前言:
本篇文章主要记录上周某中厂面试题的知识。该专栏比较适合刚入坑Java的小白以及准备秋招的大佬阅读。
如果文章有什么需要改进的地方欢迎大佬提出,对大佬有帮助希望可以支持下哦~
小威在此先感谢各位小伙伴儿了😁

以下正文开始
文章目录
- 实例变量是否必须赋初值,局部变量呢?
- 用过Spring和SpringMVC的哪些注解?
- Spring框架都用到了哪些设计模式?
- MySQL中的索引下推是什么
- 网页首页访问量大,如何提高响应速度
- 介绍下你知道的四大引用
- 合并二叉树(leetcode617原题)
- 其他面试问题

实例变量是否必须赋初值,局部变量呢?
在Java中,实例变量(成员变量)可以不赋初始值。如果我们没有为实例变量显式赋初值,Java会将其自动初始化为默认值。默认值取决于变量的类型。
下面这些是一些常见数据类型的默认值:
整型(byte、short、int、long):0
浮点型(float、double):0.0
字符型(char):‘\u0000’(空字符)
布尔型(boolean):false
引用类型(类、接口、数组等):null
而对于局部变量呢,局部变量在使用前必须进行初始化。否则,编译器会报错。这是Java编程语言的规定,目的是为了确保程序的安全性和可靠性。
局部变量是在方法、构造函数或代码块内部声明的变量,只能在其所在的作用域内使用。
用过Spring和SpringMVC的哪些注解?
@Component:用于将类标识为Spring容器中的组件。当类被标记为@Component后,Spring会自动扫描并将其实例化为Bean对象,方便进行依赖注入。
@Controller:用于标识控制器类,处理用户请求并返回响应。控制器类通常用于处理Spring MVC框架中的请求映射。
@Service:用于标识服务层(Service)类,通常用于业务逻辑的处理。被标记为@Service的类在Spring中被视为一个服务组件,可被自动装配到其他组件中使用。
@Repository:用于标识数据访问层(Repository)类,通常用于数据库操作。被标记为@Repository的类可以享受Spring提供的异常转换等特性。
@Autowired:用于自动装配依赖项。当一个类中需要引用其他组件时,可以使用@Autowired注解,Spring会根据类型自动注入相应的实例。
@RequestMapping:用于映射请求URL和处理方法。通过指定URL路径和HTTP请求方法,可以将请求映射到对应的方法上进行处理。
@PathVariable:用于获取URL路径中的变量值,并绑定到方法的参数上。
@RequestParam:用于获取请求参数的值,并绑定到方法的参数上。
@ResponseBody:用于将方法的返回值直接作为响应体返回给客户端,而不是返回一个视图。
@Transactional:用于标识事务处理方法。被标记为@Transactional的方法将在执行期间启动事务,并在方法结束时进行提交或回滚。

Spring框架都用到了哪些设计模式?
设计模式这块知识在前面专栏出过文章,大佬哪些设计模式忘记了可以自行查看哈~~~
Spring框架用到的设计模式有:
-
工厂模式(Factory Pattern):Spring 中的 BeanFactory 和 ApplicationContext 都是工厂模式的实现,它们负责创建和管理应用程序中的 Bean 对象。
-
单例模式(Singleton Pattern):Spring 中的 Bean 默认是单例模式的,意味着在整个应用程序中只存在一个实例对象。在 Spring 中,可以通过配置文件来设定 Bean 的作用范围,从而实现多例模式。
-
适配器模式(Adapter Pattern):Spring 中的 MVC 设计模式就是采用适配器模式实现的,它允许开发者定义自己的控制器并将这些控制器与框架集成起来。
-
代理模式(Proxy Pattern):Spring 中的 AOP 就是基于代理模式实现的。AOP 可以通过代理模式将 Cross-cutting concerns(如日志记录、安全性、性能检测等)与业务逻辑分离,并将其应用到多个应用程序组件中。
-
模板方法模式(Template Method Pattern):Spring 中的 JdbcTemplate 就是采用模板方法模式实现的,它把一些公共的操作过程(如连接数据库、关闭资源等)封装在一个抽象父类中,子类继承这个抽象类并实现自己的业务逻辑。
-
观察者模式(Observer Pattern):Spring 中的事件监听机制就是基于观察者模式实现的,通过在事件发布者和事件监听者之间建立一种松耦合的关系,将应用程序的不同部分解耦开来,从而提高了应用程序的可维护性和扩展性。
MySQL中的索引下推是什么
索引下推(Index Condition Pushdown)是MySQL数据库中的一个优化技术,旨在减少不必要的数据读取和过滤操作,提高查询性能。
从工作原理方面分析:
通常情况下,当执行SELECT语句时,MySQL首先会根据WHERE子句中的条件使用索引快速定位到匹配的行。然后,对于每一行,MySQL会检查额外的过滤条件以确定是否将该行包含在结果集中。这个过程称为"回表",因为它需要访问主要存储引擎中的实际数据行。
索引下推通过将部分WHERE子句的条件下推到存储引擎层级实现了优化。具体来说,当MySQL发现某些条件可以在索引上进行求值时,它会将这些条件下推到存储引擎层级,减少了回表操作的次数。这意味着,在索引上就可以过滤掉不满足条件的行,从而减少了处理的数据量和磁盘I/O操作。
索引下推的优点:
- 减少回表次数:索引下推可以避免不必要的回表操作,减少了数据的读取和过滤操作,显著提高了查询性能。
- 减少磁盘I/O:由于减少了回表操作,索引下推可以减少对磁盘的访问次数,从而降低了I/O负载。
- 降低存储引擎开销:通过将部分过滤条件下推到存储引擎层级,索引下推减轻了存储引擎的负担,提高了整体性能。
使用索引下推的条件:
要使用索引下推,需要满足以下条件:
- MySQL版本必须是5.6.5或更高。
- 表必须使用InnoDB存储引擎。
- 查询中的WHERE子句必须包含一个索引列,并且限制条件必须使用等于操作符(例如=、IN)或范围操作符(例如BETWEEN、<、>)。

网页首页访问量大,如何提高响应速度
这点当时回答的不是很全面,提高相应速度,方法有很多,在此总结下:
要提高网页首页的响应速度,可以考虑以下几个方面:
-
优化网页代码:删除无用的代码和文件、缩小图片和视频文件的大小、使用压缩技术等,以减少网页的加载时间。
-
部署CDN加速服务:通过将网页内容存储到多个地理位置的服务器中,大大提高用户访问时的响应速度。
-
使用浏览器缓存机制:设置合适的HTTP头信息,控制浏览器缓存,减少客户端请求的次数。
-
压缩HTTP请求:将多个HTTP请求合并为一个,减少请求次数和响应时间。
-
使用高效的Web服务器:选择高效稳定的Web服务器,如Nginx、Apache等,以提高响应速度和并发能力。
-
减少DNS查找时间:减少DNS解析时间,可以将DNS记录缓存到本地或者使用CDN服务商提供的DNS解析服务。
-
使用HTTP/2协议:HTTP/2协议支持多路复用和头部压缩等技术,可以减少网络延迟和带宽消耗,提高页面加载速度。
介绍下你知道的四大引用
我:Java中有四种不同的引用类型,包括强引用、软引用、弱引用和虚引用。
强引用是指在程序中正常使用的对象引用,只要强引用存在,垃圾回收器就不会回收该对象。比如我们写代码时自己new的对象引用:
Object obj = new Object(); //obj为强引用
软引用是在内存不足时才会被回收的引用类型,在内存充足时与强引用没有区别。当垃圾回收器准备回收某个软引用对象时,会先检查内存状态,如果内存充足则不会回收,反之则会回收该对象。下面是软引用:
SoftReference<Object> softRef = new SoftReference<>(new Object()); //softRef为软引用
Object obj = softRef.get(); //obj获取软引用所指向的对象
弱引用也是一种比较灵活的引用类型,它比软引用还要更加弱化。当垃圾回收器扫描到某个弱引用对象时,不管内存是否充足,都会立即回收该对象。如下是弱引用:
WeakReference<Object> weakRef = new WeakReference<>(new Object()); //weakRef为弱引用
Object obj = weakRef.get(); //obj获取弱引用所指向的对象
虚引用是所有引用类型中最弱的一种引用,它唯一的作用就是在对象被回收时收到系统通知。虚引用无法通过get()方法获得实例对象,需要通过ReferenceQueue来判断虚引用的对象是否被回收了。下面是虚引用:
ReferenceQueue<Object> queue = new ReferenceQueue<>(); //声明一个ReferenceQueue
PhantomReference<Object> phanRef = new PhantomReference<>(new Object(), queue); //phanRef为虚引用
Object obj = phanRef.get(); //obj无法获取虚引用所指向的对象

合并二叉树(leetcode617原题)
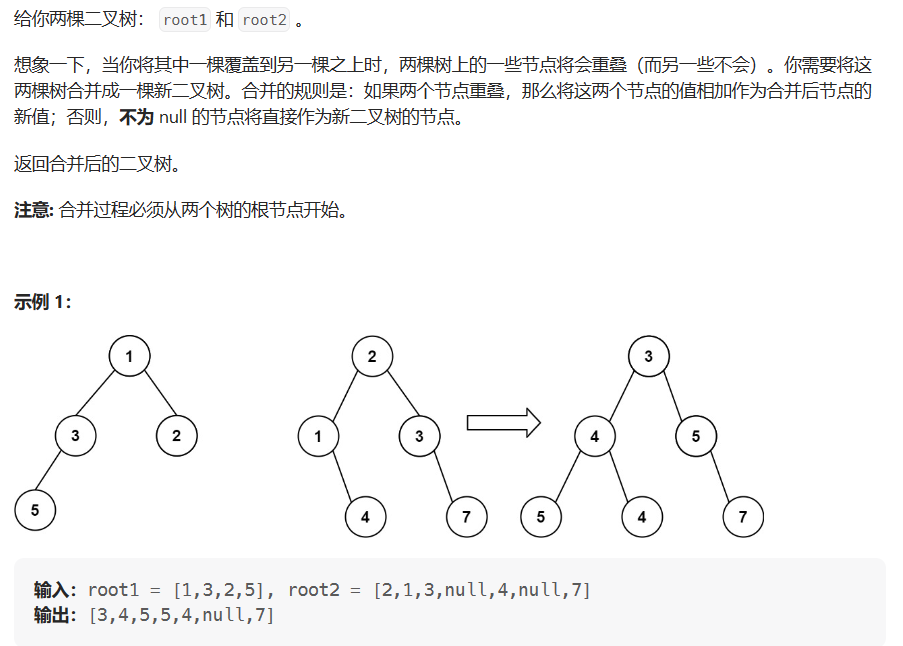
这道题目在leetcode上是道简单题,可以使用深度优先和广度优先来解答,官网讲解的也比较详细,在这里附上答案,详细讲解可参考官网:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode mergeTrees(TreeNode t1, TreeNode t2) {
if (t1 == null) {
return t2;
}
if (t2 == null) {
return t1;
}
TreeNode merged = new TreeNode(t1.val + t2.val);
merged.left = mergeTrees(t1.left, t2.left);
merged.right = mergeTrees(t1.right, t2.right);
return merged;
}
}

其他面试问题
面试还问到了计算机网络(三握四挥),Java基础相关(类加载,双亲委派,垃圾回收)的知识点,都是一些常见的面经,在以往的文章里都有记录过这些知识,在这里就不重复记录了。
文章到这里就先结束了,感兴趣的可以订阅专栏哈,后续会继续分享相关的知识点。
制作不易,感谢各位大佬的热心支持😀





![[PyTorch][chapter 44][时间序列表示方法2]](https://img-blog.csdnimg.cn/fb00d9387f6444968d0afbe5d189f85e.png)


![[golang 微服务] 9.go-micro + gorm实现商品微服务的分页查询](https://img-blog.csdnimg.cn/img_convert/6768f13e831af19415cffe60b96924c7.png)