目录
- 1. 选用工程
- 2. 中文llama-7b预训练模型下载
- 3. 数据准备
- 4. 开始指令微调
- 5. 模型测试
前言:
- 系统:ubuntu18.04
- 显卡:GTX3090 - 24G (惨呀,上次还是A100,现在只有3090了~)
(本文旨在快速实现基于llama-7b的中文指令微调)
1. 选用工程
咱们还是用lit-llama(环境安装过程见上篇博客)
- 地址:https://github.com/Lightning-AI/lit-llama

2. 中文llama-7b预训练模型下载
-
模型下载
在huggingface上搜索"llama chinese",我们选以下这个模型,如图所示: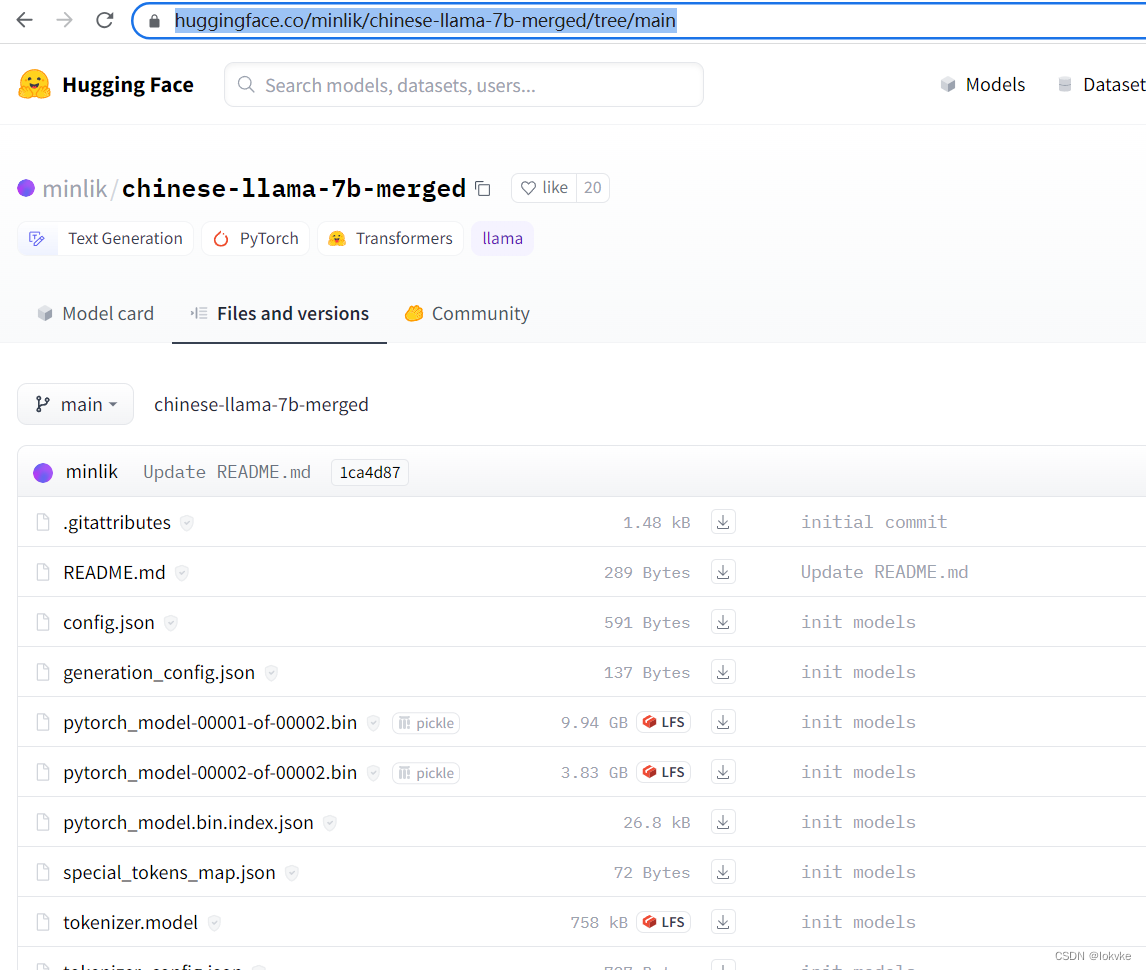
-
模型转换
切换到lit-llama的工程,修改scripts/convert_hf_checkpoint.py,修改路径,- checkpoint_dir:从huggingface下载的权重路径
- output_dir:转换之后保存的路径
如下图所示: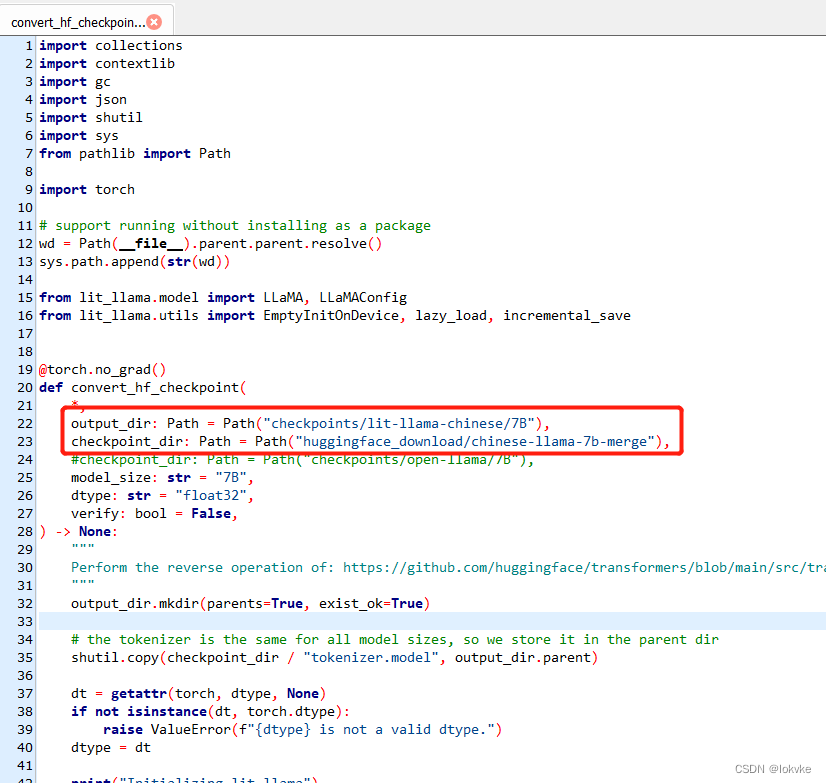
-
切换到lit-llama项目路径下,运行如下指令,进行模型转换:
python scripts/convert_hf_checkpoint.py -
转换完毕后,在刚才设置的输出路径,会得到lit-llama.pth文件(26G),在上一级目录有tokenizer.model文件

3. 数据准备
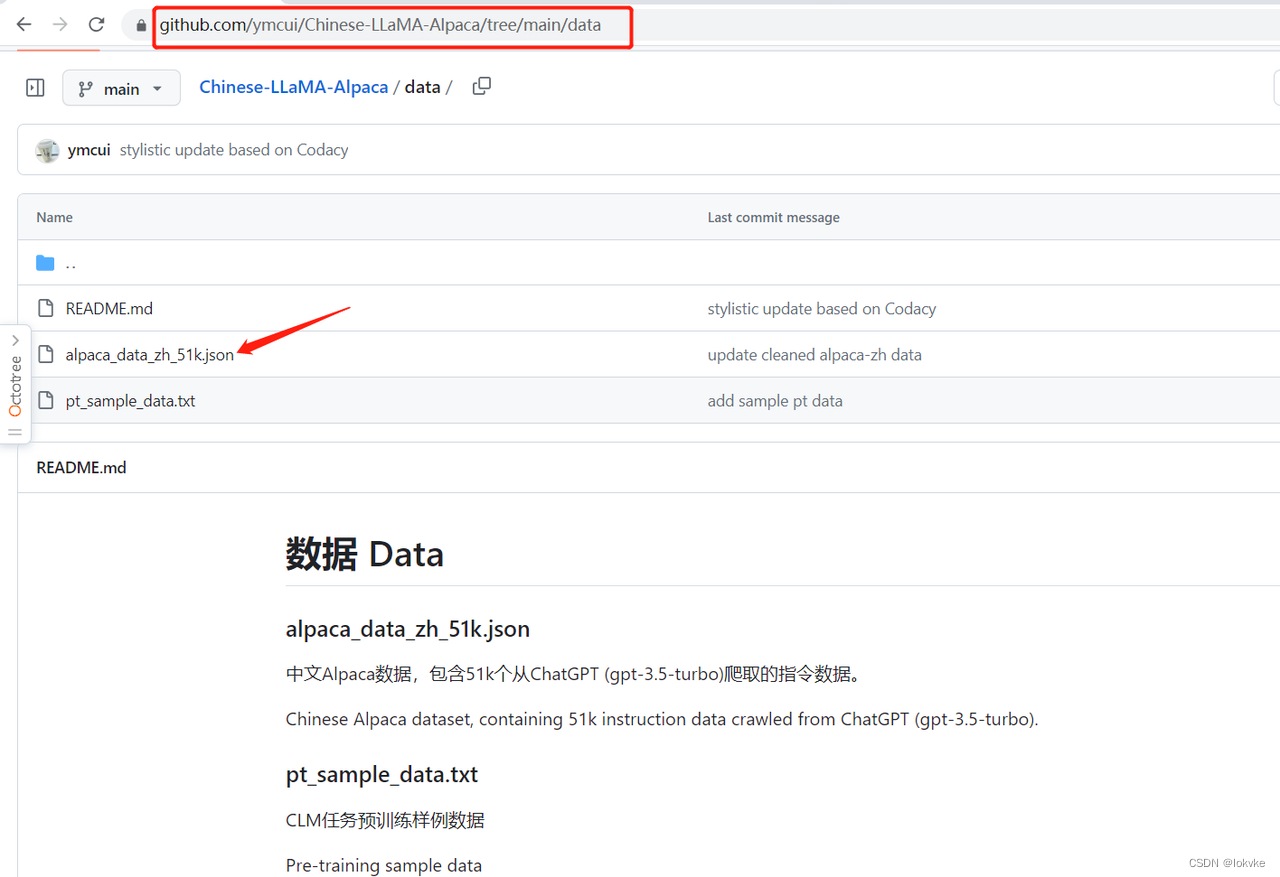
- 这里我们选用alpaca的中文指令数据alpaca_data_zh_51k.json,下载地址如下所示:
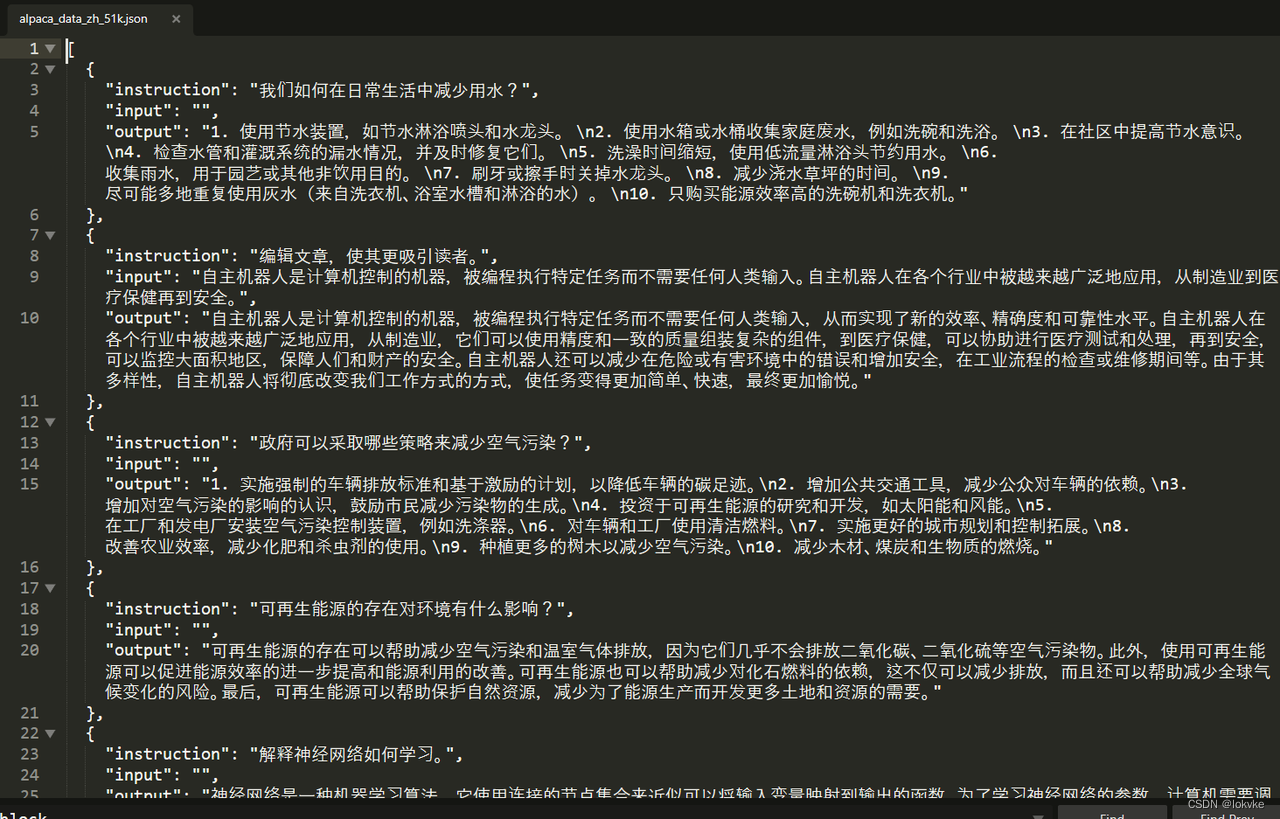
- 打开文件,指令数据如下所示:
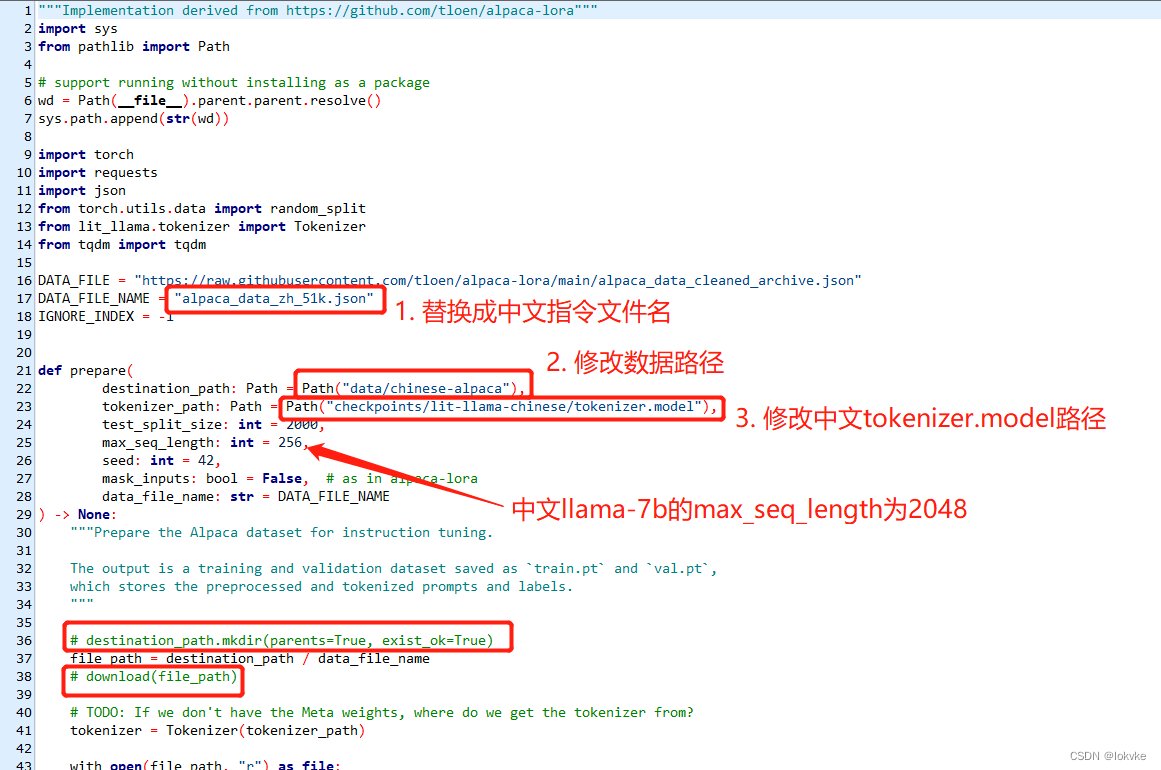
- 切换到lit-llama项目路径,打开scripts/prepare_alpaca.py(这里建议复制一份),主要修改如下图所示:
1)修改中文指令数据文件名
2)修改中文指令数据存放路径
3)修改中文llama模型的tokenizer.model路径
4)中文llama-7b的max_seq_length设置为2048,但是如果你只有一张3090显卡,设置2048会显存溢出,所以这里我们只设置256
5)因为已经下载完alpaca_data_zh_51k.json文件了,注释掉36和38行代码
- 切换到lit-llama项目路径,运行如下指令:
python scripts/prepare_alpaca.py - 运行完毕之后,会在刚才设置的destination_path下得到train.pt和test.pt的数据文件,如下图所示:
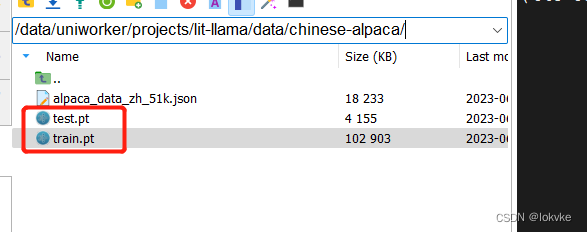
到这里,数据准备完成。
4. 开始指令微调
-
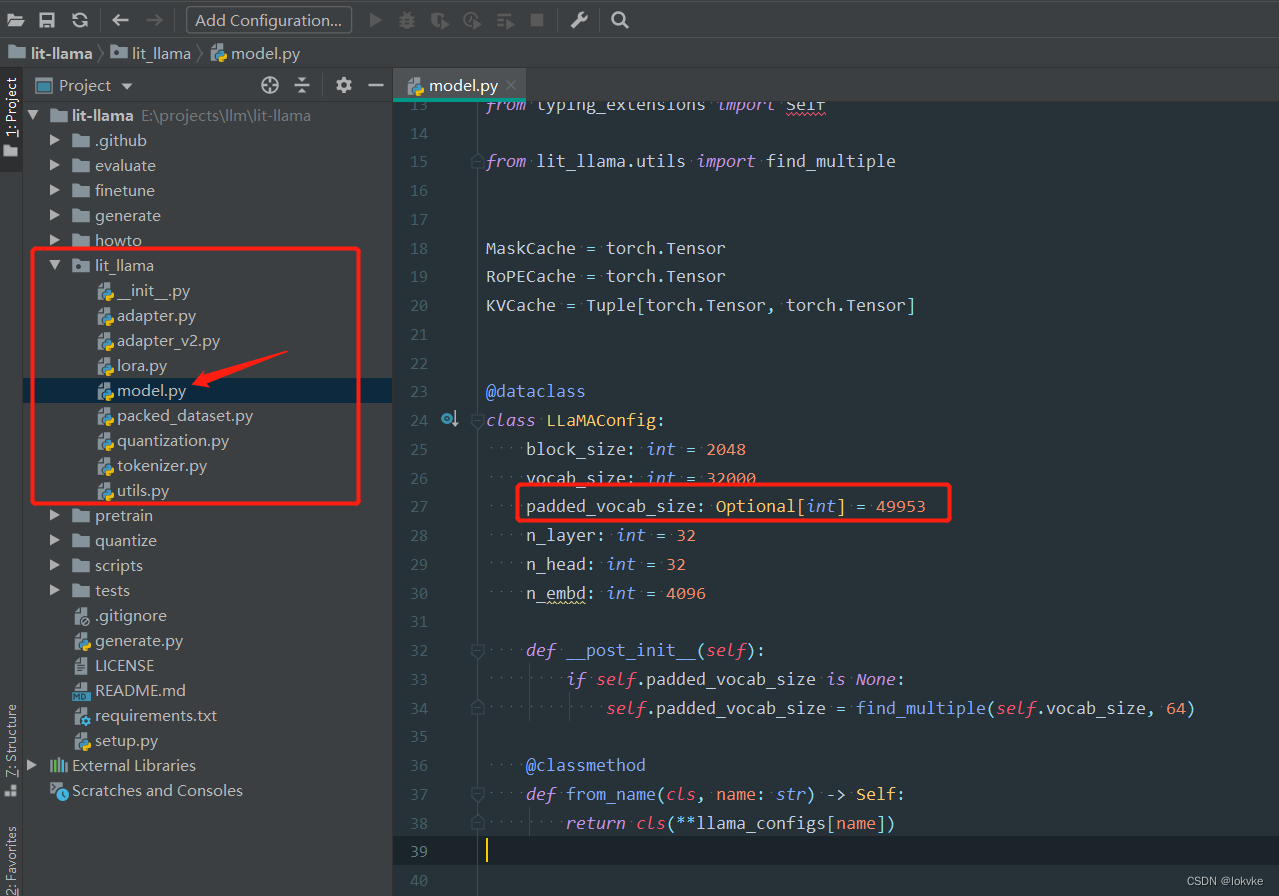
修改vocab_size
由于原始llama-7b指令的vocab_size为32000,而下载的中文llama-7b的词典大小为49953,需要对其进行修改。打开lit-llama/model.py,将padded_vocab_size设置为49953,如下图所示:
-
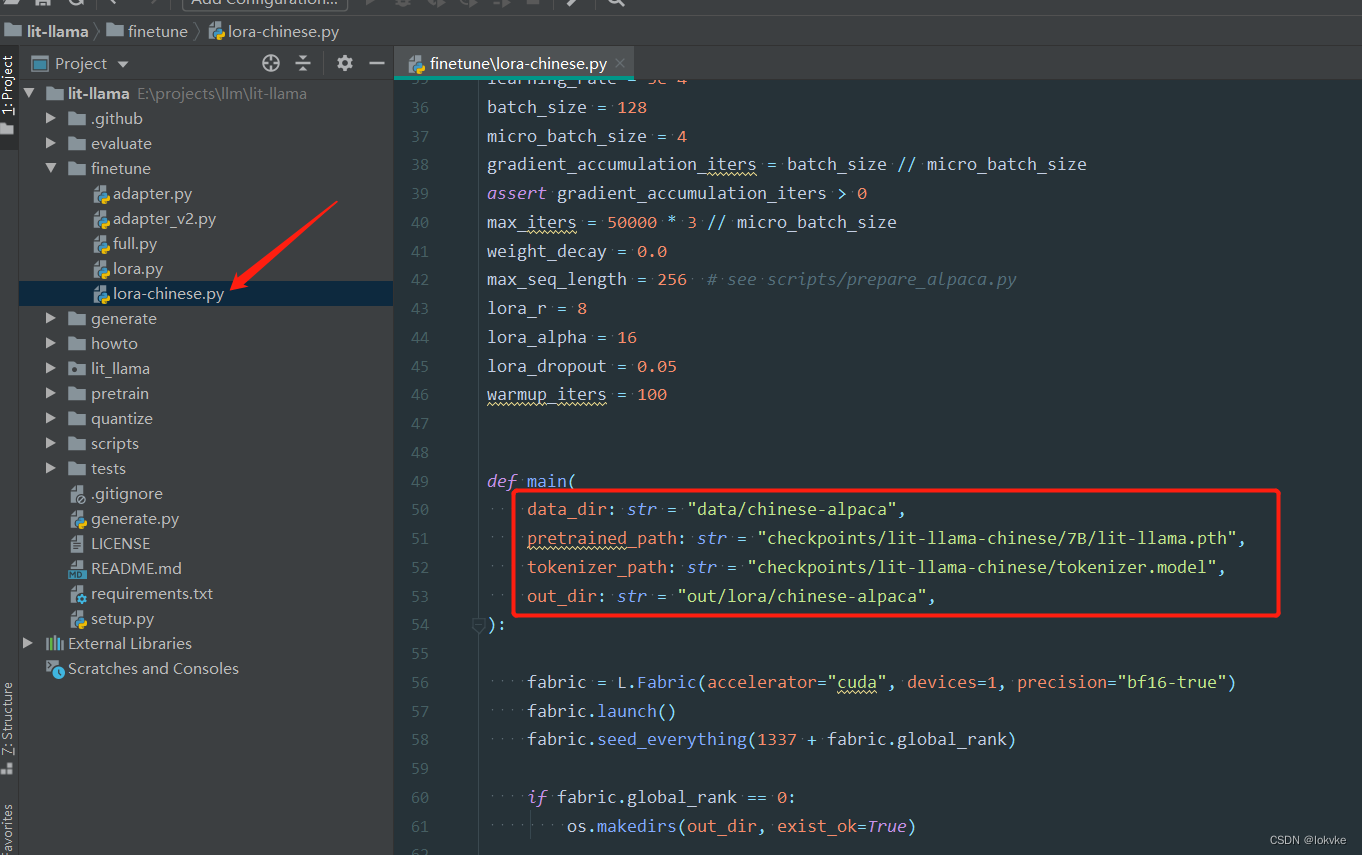
打开finetune/lora.py(建议复制一份),修改训练脚本指令路径,包括:
1)data_dir:中文指令文件路径
2)pretrained_path:转换之后的中文lit-llama.pth路径
3)tokenizer_path:中文llama-7b的tokenizer.model路径
4)out_dir:保存lora权重文件的路径
-
切换到lit-llama项目路径,运行以下指令开始指令微调:
python finetune/lora.py -
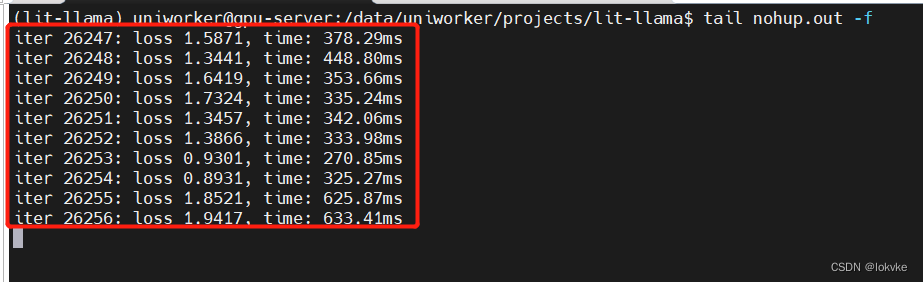
训练过程如下所示:
5. 模型测试
-
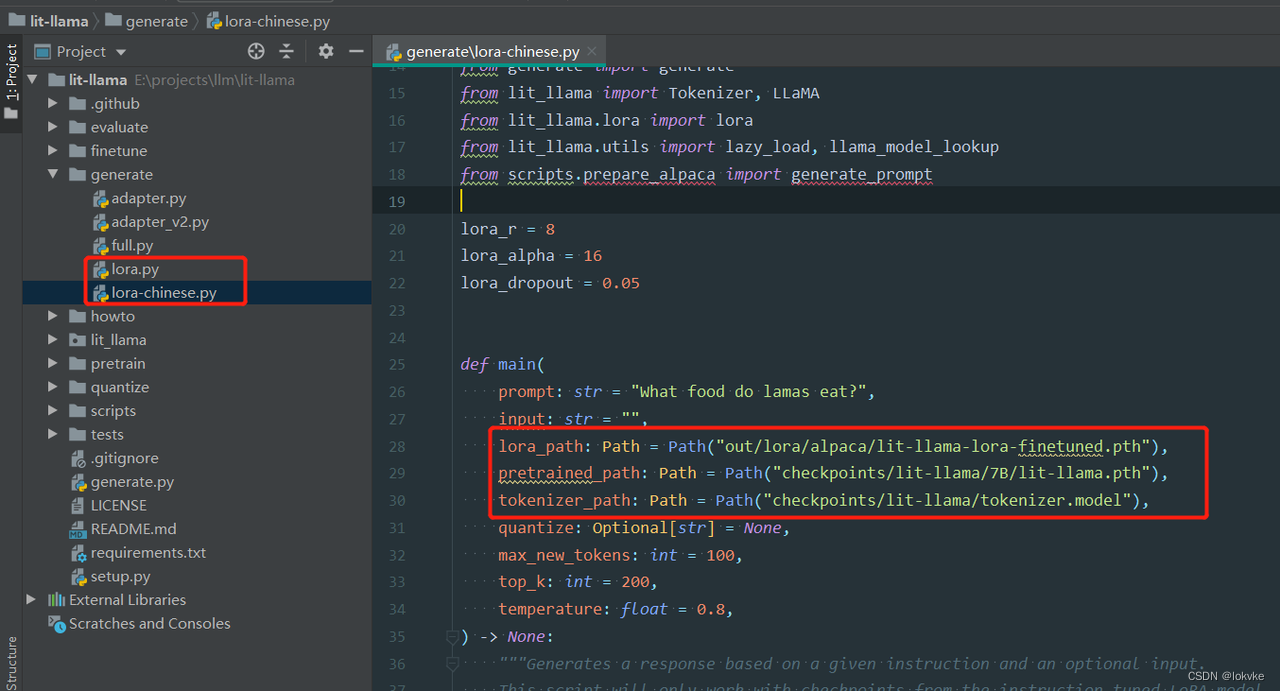
切换到lit-llama项目路径,打开generate/lora.py(建议复制一份),修改对应的权重路径和tokenizer.model路径,如下图所示:
-
我们设置prompt为"中国的首都是哪里?",运行如下指令进行测试:
python generate/lora-chinese.py --prompt "中国的首都是哪里?" -
测试结果如下所示:

总结:
- 注意替换vocab_size,原始llama-7b的词典大小为32000,下载的中文预训练模型vocab_size为49953
- 原工程中max_seq_length设置为256,下载的中文预训练模型max_seq_length为2048,但是由于受显存限制(穷~),做中文指令微调时也设置为max_seq_length=256,可能会影响效果。
- 下一步工作尝试使用多卡训练以及使用自己的数据进行指令微调
结束。