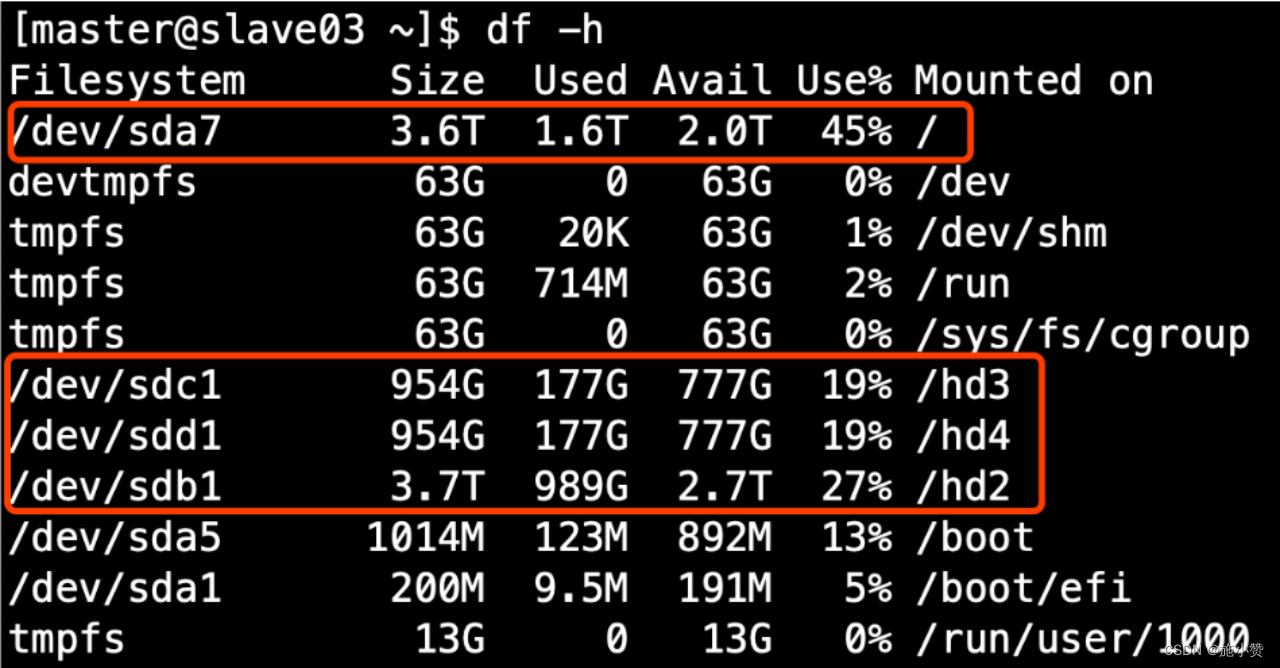
②在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
HDFS的DataNode节点保存数据的路径由dfs.datanode.data.dir参数决定,其默认值为file://${hadoop.tmp.dir}/dfs/data,若服务器有多个磁盘,必须对该参数进行修改。如服务器磁盘如上图所示,则该参数应修改为如下的值。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>注意:每台服务器挂载的磁盘不一样,所以每个节点的多目录配置可以不一致。单独配置即可。
(2)项目经验之集群数据均衡
①节点间数据均衡
开启数据均衡命令:
start-balancer.sh -threshold 10对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡命令:
stop-balancer.sh②磁盘间数据均衡
生成均衡计划(我们只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json(3)项目经验之Hadoop参数调优
1、HDFS参数调优hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>dfs.namenode.handler.count=,比如集群规模为8台时,此参数设置为41。可通过简单的python代码计算该值,代码如下。
![]()
[atguigu@hadoop102 ~]$ python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(8))
41
>>> quit()2、YARN参数调优yarn-site.xml
情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
另一个问题:
限制Hadoop RPC服务端口的访问访问控制(未实际测试)
描述
Hadoop Yarn 默认对外开放了 RPC 服务,攻击者可在未经过身份验证的情况下通过该漏洞在受影响主机执行任意命令,控制服务器。
检查提示
--
加固建议
根据官方文档开启和配置Kerberos认证,相关配置如下:在core-site.xml配置文件中配置:
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
<final>false</final>
<source>core-site.xml</source>
</property>
<property>
<name>hadoop.rpc.protection</name>
<value>authentication</value>
<final>false</final>
<source>core-default.xml</source>
</property>设置 Hadoop RPC服务所在端口仅对可信地址开放。