一、背景
必须前置知识:《Trino权威指南》第12章及周边涉及知识,基于392版本的使用层面入门书,引擎创始人亲自编写:
https://www.wisdominterface.com/wp-content/uploads/2021/07/Trino-Oreilly-Guide.pdf![]() https://www.wisdominterface.com/wp-content/uploads/2021/07/Trino-Oreilly-Guide.pdf
https://www.wisdominterface.com/wp-content/uploads/2021/07/Trino-Oreilly-Guide.pdf
或者中文翻译版《Presto实战》第12章及周边,基于330版本。
可选知识:
(1)编译原理基础(SQL语法解析token、生成AST抽象语法树、将AST生成执行计划并优化覆盖的过程,如《ANTLR4权威指南》)、《数据库系统内幕》等计算机专业通用底层课程;
(2)《Presto技术内幕》等深入底层原理的Trino源码级书籍或博客。
(3)《大数据技术体系详解:原理、架构与实践》等大数据平台全貌入门书。
二、查看SQL性能瓶颈的方法
执行如下SQL:
explain analyze 要分析的SQL;完成之后会生成详细的执行计划,执行计划本身是从底部往上倒着看的,可以全部复制下来到sublime text等文本编辑器后,ctrl+f搜索百分号“%”,来查看具体是什么操作的cpu time、schedule time、block time等百分比占据了整个查询的大部分。例如如下的执行计划,可以看到大部分的开销百分比在于kudu表扫描的调度上,有可能会成为查询任务的瓶颈之一:

同时如果能找到当时问题查询的query id,则可以在Trino原生UI中搜索对应的查询历史记录,注意有的query id搜不到可能是过期或者coordinator重启过了,因为目前社区版的查询历史记录都存在coordinator内存中,过段时间会被刷掉:
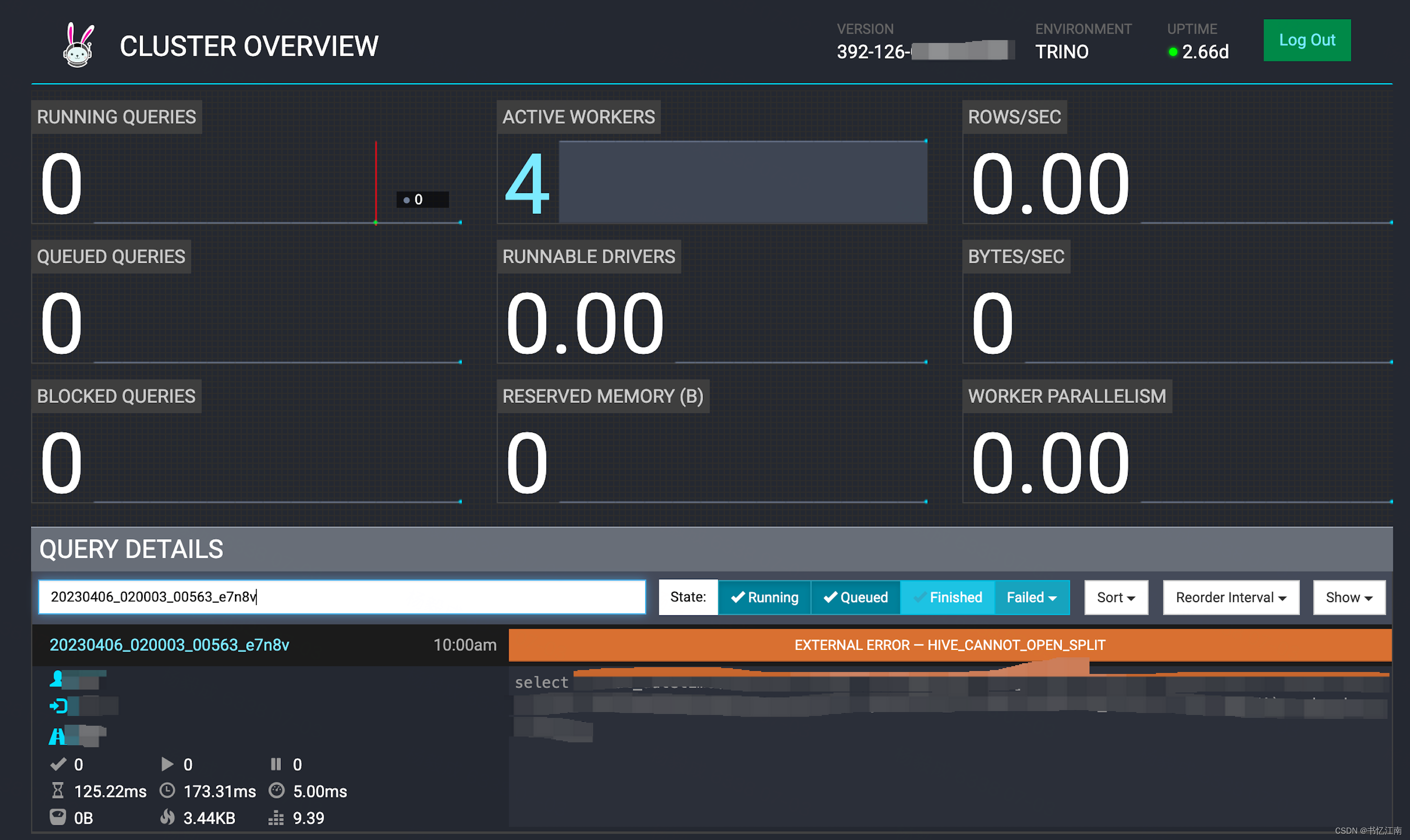
三、常见问题判断与解决方法
具体报错有成百上千种之多,但是其中有一部分是较常见、甚至google报错内容就能搜到解决方法的,下面阐述部分比较常见的问题迹象,和相应的解决方案,将随时间更新。
3.1、数据倾斜导致查询慢
在Trino Query的执行过程中,会遇到时间很长的情况,其中一个可能性就是数据倾斜,判定数据倾斜的标准之一是下图进入具体查询id链接的Overview界面中,展开每个stage的节点信息,可以看到stage26中,某个节点的处理数据量要比其他节点大好几倍,其他节点执行的快也要最终等它执行完才能结束:
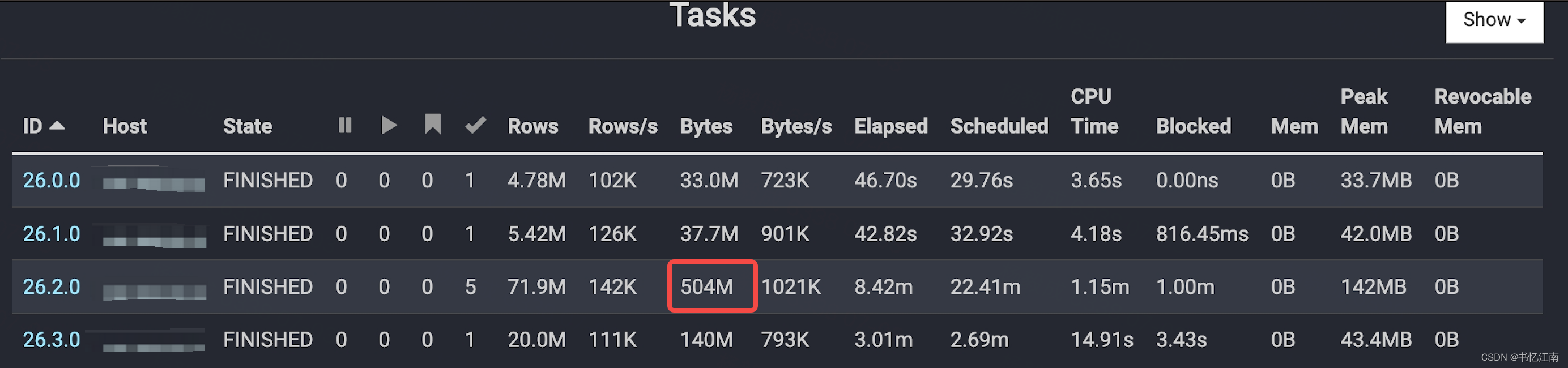

数据倾斜往往出现于join或者group by操作(distinct在开启mark distinct特性时会优化成group by那样的预聚合)的位置,正如上面结合Query Overview和Live Plan两个界面的提示(ScanFilterProject的算子之后进行预聚合operator),这样观察SQL之后就能发现数据倾斜语句的位置,并根据具体业务场景进行改写。
除了引擎自动进行优化的hash build join(类似Spark的broadcast join)等技术外,SQL层面可以尝试打散会被join on的字段值:
--打散数据(倾斜字段未知)
select id, value, concat(id, (rand() * 10000) % 3) as new_id from A
select id, value, concat(id, suffix) as new_id
from (
select id, value, suffix
from B CROSS JOIN UNNEST(array(0, 1, 2)) tmp as suffix(array(0, 1, 2))
)
--打散数据(倾斜字段已知)
select t1.id, t1.id_rand, t2.name
from (
select id ,
case when id = null then concat(‘SkewData_’, cast(rand() as string))
else id end as id_rand
from test1
where statis_date = ‘20200703’) t1
left join test2 t2
on t1.id_rand = t2.id 可以通过如下SQL判断某个join on或group by字段是否存在倾斜:
select id, count(id) as cnt from table1
where xxxx
group by id
having cnt > 33.2、混布架构抢不到CPU导致查询慢
Trino作为全内存计算引擎,对CPU与内存的需求量很大,如果和其他引擎混布在同一个节点上可能会互相影响。它在对多个候选执行计划进行CBO比较哪个更优时,也是对CPU开销的权重(比较开销时的重视程度)占到了75%,内存占10%(因为它量大相对CPU便宜),网络占15%。
如果是混布架构下出现如下迹象,则Trino可能有点抢不到CPU,即查询Overview界面里,某些stage的调度时间远高于CPU时间:
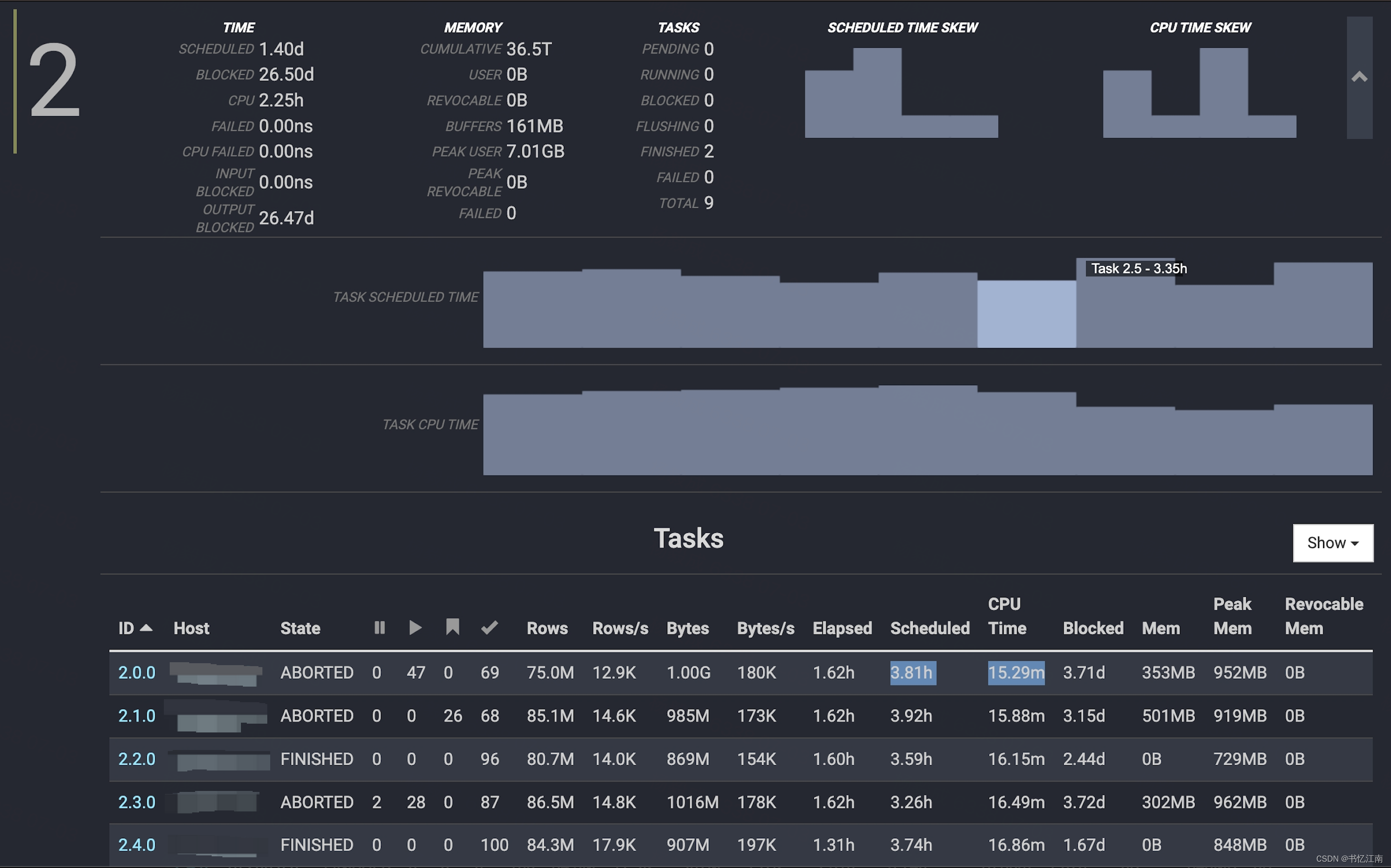
如果频繁出现这种现象,则可以看具体情况是否切换到存算分离架构,将trino worker等独立出来,避免和其他高耗能组件竞争物理机资源。
3.3、Remote Page is too large
原因是各stage之间进行shuffle exchange时,传输的数据过大超过了默认16M的限制,可能是因为page数据中包含复杂嵌套列,通过Jackson序列化成JSON传输出去的时候容量很大,可以参考如下issue增大config.properties中的参数限制:
Remote page is too large exceptions · Issue #10292 · trinodb/trino · GitHubHi all, We’re running into issues with Remote page is too large exceptions. This is the stack trace in the admin UI: io.trino.operator.PageTooLargeException: Remote page is too large at io.trino.operator.HttpPageBufferClient.rewriteExcep... https://github.com/trinodb/trino/issues/10292
https://github.com/trinodb/trino/issues/10292
3.4、小文件过多导致查询慢
可以用hadoop fs -ls命令查看一下对应目录下的文件情况,一般HDFS处理32MB以内大小的文件会比较慢,因为它为了海量数据高吞吐性能而牺牲了小文件的读取性能。对于hive表来说默认HDFS路径往往是:/user/hive/warehouse/库名.db/表名/分区名1=值/分区名2=值
这种情况下可以参考部署英特尔开源的SSM服务进行小文件合并:
GitHub - Intel-bigdata/SSM: Smart Storage Management for Big Data, a comprehensive hot/cold data optimized solutionSmart Storage Management for Big Data, a comprehensive hot/cold data optimized solution - GitHub - Intel-bigdata/SSM: Smart Storage Management for Big Data, a comprehensive hot/cold data optimized solutionhttps://github.com/Intel-bigdata/SSM
3.5、某个stage的算子block住其他stage
由于trino的默认处理模式是流式的,某一环节的算子执行的慢,会block住所有其他各stage的算子,分为2种情况:
(1)表扫描太慢block住下游所有算子:在具体查询的Live Plan界面里,看到各底部scan数据的stage没有block,而下游stage被block:
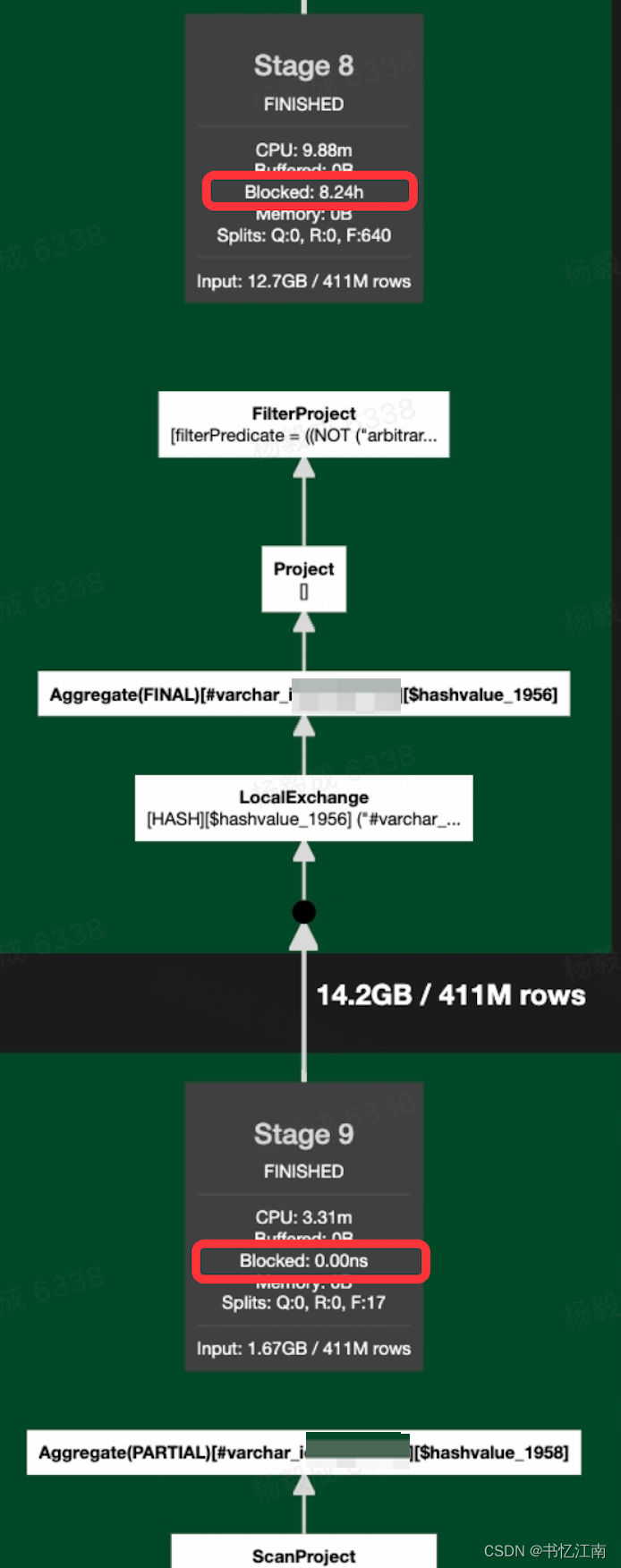
这种时候就要去对应排查具体涉及的存储引擎是否有性能瓶颈,例如小文件等。
(2)下游算子计算慢,反压block回扫描stage:和上面的情况相反,是执行计划树底部TableScan或者ScanFilterProject所在的stage出现block,而下游stage(也就是Live Plan中上方的stage)的block时间远小于Scan Stage的block时间,则可以判断是下游的计算算子处理慢了,需根据具体SQL来改进书写方式。
3.6、Join时右侧表远大于左侧表导致查询慢
Trino自身会根据对应表存储的统计信息(行数、容量、列的最小最大值等)来自动进行一些执行计划优化,但是当统计信息缺失时,Trino并不确定用什么方式最优,只能用默认行为来执行。例如下图中的事件表与历史标签表进行join,本来Trino在提前得知标签表会更大的前提下,可以自动调换join的左右顺序,即reorder join自动优化。
但是由于事件表量级太大,没有提前进行过analyze命令,Trino并不提前知道事件表的statistics,只好采用了对join的左侧即事件表进行probe,右侧的标签表进行hash build(把它以为的“小表”每一行进行哈希值计算,全部加载到内存,广播到各probe侧的worker里,类似spark的broadcast join)的模式,导致标签表容量大、在广播时的开销很高的现象,本来它更大应该处于左边的probe侧。

这种情况下,可以手动改写SQL调换join的顺序,例如ta_event_3 left join history_tag_3改写为history_tag_3 right join ta_event_3,或者对join两边的表执行如下命令之后再join:
analyze 要统计信息的表名3.7、Could not communicate with the remote task. The node may have crashed or be under too much load. This is probably a transient issue, so please retry your query in a few minutes.
很多时候这个报错主要由2方面的原因导致:
(1)集群CPU负载高或者出现Full GC,导致worker出现几十秒甚至分钟级的不对外进行HTTP响应的情况。
(2)集群网络带宽有瓶颈或质量抖动。
除了分析当时时刻是否有大查询、集群资源是否充足、网卡是否为千兆以外,缓解的方法是设置如下config.properties参数:
exchange.http-client.request-timeout=30s
node-manager.http-client.request-timeout=30s
# 仅限coordinator
memoryManager.http-client.request-timeout=15s3.8、Column name not specified at position
一般是因为SQL中某些select的列没有写as别名,例如:
create table t1 as select c1, c2, '2023-07-03 17:55:00' from t2解决的办法是找到没有取别名的列加上as语句,如下所示:
create table t1 as select c1, c2, '2023-07-03 17:55:00' as stamp1 from t2四、不建议的SQL写法
不建议的写法并不代表完全不能写,只是如果具体业务场景可以避免这种写法就尽量减少,如果具体逻辑无法用其他写法替代,必须使用一些复杂且性能较差的写法时,也是可以的。
4.1、过多的连续join
Trino源码中默认只能对9个以内的连续join进行自动调整join顺序以降低计算开销的优化,且过于庞大的SQL往往会消耗更多的plan时间,所以一般建议SQL中连续的join语句最多不超过9个,最好可以不超过4到5个,尽量每几个连续join拆分成一个临时表或者view后再接着join。
4.2、过多的arbitrary()函数
如下issue提到了arbitrary()函数在内存效率上的问题:
Optimize arbitrary() aggregation · Issue #11187 · prestodb/presto · GitHubI have a use case of removing duplicate rows from a large table by a unique key: SELECT unique_key, ARBITRARY(huge_column) AS huge_column FROM my_table GROUP BY unique_key Presto puts huge_column in memory, while the only thing that need...https://github.com/prestodb/presto/issues/11187
4.3、over()等窗口函数不用partitioned by语句等限定窗口范围
这种情况下,如果还不带上where等过滤条件,就会相当于每一行数据都匹配全表范围的窗口,内存等开销会很大。
4.4、全表cross join/笛卡尔积
如果不加过滤条件,左表的每一行数据都交错匹配右表的每一行数据,执行时间和资源消耗将大大增加。



![Go环境搭建[win10]](https://img-blog.csdnimg.cn/b31fc060f212490b91c89ceb671d79ed.png#pic_center)