TL;DR。
简单来说,本文探讨了大模型驱动的软件工程实践标准化,以及如何将需求和设计规范化为 DSL 格式。通过这种方式,可以让 AI 更自动化、高效地编写代码。
随着大语言模型在软件开发中的应用越来越广泛,传统的软件工程实践开始被重新关注和提及。在诸如于编写清晰的文档、进行代码审查和单元测试等领域,我们可以看到 LLM(大语言模型) 能带来极多在提升。而在其它的一些领域,诸如于辅助接口设计、辅助架构设计、架构治理,我们看到人们有了越来越多的尝试。
而不论是架构设计,还是接口设计,最后还依赖于需求的表达上。而从需求到模型的标准化设计,正是经典软件工程(如 UML,即统一建模语言)等特别擅长的方式。在过去,我们对于编写详细的需求疲惫不堪,而 LLM 正好能在一定程度上帮助我们。
这是否意味着经典软件工程的复兴?又是否我们需要新一代的软件工程方式?
引子:回顾过往
你是否试过提供一个详细的需求或者 API 接口,以让 ChatGPT 绘制 PlantUML(支持 UML 实现的开源软件) 图?
引子 1:手工艺人的编程时代

我刚在学编程那会,学校用的二手计算机还是蓝底白字的 DOS。由于那时计算机很慢,脑子也不灵光,一个小小的函数,老师也会要求你先在纸和笔上写写画画,然后再输入到计算机里。上大学的时候,搞的是嵌入式开发,写个只带任务调度的 OS 都得先理论验证一波,再扔到芯片上跑跑。今天,设计个 Web 系统、框架,还都是 PoC 验证起步,写个功能都是一个测试起手。
印象中,不同层次、不同领域的实现方式里,我很少能做到设计与实现是完全一致的,所以我对于经典的软件工程方法一直都是不看好。
在 Web 应用开发上,我们一直在追求一种快速验证的方式,诸如于:
创建应用模板,及其 hello, world。
第一个单元测试的成功运行。
第一次 CI/CD 的成功验证。
第一个功能的本地桌面检查。
第一个功能的端到端交付。
产品的 MVP 上线。
在追求稳定的基础设施,诸如于运行在资源受限设备的嵌入领域里,由于用户同样在期待类似互联网的交付方式,所以也受到一系列的冲击。像过去我们认为的汽车软件,也搞起了 OTA 升级方式,以出现、也避免你在路上因操作系统升级导致抛锚。
引子 2:软件工程方法:思考 LLM + 经典软件工程设计
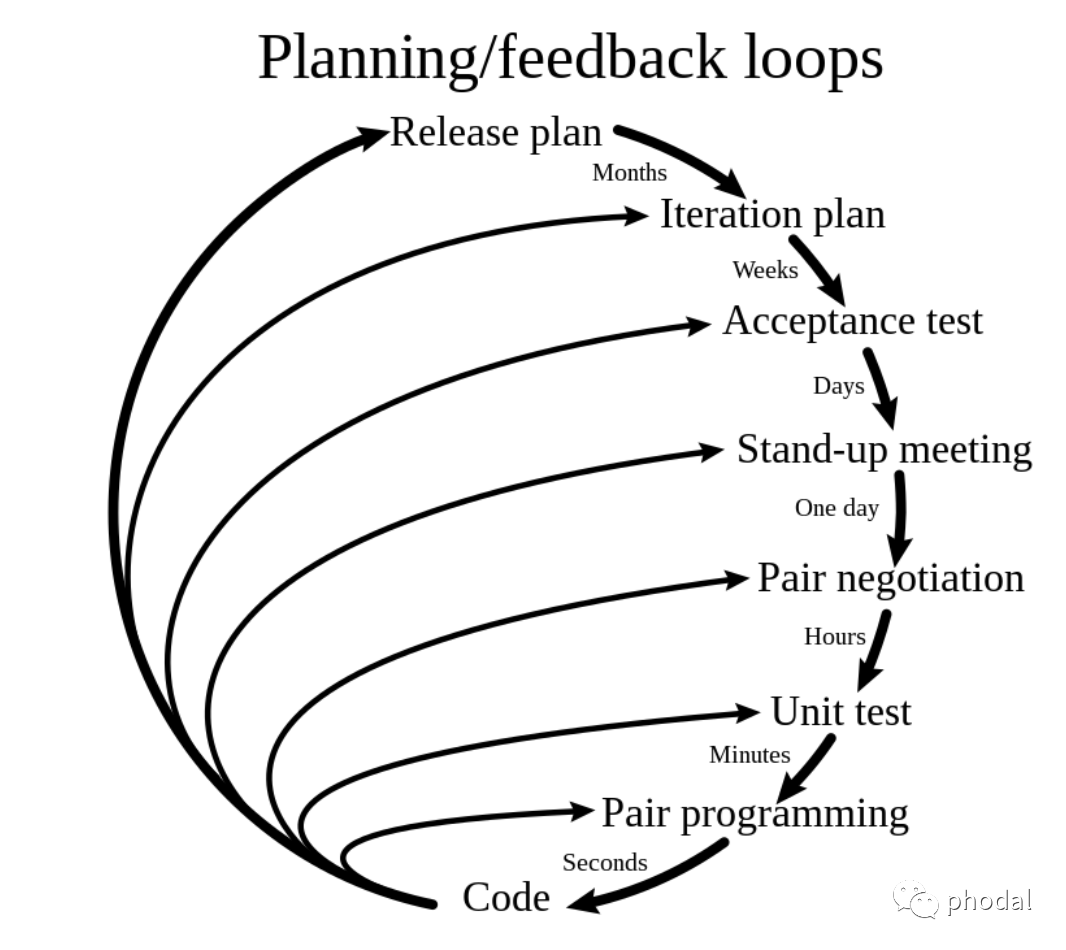
当工作以后,我开始习惯于标准的敏捷软件开发流程,它意味着在开发项目里,我需要(由 ChatGPT 生成):
确定需求:与利益相关者合作,识别和记录需求。这通常通过用户故事、用例和需求规范等方式实现。
计划和设计:确定项目的范围、时间和资源,并创建一个项目计划。在这个阶段,团队还需要设计系统的架构和技术方案。
执行迭代开发:敏捷方法采用迭代开发方式,每个迭代通常持续 1-4 周。团队根据需求和设计创建可工作的软件,并在每个迭代结束时进行演示和回顾。
持续测试和集成:在迭代和开发过程中,团队需要持续测试软件,并进行持续集成。这有助于确保软件的质量和稳定性,并减少缺陷和技术债务。
交付和部署:在每个迭代结束时,团队交付可工作的软件,并进行部署。这样,利益相关者可以尽早地了解软件的功能和特性,并提供反馈。
评估和持续改进:团队需要定期评估过程和结果,以便持续改进。这包括回顾迭代、评估团队绩效和采取行动来解决问题。
在敏捷软件开发里,我们会强调:工作的软件 高于 详尽的文档。而现在我们多了一个新的团队成员:LLM,这个新的团队成员它需要文档、详尽的文档、更种详细的文档。(PS:当然了文档的方式是多种多样的,比如代码信息也是文档的一部分。)
引子 3:LLM as Copilot

随后,我们尝试在软件开发领域引入 LLM 之后。在进行了一系列的内部头脑风暴之后,我们认为它会在不同的成熟阶段,扮演不同的角色:
阶段 一:LLM as Copilot。不改变软件工程的专业分工,但增强每个专业技术,基于AI的研发工具平台辅助工程师完成任务,影响个体工作。
阶段 二:LLM as Co-Integrator。跨研发职责及角色的协同增效,基于AI的研发工具平台解决不同的角色沟通提效,影响角色互动。
阶段 三:LLM as Co-Facilitator。影响软件研发流程的角色分工,基于AI的研发工具平台辅助决策。辅助计划、预测和协调工作,影响组织决策。
回到经典软件工程开发上,我们为什么不愿意去画 UML 图呢?一来,它只适合提供参考;二来,学习成本不低。简单来说,就是性价比太低。
而恰好 LLM 能在一定程度上解决这两个问题,LLM 可以作为一个 Copilot 解决“我懒得做”及“我重复做”的事儿,诸如于你可以让它生成 UML,虽然不是那么靠谱,但是改一改也就能用。
而在有了 “改一改就能用” 的这一基础,那么剩下的事情就变得非常简单了。
动态构建上下文:LLM + 软件工程的核心
在探索了 LLM + 软件工程的一系列实践与应用开发之后,我们着手构建 ArchGuard Co-mate 用于指导软件架构设计与软件架构治理。
位于其背后的瓶颈是:如何动态的构建软件开发所需要的上下文?
隐性知识:为什么 ChatGPT 无法生成满意的 API?
多数人或许都尝试过让 ChatGPT 生成 RESTful API,修改过一个又一个的 prompt,诸如于:
您是一个软件架构师,请生成 博客 entity 的所有 API。使用表格返回,格式:方法、路径、请求参数、返回参数、状态码。
然后,ChatGPT 就开始生成 API 了,这时候你发现了,它生成的 API 可能并不符合内部的 API 规范。于是,我们尝试和它对话去生成更准确的 API,然而,这时可能并不如你直接修改来得快。又或者,我们可以提供一个精炼的 API 规范给它,诸如于我们在 Co-mate 中所设计的:
您是一个软件架构师,请生成 博客 entity 的所有 API。要求:
1. 使用表格返回,格式:方法、路径、请求参数、返回参数、状态码。
2. 你需要参考 API 规范生成。
API 规范如下:
###
rest_api {
uri_construction {
pattern("/api\\/[a-zA-Z0-9]+\\/v[0-9]+\\/[a-zA-Z0-9\\/\\-]+")
example("/api/petstore/v1/pets/dogs")
}
http_action("GET", "POST", "PUT", "DELETE")
status_code(200, 201, 202, 204, 400, 401, 403, 404, 500, 502, 503, 504)
security(
"""
Token Based Authentication (Recommended) Ideally, microservices should be stateless so the service instances can be scaled out easily and the client requests can be routed to multiple independent service providers. A token based authentication mechanism should be used instead of session based authentication
""".trimIndent()
)
}
###然后,随着我们提供越来越多的上下文之后,ChatGPT 终于可以像你一样工作了。尽管,这时结合 ChatGPT 生成 API 的时间已经远超过我们动手去设计 API 的时间 —— 因为我们一直需要提供上下文所需要的时间,我们一直在将知识进行显性化。
LLM 就像 “新来的毕业生”:毕业生需要什么上下文?

在这时,你就会发现:“哦,LLM 就像我们团队新来的毕业生”。你需要教给他一系列的知识:
系统的功能:核心系统是做什么的?它有哪些主要的功能模块?这些模块如何为用户提供价值?
系统的优势:相比于其他同类系统,核心系统有哪些独特的优势和特点?它的性能如何?它是否提供了更好的用户体验?
系统的应用场景:核心系统适用于哪些应用场景?它可以为哪些行业或领域提供帮助?
系统的技术架构:核心系统的技术架构是怎样的?它使用了哪些技术和工具?它的可扩展性和灵活性如何?
系统的用户群体:核心系统的主要用户群体是谁?他们的需求和行为模式是怎样的?
顺便给了毕业生一堆文档,让他花两天的时间阅读。随后,你开始让他去实现某个功能,以让他去练手。最后,你发现 10 个毕业生里有 9 个写不出符合要求的代码。还有一个写得出来的是因为,他在这个团队实习过。
思考一下,我们在实现一个 API 的功能时,分别需要:
设计 API 时,需要遵循 API 规范设计的规范。
编写测试时,需要按照最佳的测试实践规范。
实现 API 代码时,需要遵循代码规范的规范。
编写提交信息时,需要遵循条件的 API 规范。
……
没错,每一小步我们都需要一个精确的 spec 才能写出符合要求的代码。而在多数的团队里,这些都是隐性的知识,又或者是由过时的文档所维护。(PS:所以,事实上,就算工作几年的团队成员,也不一定能写出符合规范的代码)
所以,我们更倡导采用结对编程的方式来分享知识,以让团队新人更快上手。
LLM 驱动的软件工程实践标准化
现在,在绕了一大圈之后,让我们回到文章的主题。我们把 LLM 看成是一个团队的新人,它需要知道团队的上下文,才能辅助我们更高效的完成工具。
在构建架构治理平台 ArchGuard 时,我们围绕三态架构(设计态、开发态、运行态)的思想所实现。对于软件来说,它也是颇为相似的,我们会基于初期的需求来设计架构,也就是设计态架构。而在实现时,是基于细化的、响应市场变化的架构,也就是开发态架构。如果想具备快速的市场响应力,我们往往会平衡花在两部分上的时间,所以往往两者不会完全一致。
实现架构之下:实现过程标准化
相信大部分人没用过 GitHub Copilot 写代码,但是大部分人都用过 ChatGPT 写代码。我想大家都会得到一个结论:当我们给定足够精确的上下文时,AI 能与出非常准确的代码,尽管还存在一定的随机性。(PS:当然,第二个结论还是先前提到的那个:如果我给了足够精准的上下文,那我早写完了。)
所以,为了让 AI 更自动化的写代码,我们就需要探索实现过程标准化,诸如于:
从需求管理系统获取需求,并进行需求分析。
结合源码与需求系统,选择最适合变更的入口(如 Java 中的 Controller)
将需求与 Controller 交给 AI 分析,以实现代码的代码。
根据 Controller 逐步自动完成其它部分代码(实现中…)
……
在当前的软件开发流程之下,我们只能让 LLM 模拟现在的流程工作。这也就是我们创建了 AutoDev 的初衷,用 ChatGPT 分解需求,将分析需求流程编写到工具中,以让 ChatGPT 去分析单个的需求,基于此来自动写代码。
而在这时,我们会发现另外一个问题:ChatGPT 缺乏一种全局观。它只拿到了单个的需求,表现得就是一个新人一样。它还需要更多的设计、规范相关的信息。
设计架构之下:规范 DSL 化
作为一个 AI + 软件工程的实践者,我并不相信文档能帮助 LLM 解决这个问题。因为文档总是落后的,缺少人维护的,而且无法自动化。
所以,我们在 Co-mate 中探索的是规范 DSL 化,即在原先 ArchGuard 规范代码化的基础上进行了二次封装。即可以让 LLM 按 DSL 来生成设计,还可以通过 DSL 来检查生成的设计是否符合规范。
诸如于在 Co-mate 的 Foundation Spec 里,我们可以用如下的方式来检查命名:
naming {
class_level {
style("CamelCase")
pattern(".*") { name shouldNotBe contains("$") }
}
function_level {
style("CamelCase")
pattern(".*") { name shouldNotBe contains("$") }
}
}而在生成代码里,也可以以此作为 LLM 的上下文提供。由于它是一个 DSL,而不是一个文档,所以可以动态地拿出作为上下文的一部分。
经典软件工程的新 DSL
在过去,我们的行业积累了一系列的 DSL,诸如于大量的 ADL(架构设计语言)、UML(统一建模语言)、BDD 语言(如 Cucumber)等等。
Cucumber 是背后的 Gherkin 是一种很有意思的 DSL,特别适合于与 LLM 结合。它也符合那篇《[语言接口:探索大模型优先架构的新一代 API 设计](https://www.phodal.com/blog/language-api-llm-first-api/)》所提及的新一代流式(Streaming) DSL 格式。如下:
Feature: OKR协作与管理
用户可以创建和管理OKR,跟踪目标和关键结果的进展。
Scenario: 创建OKR
Given 用户已登录到OKR协作与管理系统
When 用户进入系统主界面
And 用户选择创建OKR
And 用户填写目标和关键结果的详细信息
And 用户设置时间周期和权重
And 用户点击保存按钮
Then 系统应成功创建并保存OKR所以,我们可以通过上述的方式将需求格式化。
但是我们又遇到了一个问题,如何去表述更宏观的需求呢?
所以,我又从经典的工程方法里,找到了 UML。我依旧还是“相信”,很多人已经尝试过让 LLM 生成 PlantUML,以辅助进行架构设计。尽管有一定的概率生成的 UML 不生效,或者不准确,但是都觉得挺好玩的。
因为,我一直不擅长标准的 UML 写法,所以我并不看好它。而因为大部分后端开发人员都写过 Gradle 配置,所以我觉得类似于 Kotlin DSL 的方式,更方便于理解和修改:
caseflow("MovieTicketBooking", defaultRole = "User") {
// activity's should consider all user activities
activity("AccountManage") {
// task part should include all user tasks under the activity
task("UserRegistration") {
// you should list key steps in the story
story = listOf("Register with email", "Register with phone")
}
task("UserLogin") {
story += "Login to the website"
}
}
activity("MovieSelection") {}
// ...
activity("PaymentCancel") {
task("ConfirmCancel") {
role = "Admin" // if some task is role-specific, you can specify it here
//...
}
}
}我一直尝试在平衡用例与用户故事,并尝试将它们结合在一起,以为未来生成代码时,提供一种动态的上下文。
所以呢?
为了更好将 LLM 应用于软件开发过程,那么我们需要:
构建软件开发过程的标准化,以将其工具化。
将文档规范 DSL 化、代码化,动态提供,降低 AI 思考成本。
封闭经典的软件工程方式,以新瓶方式提供。
而这一些还需要相当长的时间。