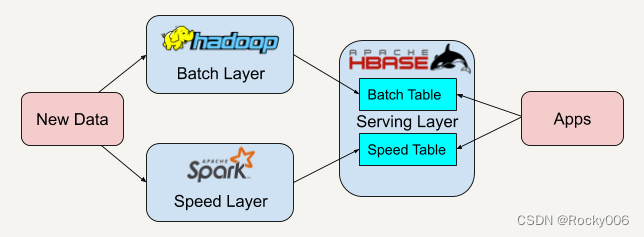
CLA简介
CLA(Control Law Accelerator),即控制律加速器,该 CLA 是完全可编程的独立 32 位浮点 CPU,专为优化数学密集型计算而设计,可显著提升控制算法的性能。与
执行指令和处理中断的标准传统处理器不同,CLA 实际上是任务驱动状态机,最多可支持 8 个用户定义的任务。
除了提供计算能力外,CLA 的独特之处还包括提供最小延迟并轻松访问主要控制外设。因此,CLA 非常适合用于
实现快速控制环路,从而释放 C28x 上的带宽以运行额外的控制环路并执行其他与诊断和通信相关的任务。
在目前数字电源的环路控制以及锁相的场景下得到非常广阔的应用。笔者目前由于在进行产品成本优化,现在以TI最新推出的280039C为例。简要说明一下CLA的工作原理以及应用说明。
CLA与外设
大多数实时控制算法用于对系统执行三个主要任务:激励、采样和控制。对系统进行激励涉及更新 PWM 寄存
器,对系统进行采样涉及访问 ADC 结果寄存器,而对系统进行控制涉及控制环路数学计算。CLA 作为独立的数学处理器,还能够访问用于控制应用的所有主要外设(如 EPWM、ADC、ECAP、EQEP、CMPSS 等)的寄存器。因此,CLA 可以执行采样和驱动以及计算控制逻辑,并且能够在没有任何 C28x 参与的情况下独立执行整个控制任务。

__attribute__((interrupt)) void Cla1Task1 ( void )
{
//
// Uncomment this to debug the CLA while connected to the debugger
//
__mdebugstop();
//
// Write to the COMPA register to realize a particular duty value
//
EPWM_setCounterCompareValue(EPWM1_BASE, EPWM_COUNTER_COMPARE_A,
(uint16_t)(duty * EPWM1_PERIOD + 0.5f));
//
// Update duty value and use the limiter
//
duty += 0.1f;
duty = (duty > 0.9f) ? 0.1f : duty;
//
// Clear EPWM4 interrupt flag so that next interrupt can come in
//
EPWM_clearEventTriggerInterruptFlag(EPWM4_BASE);
}
CLA 的低中断延迟
在任何实时控制应用中,采样到输出的延迟(定义为检测、处理和驱动之间经过的时间)是系统的一项重要考虑因素。CLA 的低延迟架构在增加总体系统吞吐量的同时减少了这个采样到输出的时间。之所以可以实现这一点,是因为 CLA 以任务为导向,而非中断驱动状态机,并且不使用中断与硬件同步。相反,该器件支持多达八个独立任务,每个任务都映射到硬件事件,例如计时器,或 ADC 上的数据可用性,等等。在 CLA 上启动的任务会在不涉及任何中断或嵌套的情况下运行至完成,因此不必考虑传统上基于中断的处理器通常涉及到的任何上下文切换开销。所以,CLA 处理数据时几乎没有延迟,最终会降低采样到输出的延迟并实现更快的系统响应。



如上图 所示,EPWM1 配置为生成频率为 1MHz 的 PWM 输出信号,该信号也用于在每个周期触发 ADC 采样。该示例还利用了 TI 的 5 类 ADC 中新增的特性,允许根据编程的 OFFSET 值将提前中断脉冲延迟几个周期。因此,ADCA 配置为对通道 0 上的输入进行采样,并在 S/H + 偏移周期结束时生成提前中断。此中断用于触发 CLA 控制任务。该 CLA 任务采用控制逻辑根据读取的 ADC 值更新 PWM 输出的占空比。提前中断特性和 CLA 的低中断延迟搭配使用,使得应用能够执行任何必要的前期工作,以便能够在 ADC 结果可用时立即对其进行处理,并且还能在下一个中断到达之前完成对 PWM 输出的更新。因此,所有三个步骤(采样、处理和驱动)都在 1MHz 周期内完成。如 CLA 任务的以下代码片段所示,为了进行说明,采用了 3 点移动平均滤波器来模拟处理序列,并且在读取 ADC 结果之前执行了少量表示为预处理代码的滤波序列步骤以便利用转换前的可用时间。
//
// Pre-processing for implementing moving average filter, takes 13 cycles
// This is just to illustrate how cycles can be utilized to do some pre-
// processing before ADC result latches.Based on the cycles taken by
// pre-processing code, ADC interrupt offset need to be programmed
//
data_read_total = data_read + data_read_prev;
data_read_prev2 = data_read_prev;
data_read_prev = data_read;
//
// Reading ADC just-in-time
//
data_read = HWREGH(ADCARESULT_BASE + ADC_RESULTx_OFFSET_BASE + ADC_SOC_NUMBER0);
//
// "data_read_total" stores the cumulative sum of current and last 2 data elements
//
data_read_total += data_read;
//
// Taking average of 3 elements, normalizing for 12-bit and mapping to output duty
// linearly in the range 0.1-0.9
// duty = 0.1 + (0.9-0.1) * ((data_read_total / 3) / 2^12 )
//
duty = 0.1f + (data_read_total / (15360.0f));
//
// Writing to the COMPA register for realizing computed duty value
//
HWREGH(EPWM1_BASE + EPWM_O_CMPA + 0x1U) = (uint16_t)(duty * EPWM1_PERIOD + 0.5f);
将快速控制环路卸载到 CLA
CLA 的独特之处包括提供最小延迟并轻松访问主要控制外设,使 CLA 能够完全从 C28x 卸载快速控制算法任务。将控制任务卸载到 CLA 还有其他好处,例如执行中的抖动降低和控制环路的确定性操作。之所以可以实现这一点,是因为 CLA 以任务为导向,而非由中断服务驱动的状态机,并且 CLA 上的任务不能被中断,从而保证了控制环路的确定性。在管线型 CPU 中,如果 CPU 在 ISR 被接收时正在执行分支类型语句,ISR 可被延迟“n”个数量周期。但是,这对于 CLA CPU 来说不是问题,因为它本质上是任务驱动的,会在空闲状态下等待,直到周期性任务触发才开始执行。因此,将快速控制任务卸载到 CLA 并在 C28x 上运行其余任务有助于提高总体系统性能,同时减少执行中的抖动。

跨 C28x/CLA 处理共享资源
使用 CLA 可以有效地从 C28x 卸载控制任务,并在C2000 器件上实现并发控制环路执行,同时具有前面几节讨论的许多其他优势。但必须注意的是,仍然会在它们之间共享外设,并且对共享寄存器进行并发读取-修改-写入操作会产生数据争用条件,最终导致数据冲突或功能不正确。理想情况下,最好避免 CLA 和 C28x 在运行时同时对同一外设进行任何更新,但如果无法避免,则必须小心处理共享资源的冲突。其中 C28x 和 CLA 以不同频率独立执行对同一 (AQCSFRC) 寄存器的并发读取-修改-写入操作,这会在 C28x 和 CLA 之间产生竞态条件,并可能导致两者其中一个引发的更新丢失或被覆盖。这是一个标准的临界区问题,可以使用互斥等软件握手机制进行处理,但大多数实时控制应用程序对时间敏感,无法承受额外的软件周期开销。此示例建议使用一种基于硬件的替代技术来巧妙地调度 CLA 和 C28x 任务,从而避免对共享资源的访问发生重叠。基于硬件的调度技术利用了 EPWM 模块的可编程相移机制。
总结
TI 的控制律加速器 (CLA) 提供的差异化特性支持在 C2000 器件上高效执行并发控制环路。CLA 经过专门设计,旨在提高实时 MCU 上的控制密集型数学例程的性能。CLA 的低延迟任务驱动架构非常独特,可降低采样到输出的延迟,这一点在控制应用中非常重要。对主要控制外设的直接访问和强大的浮点处理能力使 CLA 能够完全从主 CPU (C28x) 卸载控制任务,从而释放其带宽以执行其他系统任务。CLA 为 C2000 器件提供了额外的处理功能,并提高了器件的整体性能。本报告中讨论的用于调度 CLA 任务的相移机制可用于从器件中提取最大处理带宽。与基于硬件的控制律实现方案相比,CLA 的另一个主要优势是灵活性。CLA 是完全可编程的,开发人员可以自由修改他们的控制系统,而无需花费时间和高昂的成本重新设计基于硬件的解决方案