OPLS-DA分析,组间差异
在上一场小工具讲解中,小姐姐给大家介绍了PLS-DA的原理及用途,而在代谢组学数据分析中,除去PLS-DA以外,OPLS-DA分析也是非常常见的,仅一个字母之差,那二者到底有何差别,我们一起来一探究竟!
,时长15:22
■ ■■■■
视频解说教程
1
什么是OPLS-DA分析?
OPLS-DA分析,全称正交偏最小二乘法判别分析(OrthogonalPartialLeast Squares-DiscriminantAnalysis),它结合了正交信号矫正(OSC)和PLS-DA方法,能够将X矩阵分解成与Y相关和不相关的两类信息,通过去除不相关的差异来筛选差异变量。
2
OPLS-DA分析的原理是什么?
OPLS-DA不同于PCA,它是一种有监督的判别分析统计方法。运用偏最小二乘回归建立代谢物表达量与样本类别之间的关系模型,来实现对样本类别的预测。OPLS-DA分析需要样本变量矩阵和样本分类矩阵两个文件来确立样本关系,如下所示:
X矩阵,样本-变量矩阵
| 变量1 | 变量2 | 变量3 | |
| 样本1 | n11 | n12 | n13 |
| 样本2 | n21 | n22 | n23 |
| 样本3 | n31 | n32 | n33 |
| 样本4 | n41 | n42 | n43 |
Y矩阵,样本分类矩阵
| 分类1 | 分类2 | |
| 样本1 | 1 | 0 |
| 样本2 | 0 | 1 |
| 样本3 | 1 | 0 |
| 样本4 | 0 | 1 |
OPLS-DA建模时,将X矩阵信息分解成与Y相关和不相关的两类信息,其中与Y相关的变量信息为预测主成分,与Y不相关的变量信息为正交主成分。根据OPLS-DA模型分析代谢组数据,绘制各分组的得分图,进一步展示各个分组之间的差异(Thévenotet al., 2015)。
3
OPLS-DA分析有什么用?
OPLS-DA分析在实现降维的同时考虑了分组信息,因此它可以用于特征选择以及分类,也就是在代谢组学数据分析中,可以用于筛选不同组之间的差异代谢物。通过OPLS-DA分析,每个代谢物可以得出一个VIP值,即变量重要性投影(VariableImportance inProjection,VIP),VIP值越大,代表该物质对于区分两组所具有的贡献越大,因此我们在挑选差异代谢物时,通常会将VIP值作为其中一项重要的考察指标。
4
OPLS-DA分析的结果怎么看?
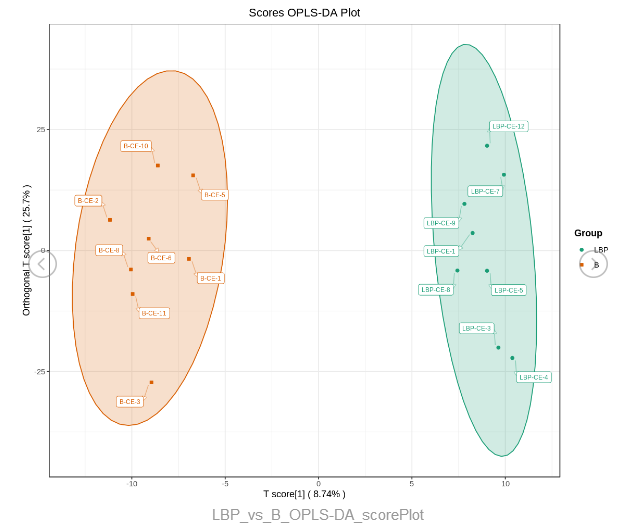
OPLS-DA分析结果中最常用的图就是OPLS-DA得分图,图中横坐标表示预测主成分,因此横坐标方向可以看出组间的差距;纵坐标表示正交主成分,因此纵坐标方向可以看出组内的差距;百分比表示该成分对数据集的解释率。图中的每个点表示一个样品,同一个组的样品使用同一种颜色表示,Group为分组。
■ ■■■■
OPLS-DA得分图
除去得分图以外,OPLS-DA分析还可以得到S-plot图,S-plot图的横坐标表示主成份与代谢物的协方差,纵坐标表示主成份与代谢物的相关系数。S-plot图一般用来挑选与OSC过程中主要成分的相关性比较强的代谢物,从另一方面同时也可以挑选与Y相关性强的代谢物。越靠近两个角的代谢物重要度越强。S-plot图中红色的点表明这些代谢物的VIP值大于等于1,绿色的点表示这些代谢物的VIP值小于等于1。

■ ■■■■
OPLS-DA的S-plot图
5
如何评判OPLS-DA模型的好坏?
并非所有的数据都适合使用OPLS-DA模型进行分析,因此在模型建立之后,我们需要通过模型验证来对模型质量进行评价。
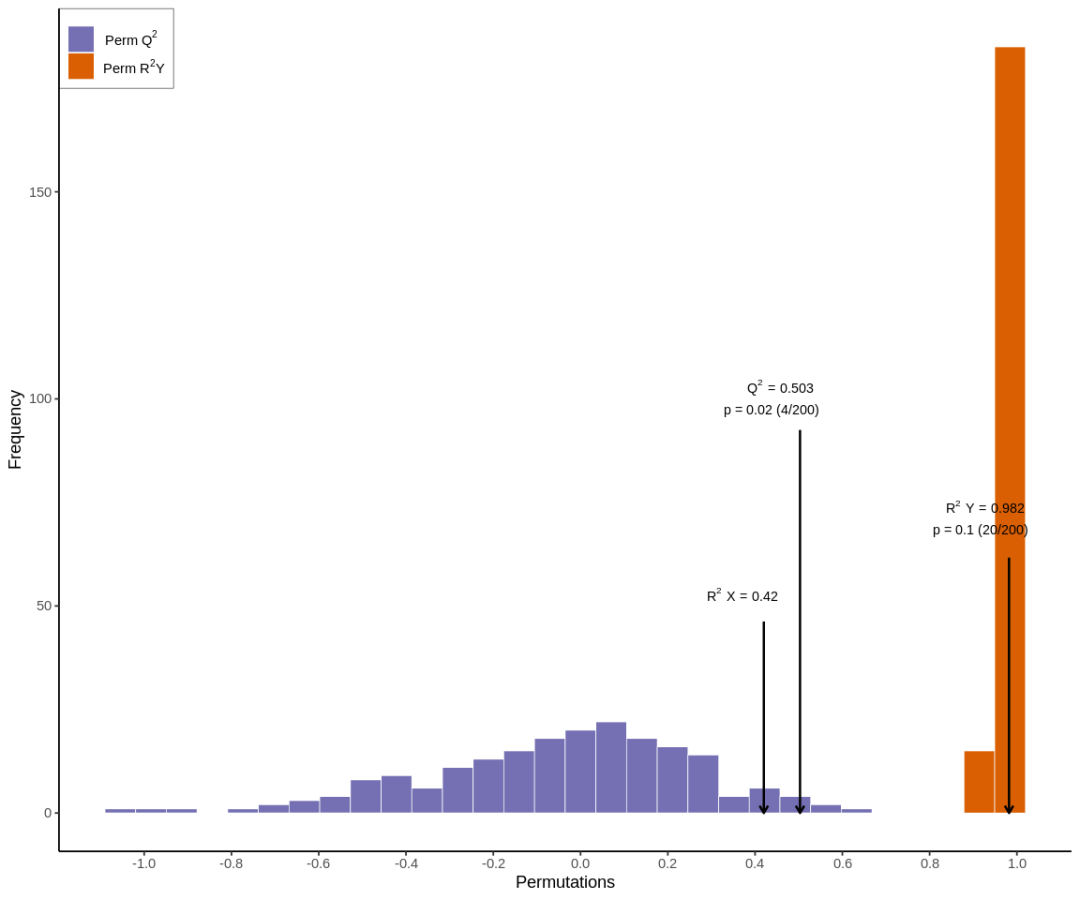
OPLS-DA评价模型的参数有R2X,R2Y和Q2,其中R2X和R2Y分别表示所建模型对X和Y矩阵的解释率,Q2表示模型的预测能力,这三个指标越接近于1时表示模型越稳定可靠,Q2 >0.5时可认为是有效的模型,Q2 >0.9时为出色的模型。
■ ■■■■
OPLS-DA模型验证图
上图为OPLS-DA模型验证图,图中横坐标表示模型R2Y,Q2值,纵坐标是模型分类效果出现的频数,即本模型对数据进行200次随机排列组合实验,若Q2 的p= 0.02,说明在此次Permutation检测中共有4个随机分组模型的预测能力优于本OPLS-DA模型,若R2Y的p= 0.545,说明在此次Permutation检测中共有109个随机分组模型其对Y矩阵的解释率优于本OPLS-DA模型。一般情况下,p< 0.05 时模型最佳。