项目介绍
通过猫狗熊猫图片来对图片进行识别,分类出猫狗熊猫的概率,文章会分成两部分,从基础网络模型->利用卷积网络经典模型Vgg。
基础网络模型
基础的网络模型主要是用全连接层来分类,比较经典的方法,也是祖先最先使用的方法,目前已经在这类问题上,被卷积网络模型所替代,学习这部分是为了可以了解到最简单的分类任务的写法。
一、准备数据
- 准备猫狗熊猫的训练数据集,各自1000张图片,分别放在
/train/cats,/train/dogs,/train/panda - 准备猫狗熊猫的测试数据集,各5-10张,统一放在
/test目录下,后续通过随机取出来测试



二、开始编写
1、获取数据
数据的获取主要包含2部分
- 先读取图片数据
- 对图片数据进行预处理
import tensorflow as tf
from tensorflow.keras import initializers
from tensorflow.keras import regularizers
from tensorflow.keras import layers
from keras.models import load_model
from keras.models import Sequential
from keras.layers import Dropout
from keras.layers.core import Dense
from keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
lb = LabelBinarizer()
import matplotlib.pyplot as plt
import random
import os
import numpy as np
np.set_printoptions(threshold=10000)
import cv2
import pickle
# 遍历所有文件名
def findAllFile(base):
for root, ds, fs in os.walk(base):
for f in fs:
yield f
# 数据切分
def split_train(data,label,test_ratio):
np.random.seed(43)
shuffled_indices=np.random.permutation(len(data))
test_set_size=int(len(data)*test_ratio)
test_indices =shuffled_indices[:test_set_size]
train_indices=shuffled_indices[test_set_size:]
return data[train_indices],data[test_indices],label[train_indices],label[test_indices]
image_dir = ("./train/cats/", "./train/dogs/", "./train/panda/")
image_path = []
data = []
labels = []
# 读取图像路径
for path in image_dir:
for i in findAllFile(path):
image_path.append(path+i)
# 随机化数据
random.seed(43)
random.shuffle(image_path)
# 读取图像数据,读取label文件名数据
for j in image_path:
image = cv2.imread(j)
image = cv2.resize(image,(32,32)).flatten()
data.append(image)
label = j.split("/")[-2]
labels.append(label)
# 数据预处理:规格化数据
data = np.array(data,dtype="float") / 255.0
labels = np.array(labels)
# 数据切分
(trainX,testX,trainY,testY) = split_train(data,labels,test_ratio=0.25)
# 将cat、dog、panda规格化数据
trainY = lb.fit_transform(trainY)
testY = lb.fit_transform(testY)
# 最终数据结果
print(trainX)
print(data)
print(data.shape) # (3000, 3072),32x32x3=3072,其图片3通道被拉长成一条操作
print(lb.classes_) # ['cats' 'dogs' 'panda']
将所有图片读取,并保存他们的数据集数据和训练结果,每张图片都会被规整到32x32并且进行拉长操作flatten(),最终输出的数据是一组图片的RGB数据
- 数据集:我们将数据进行切分,25%作为验证集,75%数据作为训练集
- 训练结果(label):我们按照文件名上进行分割,分割出对应的名字作为label

2、构建网络模型
- 网络模型:采用全连接层
- 优化器:使用梯度下降法SGD
- 损失函数:使用分类算法
- 权重初始化:高斯截断分布函数
# 2、创建模型层
EPOCHS = 200
model = Sequential()
model.add(Dense(512,input_shape=(3072,),activation="relu",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None)))
model.add(Dropout(0.5))
model.add(Dense(256,activation="relu",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None)))
model.add(Dropout(0.5))
model.add(Dense(len(lb.classes_),activation="softmax",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None)))
# 损失函数和优化器,正则惩罚
model.compile(loss="categorical_crossentropy", optimizer=SGD(lr=0.001),metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY),epochs=EPOCHS, batch_size=32)

3、模型评估
模型训练后之后,对模型进行评估,可以看到当前的分类情况
# 3、模型评估
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1), target_names=lb.classes_))

4、数据可视化
将数据绘制在图上,看看其训练和预测的准确率情况,并将其保存起来
# 4、数据可视化
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy (Simple NN)")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig("./plot.png")

5、保存模型
# 5、保存模型到本地
model.save("./model")
f = open("./label.pickle", "wb")
f.write(pickle.dumps(lb))
f.close()
6、结果输出预测
随机获取测试集中的图片,对数据进行预处理后,进行预测,将结果显示出来
# 6、测试模型
test_image_dir = "./test/"
test_image_path = []
for i in findAllFile(test_image_dir):
test_image_path.append(test_image_dir+i)
test_image = random.sample(test_image_path, 1)[0]
# 数据预处理
image = cv2.imread(test_image)
output = image.copy()
image = image.astype("float") / 255.0
image = cv2.resize(image,(32,32)).flatten()
image = image.reshape((1, image.shape[0]))
# 加载模型
model = load_model("./model")
lb = pickle.loads(open("./label.pickle", "rb").read())
# 开始预测
preds = model.predict(image)
# 查看预测结果
text1 = "{}: {:.2f}% ".format(lb.classes_[0], preds[0][0] * 100)
text2 = "{}: {:.2f}% ".format(lb.classes_[1], preds[0][1] * 100)
text3 = "{}: {:.2f}% ".format(lb.classes_[2], preds[0][2] * 100)
cv2.putText(output, text1, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 0, 255), 2)
cv2.putText(output, text2, (10, 80), cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 0, 255), 2)
cv2.putText(output, text3, (10, 120), cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 0, 255), 2)
cv2.imshow("Image", output)
cv2.waitKey(0)
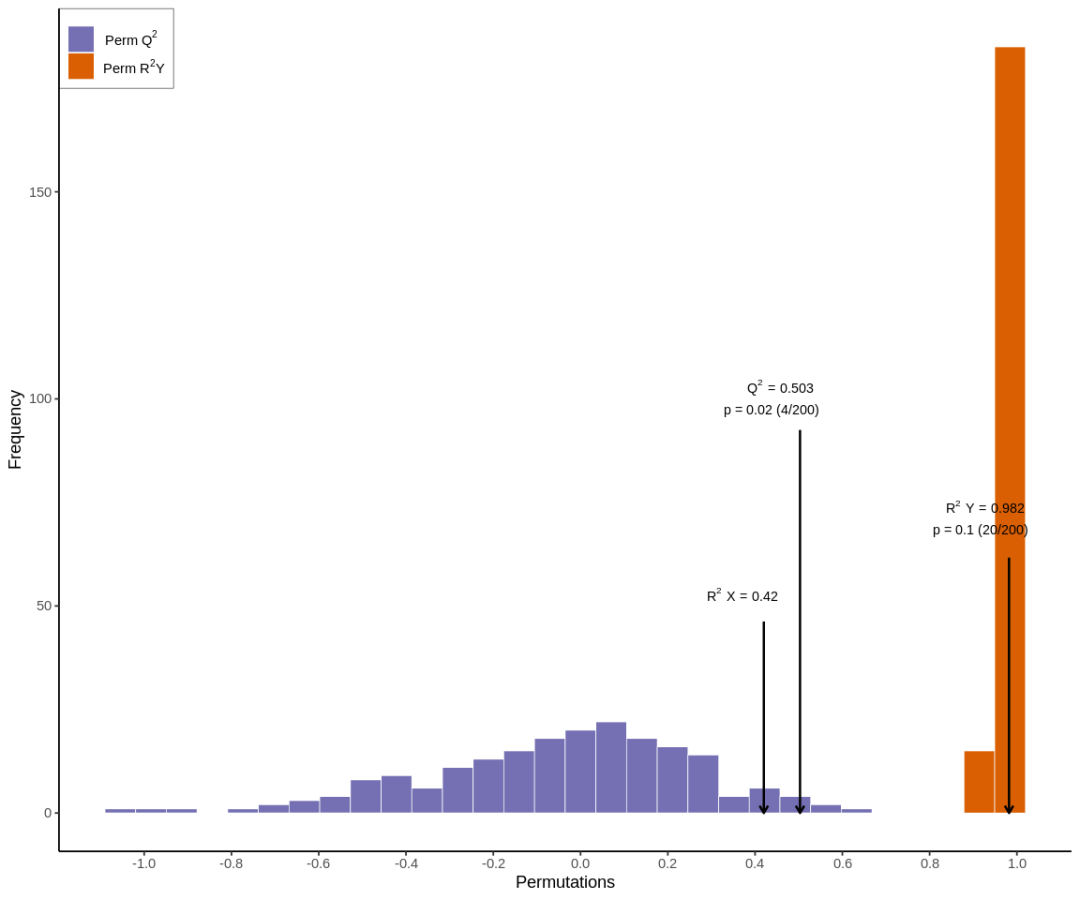
通过我们的测试集合看出来,其准确率还是有点不尽如意,主要是数据集较小,且训练次数不足的原因导致

vgg模型
在后续的技术迭代中,卷积神经网络基本上已经覆盖了图像识别技术,使用卷积神经网络结合vgg的架构,可以更准确地提高准确率
一、准备数据
跟上面基础模型一样,所有数据都是一样的
二、开始编写
1、获取数据
获取数据的代码跟基础网络模型完全一致,唯一区别在于# image = cv2.resize(image,(32,32)).flatten() # 将图片resize到64,且去掉拉长操作
import tensorflow as tf
from tensorflow.keras import initializers
from tensorflow.keras import regularizers
from tensorflow.keras import layers
from keras.models import load_model
from keras.models import Sequential
from keras.layers import Dropout
from keras.layers.core import Dense
from keras.optimizers import SGD
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
lb = LabelBinarizer()
import matplotlib.pyplot as plt
import random
import os
import numpy as np
np.set_printoptions(threshold=10000)
import cv2
import pickle
# 遍历所有文件名
def findAllFile(base):
for root, ds, fs in os.walk(base):
for f in fs:
yield f
# 数据切分
def split_train(data,label,test_ratio):
np.random.seed(43)
shuffled_indices=np.random.permutation(len(data))
test_set_size=int(len(data)*test_ratio)
test_indices =shuffled_indices[:test_set_size]
train_indices=shuffled_indices[test_set_size:]
return data[train_indices],data[test_indices],label[train_indices],label[test_indices]
image_dir = ("./train/cats/", "./train/dogs/", "./train/panda/")
image_path = []
data = []
labels = []
# 1、数据预处理
# 读取图像路径
for path in image_dir:
for i in findAllFile(path):
image_path.append(path+i)
# 随机化数据
random.seed(43)
random.shuffle(image_path)
# 读取图像数据,读取label文件名数据
for j in image_path:
image = cv2.imread(j)
image = cv2.resize(image,(64,64))
# image = cv2.resize(image,(32,32)).flatten() # 将图片resize到64,且去掉拉长操作
data.append(image)
label = j.split("/")[-2]
labels.append(label)
# 规格化数据
data = np.array(data,dtype="float") / 255.0
labels = np.array(labels)
# 数据切分
(trainX,testX,trainY,testY) = split_train(data,labels,test_ratio=0.25)
# 将cat、dog、panda规格化数据
trainY = lb.fit_transform(trainY)
testY = lb.fit_transform(testY)
# 最终数据结果
print(trainX)
print(data)
print(data.shape) # (3000, 3072),32x32x3=3072,其图片3通道被拉长成一条操作
print(lb.classes_) # ['cats' 'dogs' 'panda']
2、构建网络模型
采用vgg的框架,搭建最简单的vgg层数的网络模型
from keras.models import Sequential
from keras.layers.normalization.batch_normalization_v1 import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.initializers import TruncatedNormal
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
model = Sequential()
chanDim = 1
inputShape = (64, 64, 3)
model.add(Conv2D(32, (3, 3), padding="same",input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Dropout(0.25))
# (CONV => RELU) * 3 => POOL
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Dropout(0.25))
# FC层
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
#model.add(Dropout(0.6))
# softmax 分类,kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)
model.add(Dense(len(lb.classes_)))
model.add(Activation("softmax"))
# 损失函数和优化器,正则惩罚
EPOCHS = 200
model.compile(loss="categorical_crossentropy", optimizer=SGD(lr=0.001),metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY),epochs=EPOCHS, batch_size=32)

3、数据可视化
同样的操作,将数据绘制在图上,看看其训练和预测的准确率情况,并将其保存起来
# 4、数据可视化
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy (Simple NN)")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig("./plot.png")

4、保存模型
# 5、保存模型到本地
model.save("./model")
f = open("./label.pickle", "wb")
f.write(pickle.dumps(lb))
f.close()
5、结果输出预测
同样的操作,唯一的区别在于
# image = cv2.resize(image,(32,32)).flatten() #不拉平,且改为64x64# image = image.reshape((1, image.shape[0])) #数据改为数组
# 6、测试模型
test_image_dir = "./test/"
test_image_path = []
for i in findAllFile(test_image_dir):
test_image_path.append(test_image_dir+i)
test_image = random.sample(test_image_path, 1)[0]
# 数据预处理
image = cv2.imread(test_image)
output = image.copy()
image = image.astype("float") / 255.0
# image = cv2.resize(image,(32,32)).flatten() #不拉平,且改为64x64
# image = image.reshape((1, image.shape[0])) #数据改为数组
image = cv2.resize(image,(64,64))
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
# 加载模型
model = load_model("./model")
lb = pickle.loads(open("./label.pickle", "rb").read())
# 开始预测
preds = model.predict(image)
# 查看预测结果
text1 = "{}: {:.2f}% ".format(lb.classes_[0], preds[0][0] * 100)
text2 = "{}: {:.2f}% ".format(lb.classes_[1], preds[0][1] * 100)
text3 = "{}: {:.2f}% ".format(lb.classes_[2], preds[0][2] * 100)
cv2.putText(output, text1, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 0, 255), 2)
cv2.putText(output, text2, (10, 80), cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 0, 255), 2)
cv2.putText(output, text3, (10, 120), cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 0, 255), 2)
cv2.imshow("Image", output)
cv2.waitKey(0)
通过我们的结果展示,可以发现分类的精准度可以达到80-90%以上,说明这个模型是比基础网络模型50%左右的准确度好很多,但是,也会精准的分类错误,原因在于我们只有1000的数据集,比较容易分类错误,当然你的数据量越大,就可以解决当前的问题。

源代码
- 源码查看