参考资料:
- 《机器学习》李宏毅
1 Bert 是怎么运作的?
Bert 是一种自监督学习(Self-supervised Learning)模型。Bert 的目标是 pre-train 出一个能够理解语义的多功能语言模型,使之能够在特定任务上只学习较少的带标注样本就可以训练出一个有效的模型:

上图中,上面的黑框中,黄色的 model 里的参数就是 pre-train 得到的 Bert 参数,不同颜色的 Task Specific 是负责特定任务的参数,使用随机初始化即可;下面的黑框表示模型经过不同特定任务的样本的训练后,得到了不同的模型。换句话说,Bert 的工作就是提前初始化好模型的一部分参数(Fine-tune),并希望通过这种方式来加快模型训练和提升模型效果:


从上图可以看出,使用 Bert 的确比随机初始化模型参数在训练集上的表现要更好,甚至模型的泛化能力也更强。
2 Bert 是如何 pre-train 的?
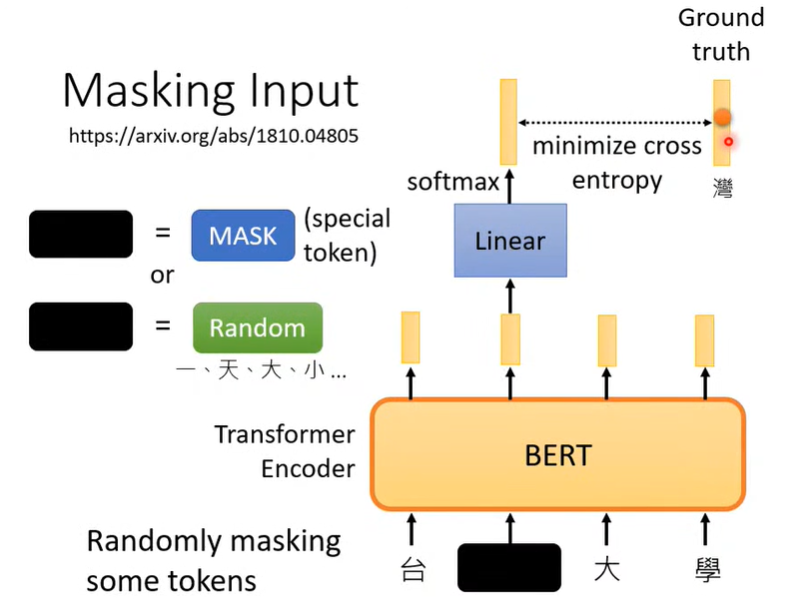
如上图所示,Bert 采用了 Transformer Encoder 的结构,在 pre-train 阶段会拿到一些被“污染”的文本资料,然后试图还原被“污染”的部分。
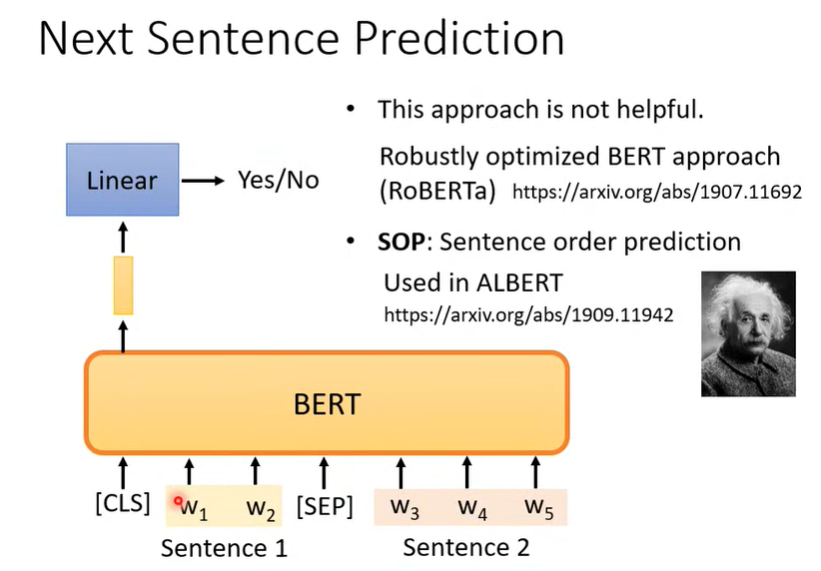
此外,Bert 在 pre-train 还会进行上下文的预测,即判断上图中的 Sentence2 是否可以接在 Sentence1 后面。Sentence1 和 Sentence 2 可以是随机选取的,也可以是颠倒次序的(通常效果更好)。
3 如何使用 Bert?
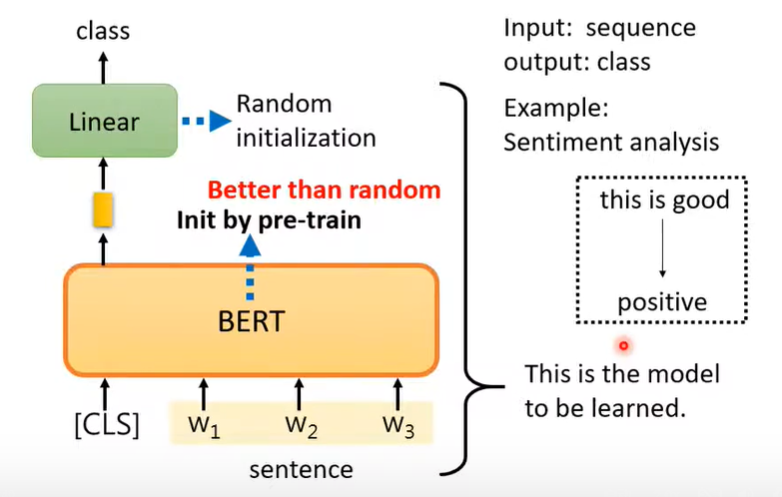
情形一:输入向量序列,输出一个向量(如情感分析)
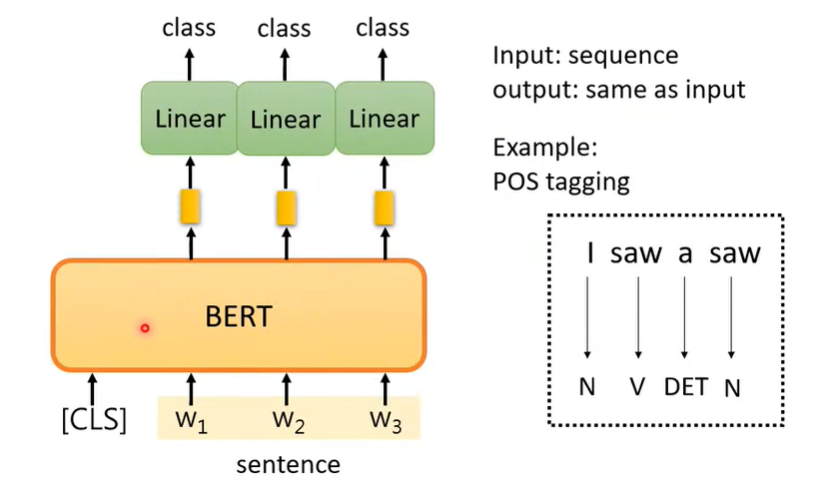
情形二:输入向量序列,输出等长的向量序列(如标注)
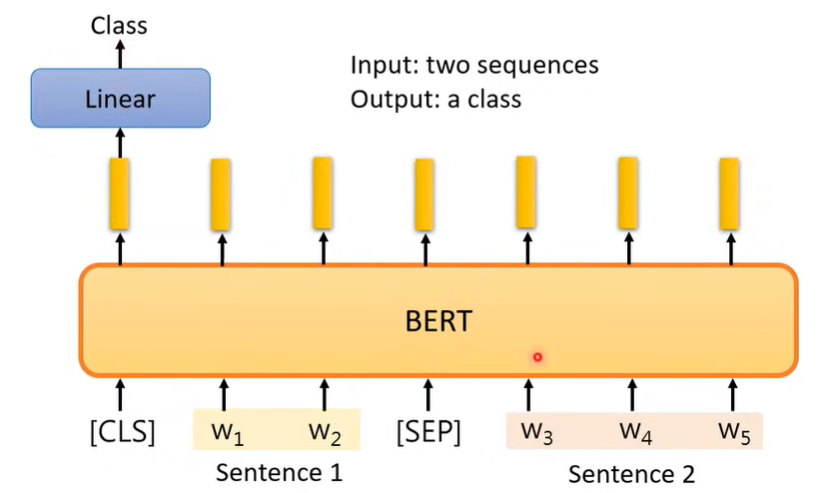
情形三:输入两个向量序列,输出一个向量(如判断两个句子是矛盾的还是不矛盾的)
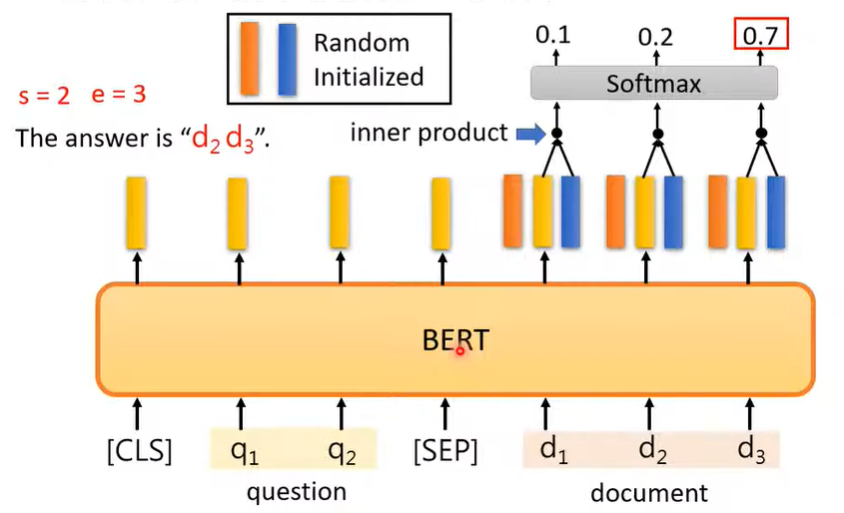
情形四:基于文章进行问答(限定答案在原文中出现且连续)