前言
bag of words 技术里面除了上面我们讲的,还包括
word2Vec TF-IDF,Glove, co-occurrence matrix 等技术
| 论文总览 |
| 1 Abstract: 摘要 |
| 2 Introduction: 前人工作,本文目标 |
| 3 Model Architectures: LSA LDA |
| 4 New Log-Linear model |
| 5 Result |
| 6 Examples of the Learned Relationships |
| 7 Conclusion |
| 8 Follow-up work |
| 9 Conclusion |
目录:
- NLP 背景知识
- 统计语言模型
- k-gram
- 评价指标
- NN-LM
- RNN-LM
- co-occurrence matrix
一 NLP 背景知识
1.1 语言模型概念:
语言模型: 计算一组词组是句子的概率
例1: 给定词组[她,狠,漂亮]
| 句子 | 概率 |
| 她 很 漂亮 | 0.95 |
| 很 她 漂亮 | 0.01 |
| 她 漂亮 很 | 0.5 |
1.2 构建语言模型:
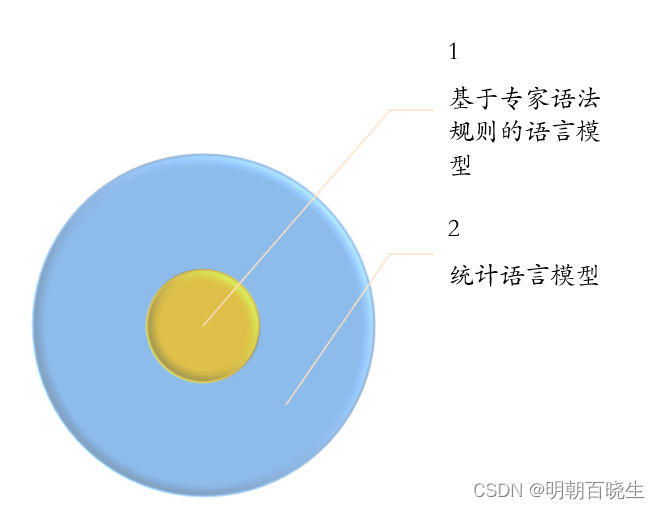
1: 基于专家语法规则的语言模型
语言学家总结出一套同样的语法规则:
缺点: 泛化性差
2: 统计语言模型
词的概率,大数定理,频率来代替概率
二 统计语言模型
2.1 背景知识
: 单词
根据 贝叶斯公式:
例:
| 概率 | 句子概率 | ||
| P(张三) | P(很|张三) | P(帅|张三,很) | P(张三,很,帅) |
| 0.9 | 0.5 | 0.001 | 0.00045 |
我们发现随着词组的增加,有些词组在语料中没有出现过,或者很少出现。但是不代表不存在
P(帅|张三,很)会出现概率接近为0的现象
解决方案:
平滑处理
2.2 平滑处理
每个词原来出现的次数+1
例: A,B,C 三个词组成的句子,原来在语料中出现的次数
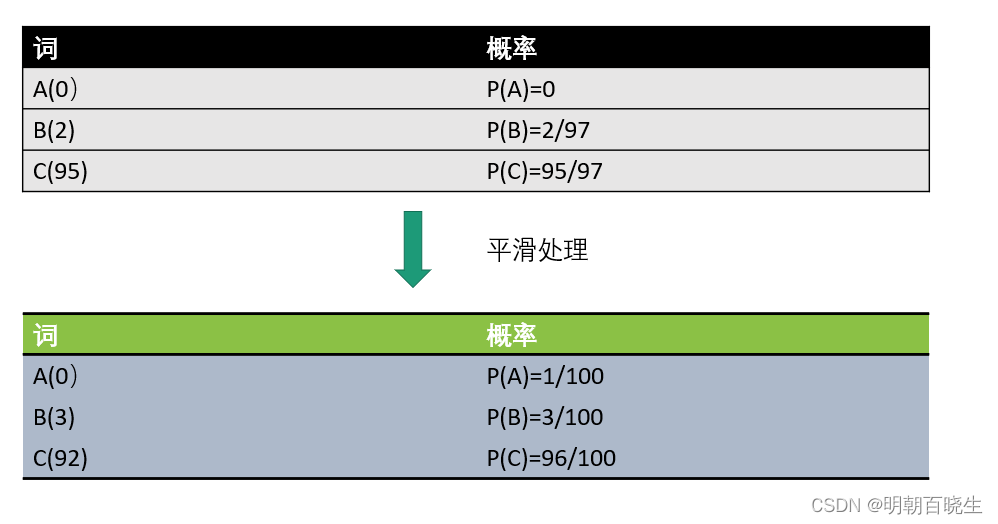
问题1: 参数空间过大
假设有3个单词,设v=3 sentence=(我,爱,你)
参数空间为3 v(w1 p(我)p(爱) p(你))
参数空间为
则 参数空间为
随着语料库的增加,该参数空间为变得极其庞大。
问题2: 数据稀疏严重
很少不为0,大部分为0
一方面浪费了空间,另一方面增加了计算量
例如
p(吃饭|张三,星期天,去了,酒店)
这个概率在语料库中可能接近为0
解决方案 k-gram
三 k-gram
这个之前讲解过,语言模型
利用马尔科夫链的原理:
| K取值 | 统计模型 |
| Uni-gram | |
| Big-gram | |
| Tri-gram | |
| K-gram | |
k 一般取1-3 ,越大计算量越大.
例
| k | P(s)= p(我,今天,打,球) |
| 1 | p(我) *p(今天)* p(打)*p(球) |
| 2 | p(我) * p(今天|我)*p(打|今天)*p(球|打) |
| 3 | p(我)*p(今天|我)*p(打|我,今天)*p(球|今天,打) |
四 评价指标
相对图像处理常用的评价指标: 准确率(Accuracy) 精确率(Precision) 召回率(Recall)
NLP 常用的评价指标为perplexity 困惑度
比如两个模型
| 模型1 | 模型2 | |
| 参数个数 | 3 | 10 |
| 概率 | 𝑝𝑠=0.7p(s)=0.7 | 𝑝𝑠=0.6p(s)=0.6 |
| 困惑度 | Pps =1.1262 | Pps =1.0524 |
看起来模型1比模型2 概率更高一点,但是 由3个单词组成,
由10个单词组成
但是通过困惑度的计算方法 困惑度更低,性能更好
五 NN-LM
Bengio大神在2003年发表的《A Neural Probabilistic Language Model》
利用n-1 词预测 第 n 个词的概率,这是一种无监督学习,不需要自己打标签
效果比较好。
5.1 模型

5.2 模型原理
输入层
1 输入 n个单词,单词用one-hot 编码,是一个[1,v]列的向量
2 随机生存一个权重系数矩阵W ,是一个[v,d]的矩阵
则 映射成了一个[1,d]的向量
3 然后把n个单词进行 concat,得到一个x=【1,n*d】的向量
隐藏层:
U 是一个[v,n*d]的矩阵,
a 是一个[v,1]的向量
输出层
是一个 【v,1】的向量
5.2 损失函数
一共有T个词,跟前面的困惑度pps 有什么关系呢?
发现损失函数 L = log (pps)
5.3 Bengio在论文的Feature Work部分提出了神经网络语言模型的可能改进方向:
a、将神经网络分解成为小的子网络,比如利用词的聚类等。
b、加速SoftMax中的正则项Z的快速求导
c、仅对一部分输出进行梯度传播。
d、引入先验知识,比如语义信息(WordNet),语法信息(low-level: POS, high level:句法结构)等。
e、词向量可解释性。
f、解决一词多义问题(Polysemous)。
-----------------------------------
Large Language Models 与神经网络 神经网络语言模型详解
https://blog.51cto.com/u_14276/6295646
六 RNN-LM
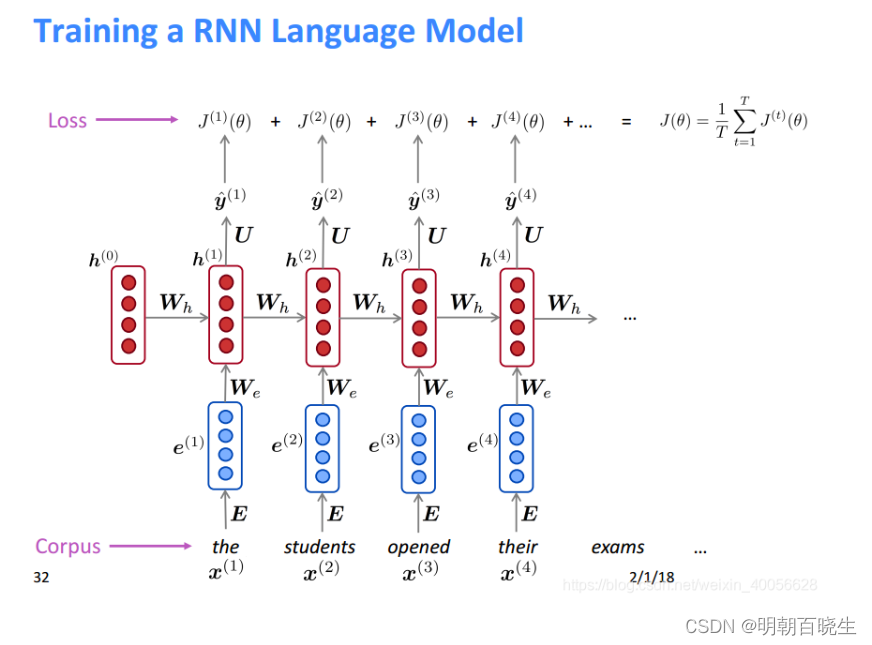
循环神经网络模型(RNN-LM)下面以一个例子:
输入
step1 : word Embedding
( E 需要训练)
step2 hiddent state
step3: output
损失函数:
【Pytorch深度学习实战】(9)神经语言模型(RNN-LM)_Sonhhxg_柒的博客-CSDN博客
七 co-occurrence matrix
比较简单,这里面我们以一个例子直接介绍
bag of words
我们认为某个词的意思跟它临近的单词是紧密相关的。这是我们可以设定一个window(大小一般是5~10)
| toy corpus(微信语料库) |
| I love china |
| I love dataScience |
如上
windows=1,与I 共现的单词 :love。
windows=2. 与I 共现的单词: love, china, dataSience。
然后我们就利用这种共现关系来生成词向量。
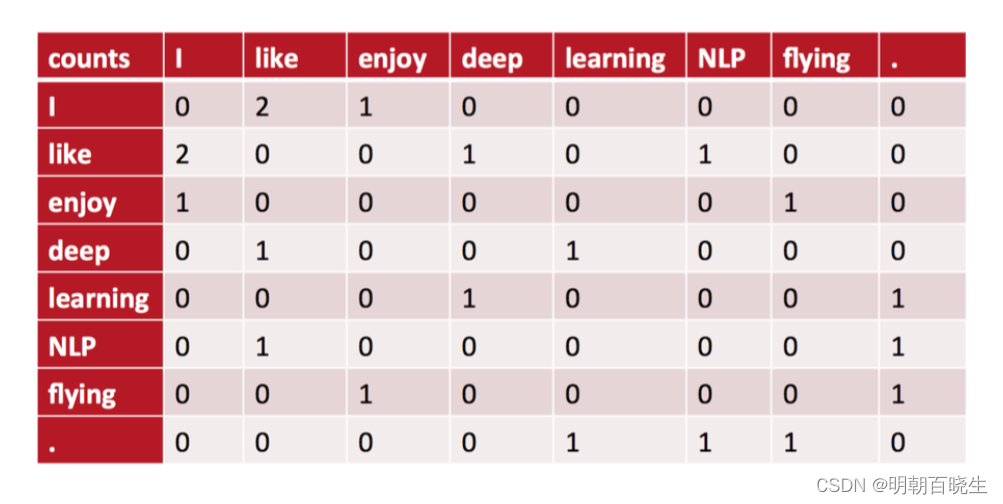
优点:
一定程度上可以反应出词的相似度。
例如 like,enjoy 都跟I 共现,二者有一定的相似度
缺点:
维度灾难,可以通过SVD 分解降维,但是可解释性降低
参考代码:
occurrence_matrix 一般在数据预处理的时候已经处理好了,
不会影响train时间,这里面只取窗口大小为1,做了一个简答的参考代码
# -*- coding: utf-8 -*-
"""
Created on Wed Jun 21 15:33:55 2023
@author: chengxf2
"""
# -*- coding: utf-8 -*-
"""
Created on Tue Jun 20 13:44:52 2023
@author: chengxf2
"""
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
import numpy as np
def gram(N=1):
'''
ngram_range=(2, 2)表明适应2-gram,
decode_error="ignore"忽略异常字符,
token_pattern按照单词切割
'''
toy_corpus =["The girl bought a chocolate",
"The boy ate the chocolate",
"The girl bought a toy",
"The girl played with a toy"]
vectorizer = CountVectorizer(ngram_range=(N, N), decode_error="ignore",min_df=0)
x_trans = vectorizer .fit_transform(toy_corpus)
print("\n get_feature_names ",vectorizer .get_feature_names())
print("\n vocabulary 词典 ",vectorizer.vocabulary_)
print("\n 每个句子中 单词出现的次数 \n",x_trans)
print("\n 是将结果转化为稀疏矩阵矩阵的表示方式 \n ",x_trans.toarray())
print(np.shape(x_trans.toarray()))
print("\n toarray \n",x_trans.toarray()) #.toarray() 是将结果转化为稀疏矩阵矩阵的表示方式;
print("\n sum \n",x_trans.toarray().sum(axis=0)) #每个词在所有文档中的词频
return vectorizer.vocabulary_, x_trans.toarray(),vectorizer .get_feature_names()
# 根据字典的值value获得该值对应的key
def get_dict_key(dic, value):
key = list(dic.keys())[list(dic.values()).index(value)]
return key
if __name__:
N =1
vocabulary,word_array,feature_names=gram(N)
input_word = 'the girl'
feature_names = vocabulary.keys()
print("\n feature_names",feature_names)
N = len(feature_names)
occurrence_matrix = np.zeros((N,N))
m,n = np.shape(word_array)
print(m,n)
windows = N
for i in range(m): #每一行的句子
for j in range(n): #代表单词的索引
if 1 == word_array[i,j]:
left = max(j-N,0)
right = min(j+N,n)
for k in range(left, right):
if k == j:
continue
if 1 == word_array[i,k]:
name = get_dict_key(vocabulary,j)
nearname = get_dict_key(vocabulary,k)
print(" i: %d j: %d %d : %s -- :%s "%(i,j,k, name,nearname))
occurrence_matrix[j,k]= occurrence_matrix[j,k]+1
print(occurrence_matrix)问题:
1 虽然Cocurrence matrix考虑了单词间相对位置的关系,但是它仍然面对维度灾难问题,也就是说一个单词的向量表示维度太大。这时,会很自然地想到SVD或者PCA等一些常用的降维方法。然而,SVD算法运算量也很大,若文本集非常多,则不具有可操作性。
2:窗口大小的选择跟N-gram中确定N也是一样的,窗口放大则矩阵的维度也会增加,所以本质上还是带有很大的计算量。
神经语言模型
【论文复现代码数据集见评论区】5小时精讲 Paper,BAT大厂导师带你吃透NLP自然语言处理的经典模型Word2vec_哔哩哔哩_bilibili
word2vec 中的数学原理详解(三)背景知识_皮果提的博客-CSDN博客
(全)Word Embedding_wordembedding_薛定谔的炼丹炉!的博客-CSDN博客word2vec 中的数学原理详解(二)预备知识_皮果提的博客-CSDN博客
论文|万物皆可Vector之语言模型:从N-Gram到NNLM、RNNLM - 知乎
论文-Recurrent neural network based language model(RNNLM) - 简书


![[golang 微服务] 9.go-micro + gorm实现商品微服务的分页查询](https://img-blog.csdnimg.cn/img_convert/6768f13e831af19415cffe60b96924c7.png)