进NLP群—>加入NLP交流群
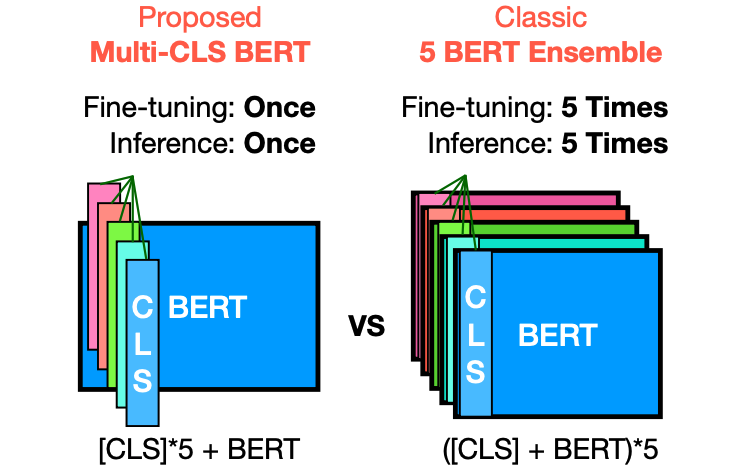
在本文中,介绍了 Multi-CLS BERT,这是传统集成方法的有效替代方案。
这种基于 CLS 的预测任务的新颖方法旨在提高准确性,同时最大限度地减少计算和内存需求。
通过利用具有不同参数化和目标的多个 CLS token,提出的方法无需微调集成中的每个 BERT 模型,从而实现更加简化和高效的流程。
在 GLUE 和 SuperGLUE 数据集上进行了实验,证明了 Multi-CLS BERT 在提高整体准确性和置信度估计方面的可靠性。它甚至能够在训练样本有限的情况下超越更大的 BERT 模型。最后还提供了 Multi-CLS BERT 的行为和特征的分析。

Multi-CLS BERT和传统集成方法不同点是?
Multi-CLS BERT与传统的集成方法不同之处在于它使用多个CLS token,并通过参数化和目标函数来鼓励它们的多样性。这样一来,就不需要对集成中的每个BERT模型进行微调,从而使整个过程更加简化和高效。相比之下,传统的集成方法需要对集成中的每个模型进行微调,并在测试时同时运行它们。Multi-CLS BERT在行为和特性上与典型的BERT 5-way集成模型非常相似,但计算和内存消耗几乎减少了4倍。
在所提出的方法中使用多个 CLS tokens有哪些优点?
在所提出的方法中,使用多个CLS token的优点在于可以鼓励它们的多样性,从而提高模型的准确性和置信度估计。相比于传统的单个CLS token,使用多个CLS token可以更好地捕捉输入文本的不同方面和特征。
此外,Multi-CLS BERT的使用还可以减少计算和内存消耗,因为它不需要对集成中的每个BERT模型进行微调,而是只需要微调单个Multi-CLS BERT模型并在测试时运行它。
GLUE 和 SuperGLUE 数据集上的实验结果
GLUE和SuperGLUE是两个广泛使用的自然语言理解基准测试数据集。
在所提出的方法中,作者使用GLUE和SuperGLUE数据集来评估Multi-CLS BERT的性能。在GLUE数据集上,作者使用100个、1,000个和完整数据集进行了实验,并在SuperGLUE数据集上使用了相同的设置。
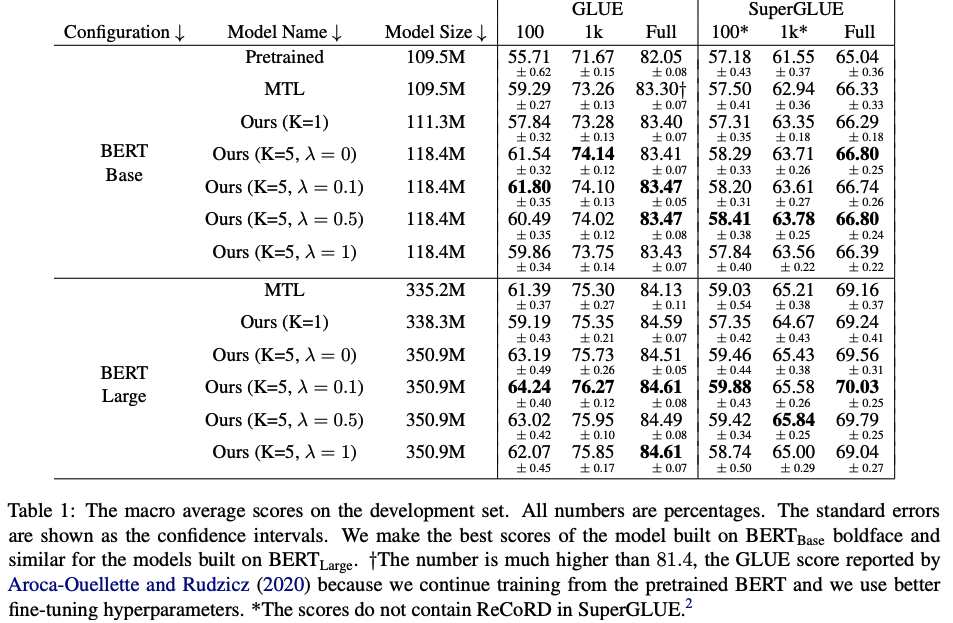
实验结果表明,Multi-CLS BERT在GLUE和SuperGLUE数据集上都能够可靠地提高整体准确性和置信度估计。在GLUE数据集中,当只有100个训练样本时,Multi-CLS BERT Base模型甚至可以胜过相应的BERT Large模型。在SuperGLUE数据集上,Multi-CLS BERT也取得了很好的表现。
总结
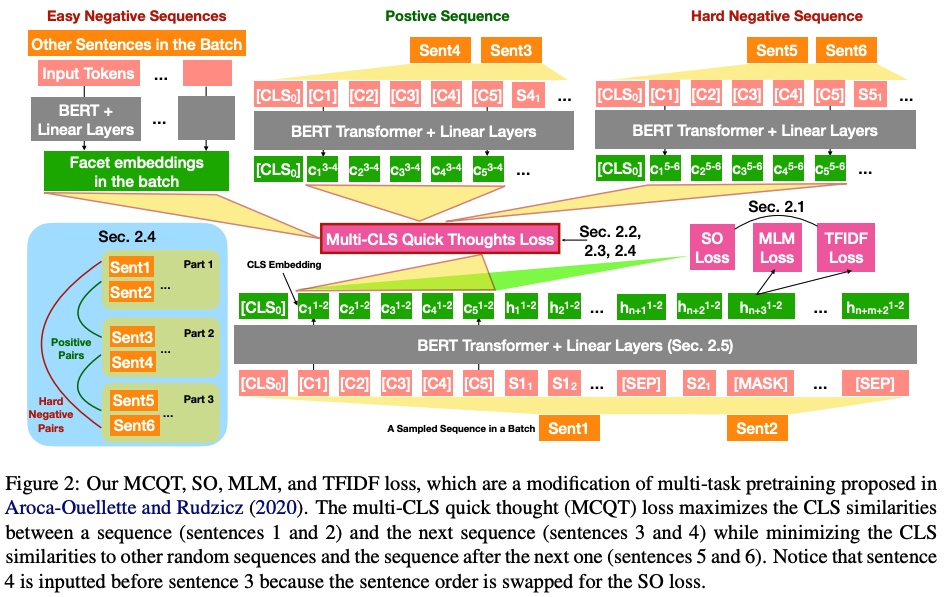
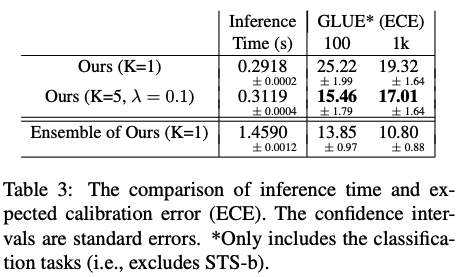
在这项工作中,作者建议使用 K 个 CLS 嵌入来表示输入文本,而不是在 BERT 中使用单个 CLS 嵌入。与 BERT 相比,Multi-CLS BERT 显着提高了 GLUE 和 SuperGLUE 分数,并减少了 GLUE 中的预期校准误差,而其唯一增加的成本是将最大文本长度减少了 K 并增加了一些额外的时间来计算插入的线性变换。因此,建议广泛使用多个 CLS 嵌入,以获得几乎免费的性能增益。
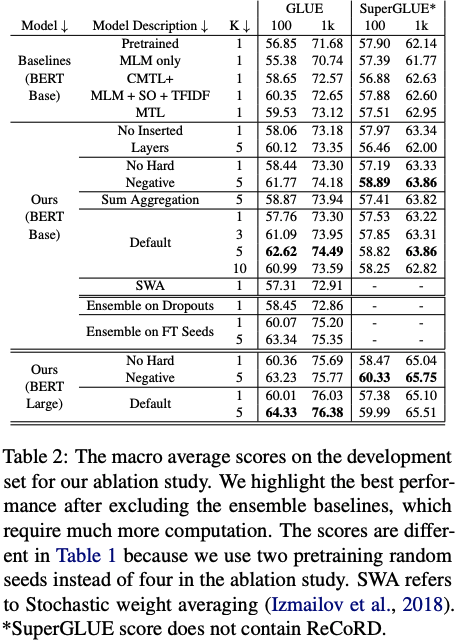
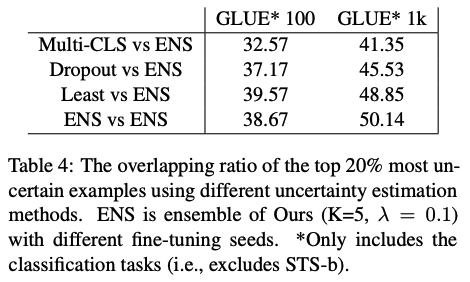
为了解决 CLS 嵌入的崩溃问题,作者修改了预训练损失、BERT 架构和微调损失。消融研究表明,所有这些修改都有助于 Multi-CLS BERT 性能的提高。在调查改进来源的分析中,发现 a) 集成原始 BERT 比集成 Multi-CLS BERT 带来更大的改进,b) 不同 CLS 嵌入的不一致与 BERT 模型的不一致高度相关不同的微调种子。这两项发现都支持作者的观点,即 Multi-CLS BERT 是一种有效的集成方法。
论文:
Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling
地址:
https://arxiv.org/abs/2210.05043
录取:
ACL2023

进NLP群—>加入NLP交流群