| 🚀 零基础入门学习Python🚀 |
🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀
🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨
🌲 作者简介:硕风和炜,CSDN-Java领域优质创作者🏆,保研|国家奖学金|高中学习JAVA|大学完善JAVA开发技术栈|面试刷题|面经八股文|经验分享|好用的网站工具分享💎💎💎
🌲 恭喜你发现一枚宝藏博主,赶快收入囊中吧🌻
🌲 人生如棋,我愿为卒,行动虽慢,可谁曾见我后退一步?🎯🎯
| 🚀 零基础入门学习Python🚀 |

🍔 目录
- 🚀 Python数据分析与可视化基础
- 🚀 使用NumPy进行数值计算和数组操作
- 🚀 使用Pandas进行数据处理和分析
- 🚀 使用Matplotlib和Seaborn进行数据可视化
- 🚀 数据分析实践案例(数据清洗、探索性分析、特征工程)
- 🚀 总结
- 💬 共勉
🚀 Python数据分析与可视化基础
随着数据的快速增长,数据分析成为了商业领域和科学领域中不可或缺的重要工具。Python作为一门功能强大的编程语言,已经被广泛应用于数据科学和数据分析。本文将介绍如何使用Python进行数据分析与可视化,包括使用NumPy进行数值计算和数组操作、使用Pandas进行数据处理和分析、使用Matplotlib和Seaborn进行数据可视化、数据分析实践案例(数据清洗、探索性分析、特征工程)、统计分析和假设检验等方面。
🚀 使用NumPy进行数值计算和数组操作
NumPy是Python的一个重要的科学计算工具包,其功能包括支持高级数值计算、数组操作等。借助NumPy,可以使得计算和科学计算在Python中变得非常方便。以下是一个NumPy的基础示例:
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(a + b)
在这个例子中,我们使用NumPy创建了两个一维数组a和b,然后对它们进行了加法操作。结果是一个一维数组[5, 7, 9]。
关于NumPy更多详细的内容后续继续完善。
🚀 使用Pandas进行数据处理和分析
Pandas是Python的另一个重要的数据处理和分析工具包。借助Pandas,可以对大量的数据进行清洗、处理、分析等。以下是一个Pandas的基础示例:
import pandas as pd
data = {'weekday': ['Mon', 'Tue', 'Wed', 'Thu', 'Fri'], 'temperature': [20, 18, 23, 25, 22]}
df = pd.DataFrame(data)
print(df)
在这个例子中,我们使用Pandas创建了一个二维数据,然后利用DataFrame函数将其转化为了一个数据框。最终输出结果包含weekday和temperature两列和五条数据。
关于Pandas更多详细的内容后续继续完善。
🚀 使用Matplotlib和Seaborn进行数据可视化
Matplotlib和Seaborn都是Python中强大的数据可视化库,借助它们可以轻松地创建各种图表。以下是一个Matplotlib和Seaborn的基础示例:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
iris = pd.read_csv('iris.csv')
sns.pairplot(iris)
plt.show()
运行结果如下所示:
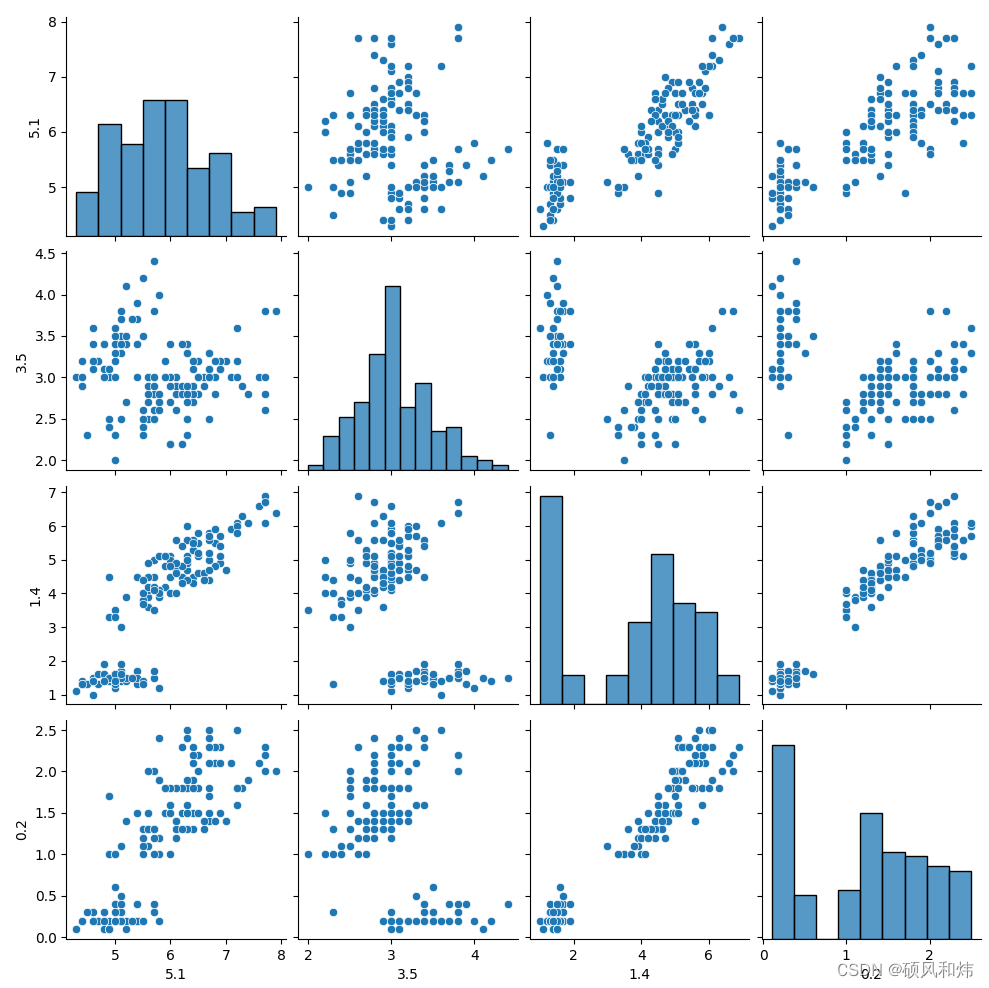
在这个例子中,我们使用Seaborn载入了一个名为iris的数据集,不同类别的点用不同的颜色和形状表示。
🚀 数据分析实践案例(数据清洗、探索性分析、特征工程)
数据分析的实践涉及到多个步骤,包括数据清洗,探索性分析和特征工程。以下是一个数据分析实践案例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
# 载入数据
data = pd.read_csv('iris.csv')
# 数据清洗
data = data.dropna()
data = data.drop_duplicates()
# 探索性分析
sns.pairplot(data)
plt.show()
# 特征工程
# data[:, :-1]和data[:, -1]。另外,如果想通过位置取数据,请使用iloc,即dataset.iloc[:, :-1]和dataset.iloc[:, -1],前者表示的# 是取所有行,但不包括最后一列的数据,结果是个DataFrame。后者则是取所有行最后一列对应的一列数据,结果是Series。
X = data.iloc[:, :-1].values
Y = data.iloc[:, -1].values
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
运行结果如下所示:
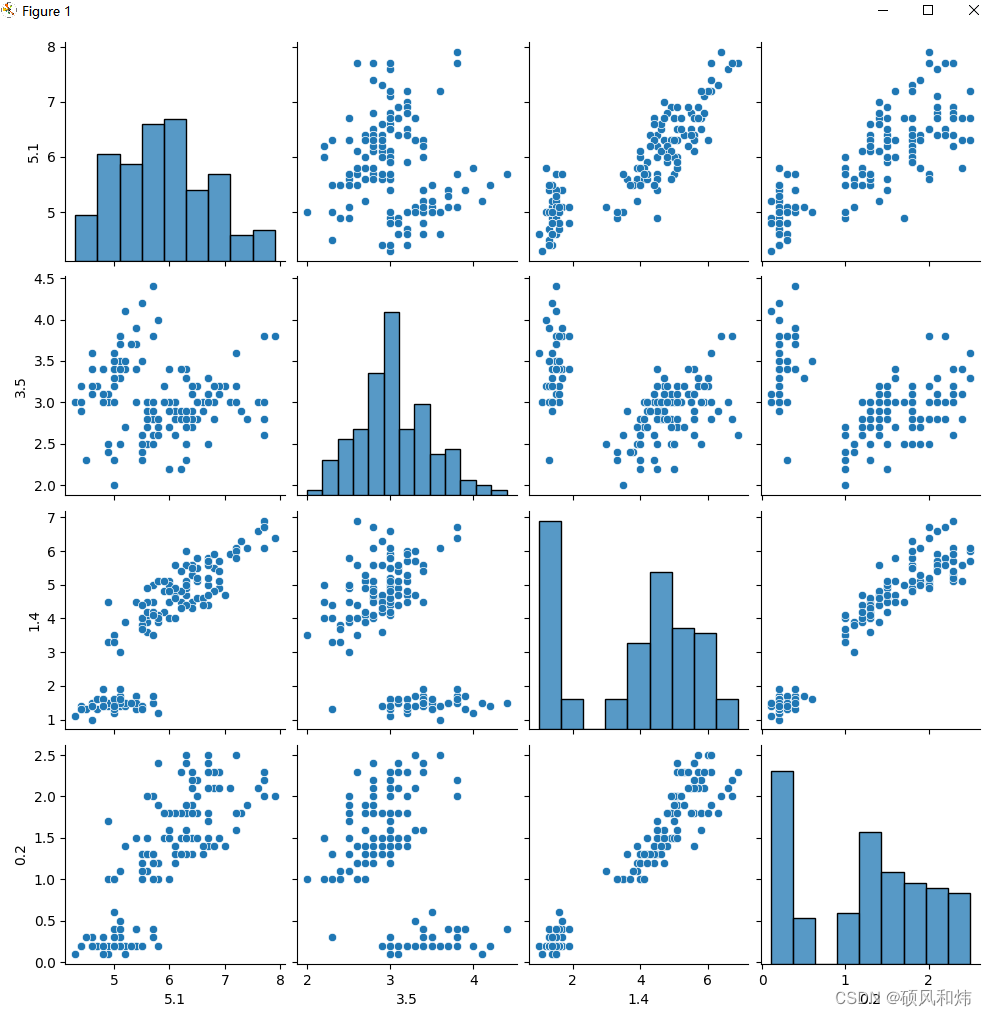
在这个实践案例中,我们首先载入了一个数据集,并对数据进行了清洗和去重。接着,我们使用Seaborn的pairplot函数绘制了数据的两两变量关系散点图。最后,我们利用Scikit-learn提供的LabelEncoder函数,将标签列转化为数字标签,以用于后续的分类模型训练和评估。
🚀 总结
本文介绍了如何使用Python进行数据分析与可视化,包括使用NumPy进行数值计算和数组操作、使用Pandas进行数据处理和分析、使用Matplotlib和Seaborn进行数据可视化、数据分析实践案例(数据清洗、探索性分析、特征工程)方面。这些工具和方法可以帮助我们从数据中提取出有意义的信息,并得到洞见,从而有效地支持决策和解决问题。
💬 共勉
| 最后,我想和大家分享一句一直激励我的座右铭,希望可以与大家共勉! |