目录
- 主从复制
- 1. 全量复制
- 2. 增量复制
- 3. 主从复制的问题
- (1). 主从复制延迟
- (2). 读到过期数据
- (3). 主从配置不一致导致数据丢失
- (4). 全量复制性能损耗大
- (5). 主节点向所有从节点进行全量复制,消耗大量网络带宽(复制风暴)
- 参考
- Sentinel哨兵
- Redis cluster集群
- 1. 建立集群:
- 2. 槽分配
- 3. 处理命令
- 4. 数据重新分片(通常用于扩容、缩容)
- 5. 故障检测与转移
- 参考
- 三种高可用比较
主从复制
一主多从,每个节点数据都是相同的。核心的作用是数据备份和读写分离来提高查询性能
复制分为全量复制和增量复制。在2.8版本之前只有全量复制,而2.8版本后有全量和增量复制
1. 全量复制

分为三阶段:
- 建立连接,协商同步
- 主库同步数据给从库
- 主库发送新写命令给从库
几个概念:
- runID:主节点启动时生成的随机ID,第一次为?
- offset:复制偏移量,第一次为-1。主从节点都会维护自己的复制偏移量,主节点向从节点传播N个字节数据时,从节点自己会将复制偏移量加N,从节点接受到数据后,也会将自己的偏移量加N
- repl buffer(或replication buffer):在生成RDB文件后,记录主节点写命令的缓冲区,会不断将命令发送到从节点
1. 建立连接,协商同步
- 从节点执行slaveof命令后,会向主节点发送psync命令,并携带两个参数:runID(主节点启动时生成的随机ID,第一次为?)和offset(从节点的复制进度,第一次为-1)
- 主节点收到命令后,会使用FULLRESYNC命令(表示第一次复制采用全量复制),并携带runID和offset
2. 主库同步数据给从库
- 主库执行BGSAVE命令,生成RDB文件,并通过网络发送给从库。
- 从库接受到文件后,清空当前数据库,并加载文件
3. 主库发送新写命令给从库
在主节点生成RDB文件到从节点加载文件完毕的过程中,主节点可能有新数据写入,因此需要将新数据传递给从节点。
- 主节点会将没有记录到RDB文件的写操作,记录到复制缓冲区(replication buffer)
- 主节点不断将缓冲区的命令发送到从节点,从节点重新执行
- 数据同步后,主从节点建立TCP长连接。主节点会不断给从节点发送新的写命令
2. 增量复制
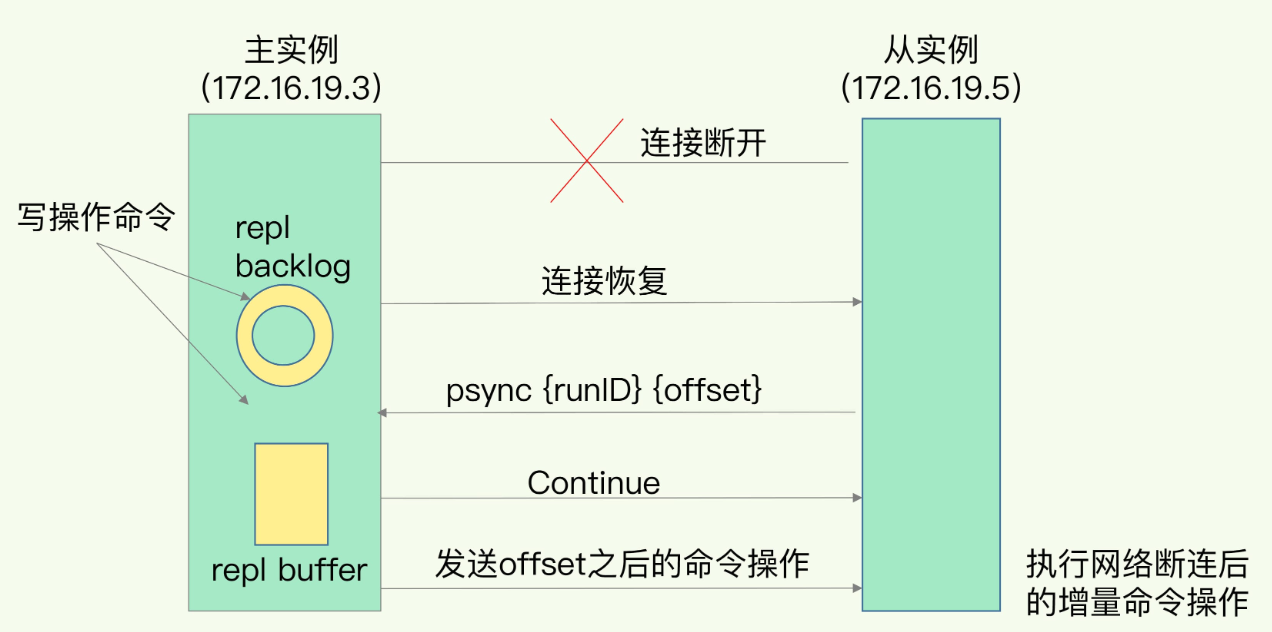
假如主从节点之间网络断开,重新连接后重新进行全量复制,并生成RDB文件,对于网络带宽以及服务性能都会有影响。增量复制能够
几个概念:
- repl backlog:复制积压缓冲区,是一个环形的先进先出队列,主节点在命令传播时,不仅将命令发送给从节点,还会记录到复制积压缓冲区。因为容量有限,超过一定数量后会覆盖旧数据。
大致流程:
- 断开后恢复,从节点的数据会落后主节点。从节点向主节点发送psync命令,携带runID和offset参数
- 以下两种情况会返回FULLRESYNC命令并触发全量复制
- 主节点发现从节点发送的runID与自己不一致,说明自己重启过或者从节点之前不是从自己复制的(原来的主宕机,从节点变为了主节点)
- 从节点宕机过久,发送的offset在repl backlog中找不到
- 如果主节点发现runID一致,并且offset在repl backlog中能够找到,则会返回Continue命令,准备增量复制
- 主节点把repl backlog中offset之后的数据发送给从节点
3. 主从复制的问题
(1). 主从复制延迟
产生原因:
- 从节点阻塞,会延迟主节点的写入,在从节点读不到某些数据
- 本身从写入主节点到写入从节点需要一定时间
解决方法:
一致性要求不高的场景一般不需要解决。
- **减缓:**避免从节点堵塞,排查大key问题,和避免用keys等同步耗时操作
- 严格一致: 直接或者选择性读取主节点,牺牲一定的性能。
(2). 读到过期数据
关于Redis过期删除,可以看Redis八股文必背的Redis处理过期键策略
在主节点读取过期数据后,会惰性删除,但是不会触发从节点的数据删除。
Redis 3.2 版本之前: 从节点读取数据时,不会判断数据是否过期而直接返回数据,并且不会删除过期数据。
Redis 3.2 版本之后:
- 从节点读取数据时,会判断是否过期,如果过期返回空值,但仍然不会删除。
- 如果使用EXPIRE 和 PEXPIRE,它们给数据设置的是从命令执行时开始计算的存活时间,即相对时间,那么从节点会在接受命令时执行,因而从节点过期时间会比主节点过期时间晚。
- 如果使用EXPIREAT 和 PEXPIREAT:它们会直接把数据的过期时间设置为具体的一个时间点。这种方式没问题。
(3). 主从配置不一致导致数据丢失
maxmemory配置不一致,比如从节点内存配置比主节点小。那么从节点可能比主节点先行发生缓存淘汰(4. Redis缓存淘汰策略)。并且若是该从节点升级为主节点,那么整个集群都会发生数据丢失。
(4). 全量复制性能损耗大
1. 第一次全量复制
无法避免,但是可以通过下面两种方法降低影响
- 减小节点内存大小(降低RDB复制时间)
- 流量低峰期挂载从节点
2. runID发生改变
主节点重启会导致runID发生改变。无法避免全量复制。
3. 复制积压缓冲区不足
repl backlog复制积压缓冲区不足,导致从节点短暂离线重连后,offset已经无法在主节点找到,从而发生全量复制。可以调大缓冲区大小。
(5). 主节点向所有从节点进行全量复制,消耗大量网络带宽(复制风暴)
主节点重启导致需要向所有从节点进行全量复制。
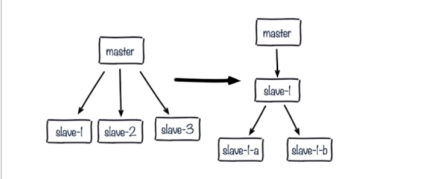
主节点宕机后,将slave1晋升为主节点,就不需要给另外两个从节点进行全量同步了。
可以,但没必要,会带来slave1单点问题、复制延迟增高等问题
参考
- 主从复制详解
- redis主从复制常见的问题
- Redis主从数据不一致及读取过期数据问题的解决方案
Sentinel哨兵
角色说明:
- 主结点:负责处理外部的读写操作
- 从结点:只读,主节点无效时可能被选拔为主节点
- 哨兵:监控主结点、从结点、其他哨兵。主结点故障时选从结点变为主结点。哨兵是特殊的Redis结点,不存储数据,只只支持部分命令
Redis cluster集群
介绍优点: redis cluster集群模式,既拥有哨兵模式高可用、自动主从切换、高性能的特点,又解决了其只有单主结点承载数据量小的缺点。集群模式可以有多主结点,数据分散到多个主节点上,可以动态扩容。
槽分区的特点:
- 利用槽分区来实现数据分片
- 解耦数据和结点的关系,降低扩缩容和数据迁移的难度
一个节点大概会有如下操作
1. 建立集群:
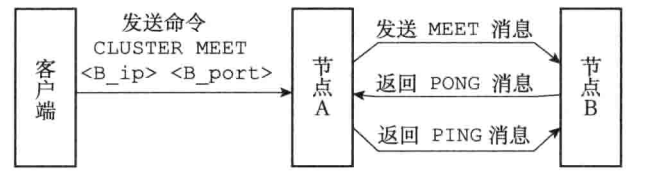
- 最开始时,每个redis实例是一个集群
- 用CLUSTER MEET命令,让各节点握手,组建集群
2. 槽分配
- 为每个实例节点分配一定数量的槽
- 16384个槽分配到所有节点上后,集群变为上线状态(默认配置所有槽都分配才可以上线)
3. 处理命令
- 客户端将命令发到某节点
- 节点通过计算CRC16(key)&16384,得到这个key对应的槽
- 查看槽所分配的节点,若为当前节点,则直接处理命令,否则返回MOVED错误,并提供正确节点的信息
- 客户单拿到正确的节点信息后,重新向正确的节点发起请求。并且下次再操作这个key时会直接访问正确的节点。
4. 数据重新分片(通常用于扩容、缩容)
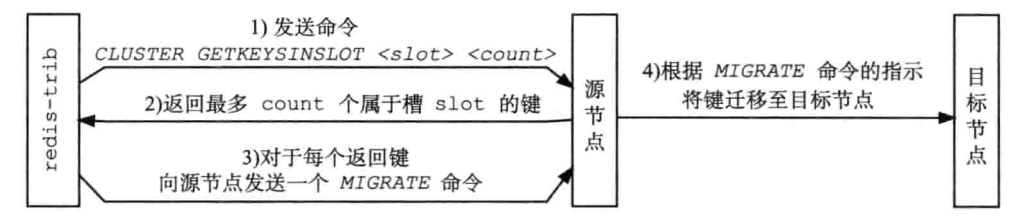
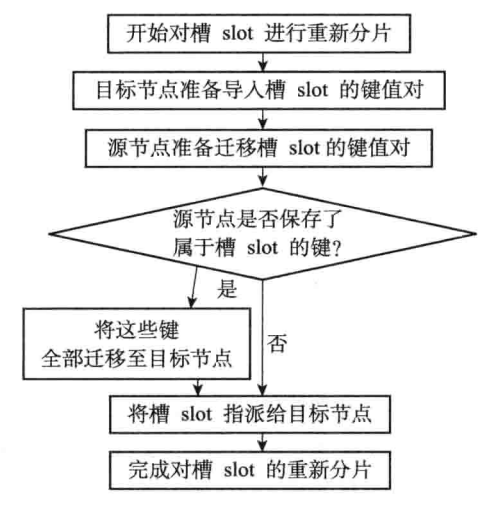
- 分片过程中,各个节点仍然可以对外提供服务。迁移数据过程中,一个槽的数据可能分布在源节点和目标节点
- 客户端发起请求时,通过MOVED错误定位到槽的源节点
- 如果源节点没找到查询的key,那么数据可能迁移到了目标节点中,因此源节点会返回ASK错误,携带了目标节点的信息
- 客户端根据ASK错误和信息,访问目标节点尝试操作(和MOVED不同,下次操作同一个key时,还会访问源节点,而非目标节点)
- 迁移完成后,集群内部通过gossip协议传递最终的槽信息
5. 故障检测与转移
- 集群中每个节点定期向其它结点发送PING消息,如果规定时间内未收到返回的PONG消息,则将其标记为疑似下线(PFAIL)
- 各个节点会交换节点状态信息,超过半数认为某节点意思下线时,那么这个结点会被标记为已下线(FAIL),并将信息在集群中传播
- 在已下线主节点的从结点中选举新的主节点
- 新的主节点会将原主节点的槽指派给自己,并将信息发送到集群中
参考
- 《Redis设计与实现》第十七章:集群
三种高可用比较
| 版本 | 优点 | 缺点 | |
|---|---|---|---|
| 主从模式 | redis2.8之前 | 解决数据备份问题 读写分离,提高查询性能 | 主节点故障无法自动转移,需要人工介入 无法动态扩容 |
| 哨兵模式 | redis2.8级之后的模式 | 在主从模式基础上自动切换主从结点 | 无法动态扩容 连接从结点的客户端在从结点下线后无法获取新的可用从结点 |
| 集群模式 | redis3.0版本之后 | 数据分片,可以支持更大规模的数据 可以动态扩容 | 1、架构比较新,最佳实践较少 2、为了性能提升,客户端需要缓存路由表信息 3、节点发现、reshard操作不够自动化 4、不支持处理多个keys的命令,因为这需要在不同的节点间移动数据 5、Redis 集群不像单机 Redis 那样支持多数据库功能, 集群只使用默认的 0 号数据库, 并且不能使用 SELECT index 命令 |



![【VUE】Element UI 表单校验出现async-validator: [‘discipline is required‘]报错](https://img-blog.csdnimg.cn/706685eb09b94f4cba6c938e8a146d3d.png)