引言
对话管理
我们知道对话管理主要包括状态追踪(DST)和策略优化(DPO)。
对话管理模块包含两个子任务:
- 对话状态追踪(Dialogue State Tracking) 根据用户输入和对话历史识别对话状态;
- 策略学习(Policy Learning) 根据识别到的对话状态选择合适的下一步策略(action/policy);
通常还会涉及到外部知识库(External Knowledge Base,KB),策略学习会和知识库交互,以便更好地选择策略。
比如电影购票机器人的DM模块需要访问电影KB来得到电影名称、电影时间、电影票价等信息,但这块不是我们这里关注的。
状态追踪
我们先来回顾下什么是对话状态。想要完成某个任务,我们需要维护一系列的槽,并且会根据用户输入进行槽值填充。对话状态追踪的目的就是确定槽对应的值。
DST vs NLU
很多人会把DST归到NLU中,因为它们的本质都是槽位填充(slot filling)。
在NLU中的填充是通过对输入进行序列标注得到的:
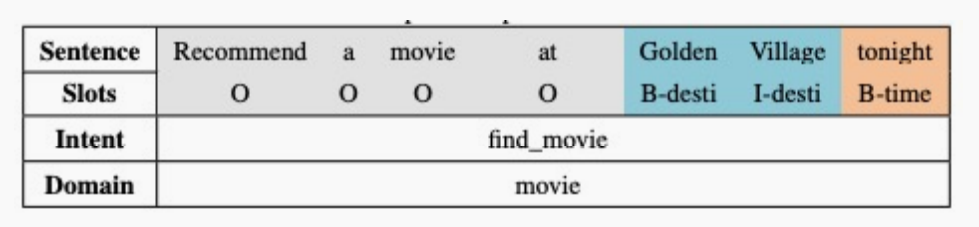
唯一的区别在于NLU(通过序列标注)主要关注于当前输入语句提供了哪些槽和对应的槽值,而DST会考虑整个对话历史,知道用户已经提供了哪些槽值信息。
那DST任务中是如何维护这些槽所对应的值呢?
DST中的填充不对输入做任何标注或分类,在开始时初始化一个空槽位列表。
例如,给定这句话: Recommend a movie at Golden Village tonight. 。
根据NLU中领域分类和意图识别分类的结果,可以得到下面空槽位列表:
{intent : _; domain : _; name : _; pricerange : _; genre : _; destination : _; date : _}
然后基于输入或槽位填充的结果,假设可以得到如下填充的槽位列表:
{intent : inform; domain : movie; name : None; pricerange : None; genre : None; destination : GoldenV illage; date : today}
DST然后需要机器人向用户提问,获取那些未填充的槽值信息。
下面我们看一些例子,包含一些DST的数据集。
首先,是DSTC2(The Second Dialog State Tracking Challenge)数据集。

上图是来自该数据集的一个例子,主要围绕订餐任务。上面介绍了三类槽值:
- Informable slot 用户提供槽值信息
- method 用户消息中包含约束;用户请求替换等
- Request slot 表示该轮对话用户发出一些请求,需要查询KB
对话状态追踪现在还离不开和任务强相关的规则。
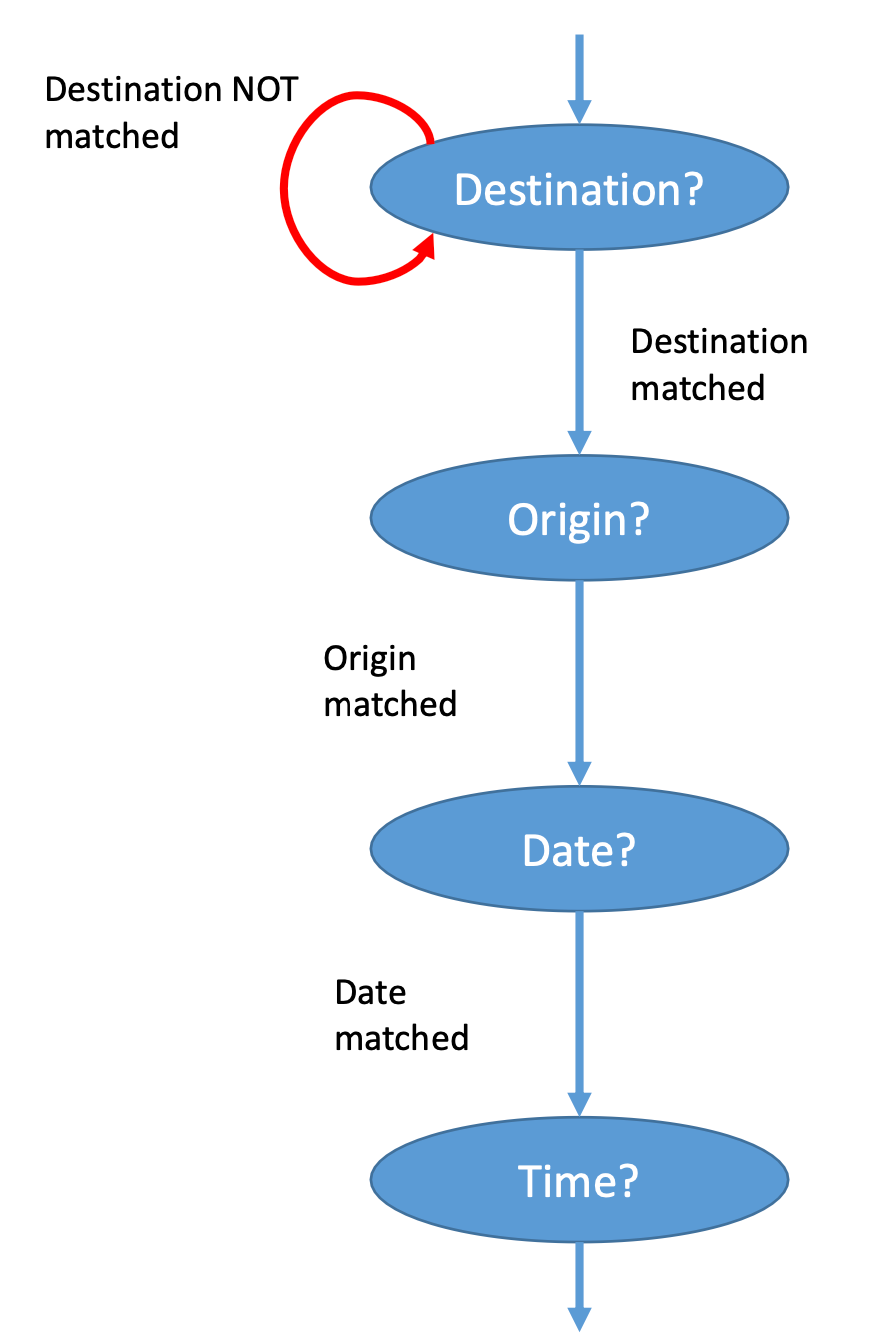
基于规则的DST
最常见的方法是利用有限状态自动机(Finite State Machine)去进行对话管理。

比如上面的对话可以通过以下状态机来完成管理。
基于统计的DST
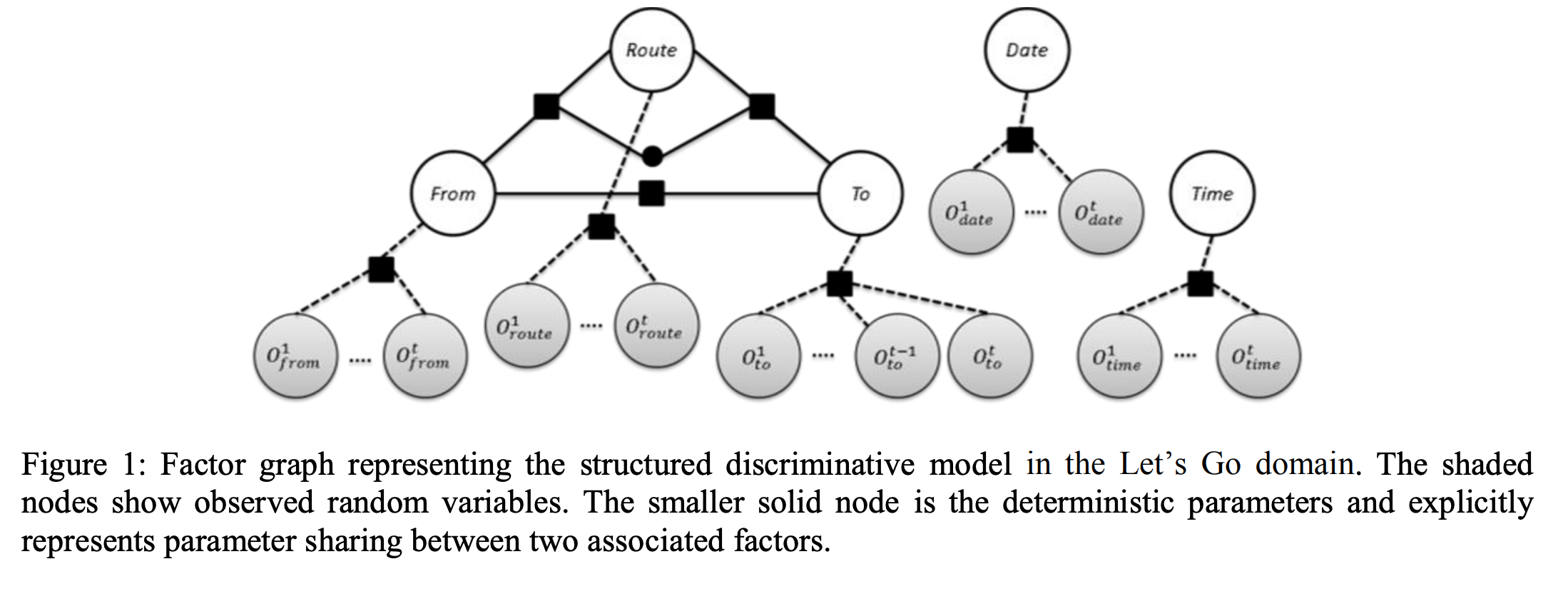
来自论文: Structured Discriminative Model For Dialog State Tracking
把各个槽归纳成概率图模型。
基于神经网络的DST
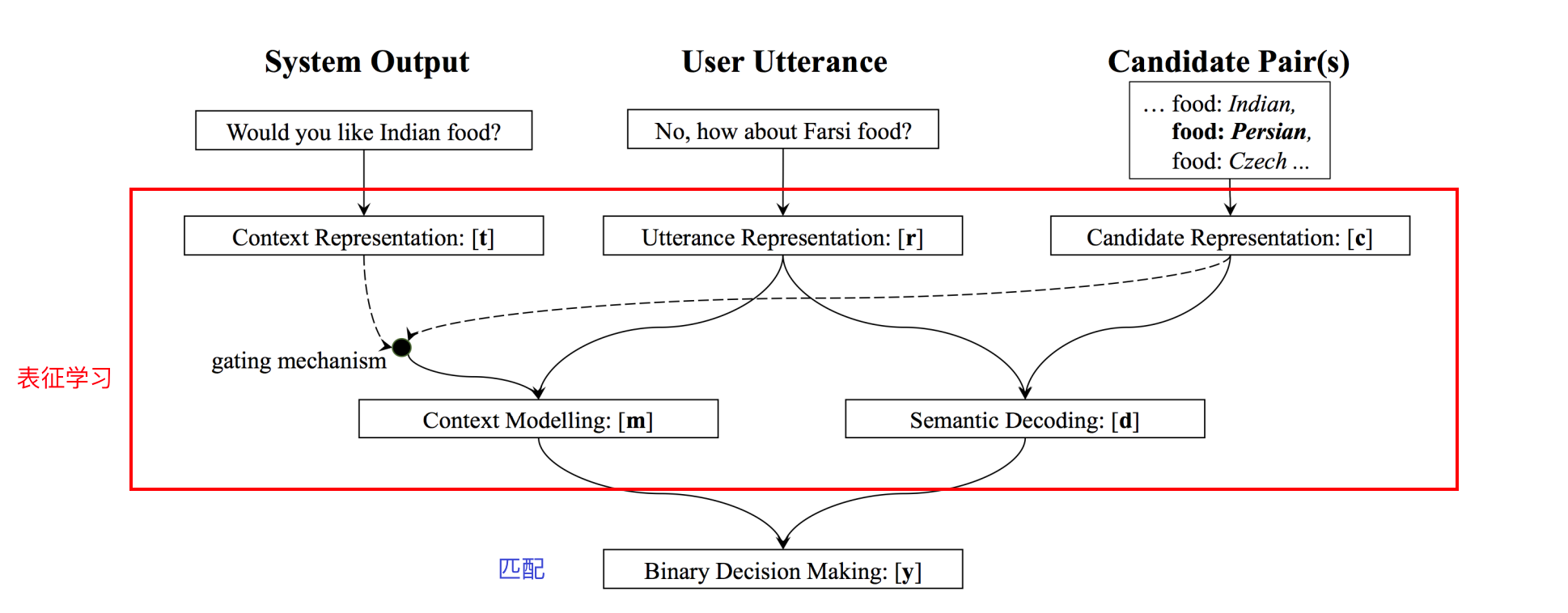
来自论文 Neural Belief Tracker: Data-Driven Dialogue State Tracking
这是一篇对话状态追踪必须了解的论文。它的做法非常优雅,把对话状态追踪任务归结成一系列的二分类任务。
对话状态追踪首先需要知道ontology,它定义有哪些槽,以及每个槽对应可能取的槽值。
NBT本质上构建了一个匹配模型(二分类模型),它接受两部分作为输入,第一部分是对话历史,第二部分的输入是各个槽和候选的取值。做槽对应所有可能的槽值次二分类,每次都得到一个输出值,选择输出值最高的。
这个模型借助分布式语义表示学习,无需人工构造的词典,使得语义表示更加精确、匹配效果更好。
但也有很多缺点:我们必须事先定义好所有可能的取值,不好扩展;采用句子级的slot-value对形式的对话状态表示,没有考虑对话历史的置信状态信息;整体的置信状态更新,采用启发式的方式。
针对上面的问题,论文 Fully Statistical Neural Belief Tracking 提出了 更好的NBT,考虑了对话历史轮次(比如上一轮)的全部slot-value的置信状态分布:
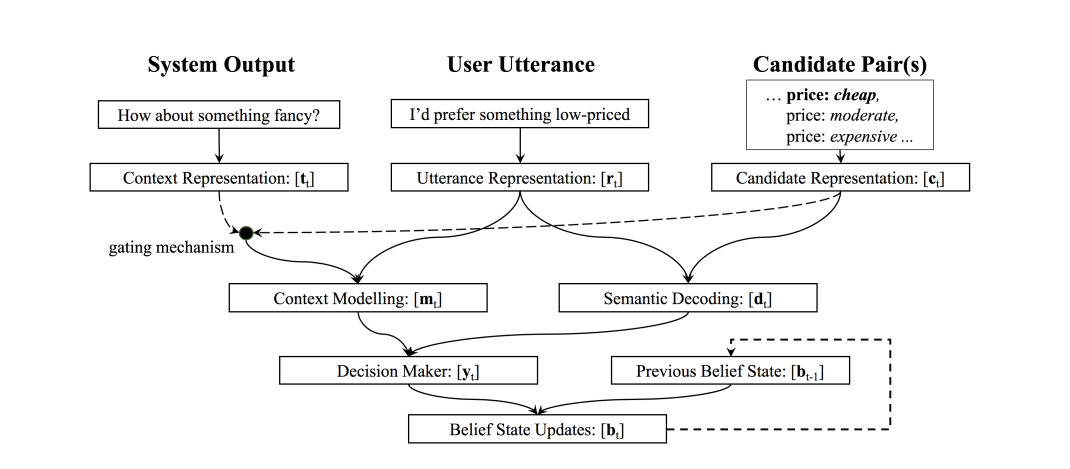
并且通过一个可学习的函数(
ϕ
\phi
ϕ)来更新每个slot对应的value。与NBT不同的是,该模型在得到匹配结果
y
t
\pmb y_t
yt之后,结合上一轮每个slot对应的value
b
s
t
−
1
\pmb b_s^{t-1}
bst−1来得到当前slot所对应的value
b
s
t
\pmb b_s^t
bst:
b
s
t
=
ϕ
(
y
s
t
,
b
s
t
−
1
)
b
s
t
=
softmax
(
W
c
u
r
r
y
s
t
+
W
p
a
s
t
b
s
t
−
1
)
\pmb b_s^t = \phi(\pmb y_s^t, \pmb b_s^{t-1}) \\ \pmb b_s^t = \text{softmax}(W_{curr} \pmb y_s^t + W_{past} \pmb b_s^{t-1})
bst=ϕ(yst,bst−1)bst=softmax(Wcurryst+Wpastbst−1)
还有一篇工作沿用NBT的想法, 针对多领域问题进行了创新:
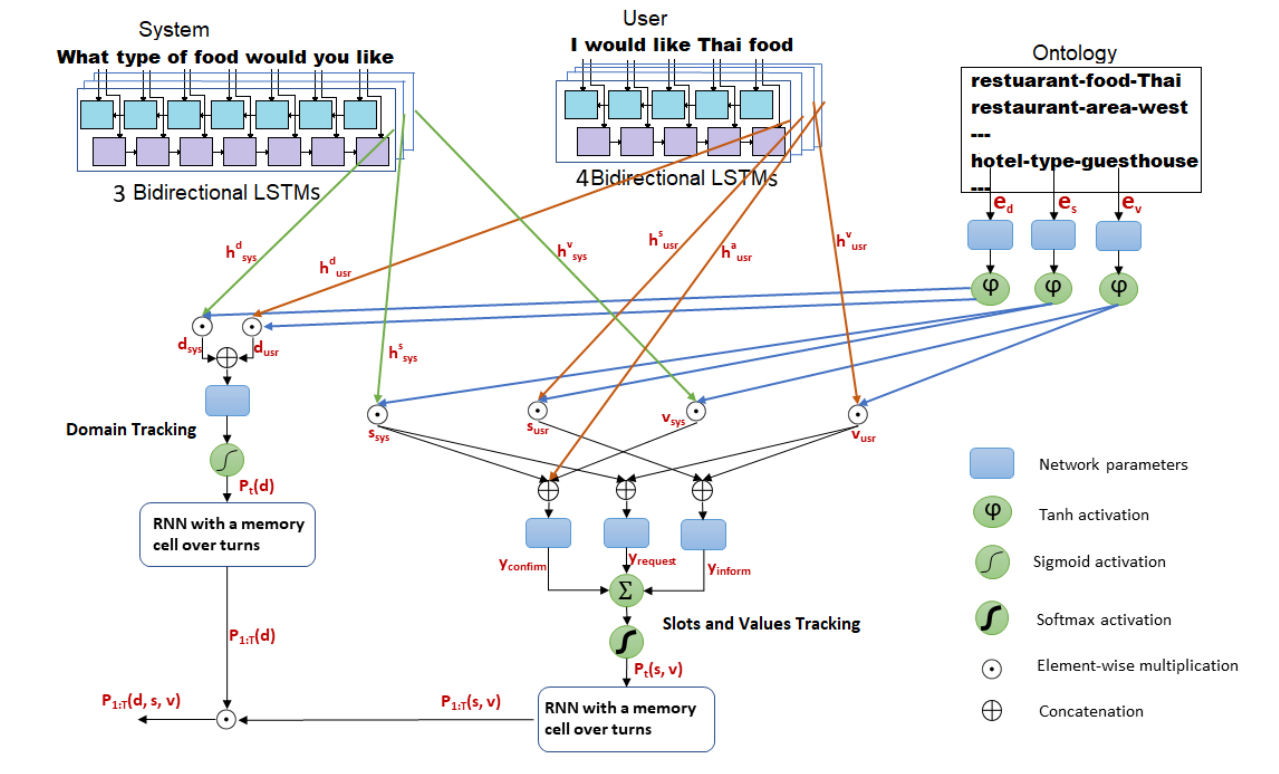
来自论文 Large-Scale Multi-Domain Belief Tracking with Knowledge Sharing
该工作提出不同领域的槽值可以共享信息:
- 比如机票、火车票等领域可以共享地点、时间等槽
- 由二元组的二分类变为三元组二分类来计算领域无关的slot-value联合概率
- 比如上图右上角的
restaurant-food-Thai
- 比如上图右上角的
上面两篇工作分别只解决了一个足部,分别是采用启发式而不是学习式的方式来更新slot-value,以及只能用到一个领域中。但都没有涉及到另外一个不足,即所有候选值来自固定的ontology。
基于NBT的一系列工作都存在的问题有:
- 通常只能得到有哪些槽,但具体的槽值往往无法得到
- 比如所有的餐馆名、人名
- 假设Ontology的存在,但实际中面临槽值太多,模型太大的问题
- 模型无法部署到不同的ontoloy的领域中
DST关心的是槽对应的值是什么,其实在对话的上下文中,这些槽值往往出现在对话历史中(比如用户可能会直接提供餐馆名信息)。那么如果能把这些槽值从用户所说的话中拷贝出来就完事了。
常用的解决方法有:
- 采用带复制机制生成的方式来预测语义槽值
- 使用slot gate来判断槽值当前是: 有效/未提及/不关心
论文 Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems 就体现了这种思想。
这篇论文使用了拷贝机制来从用户说的话中复制值到槽值中,比如下面的叫做 "Ashley Hotel"的酒店名称。
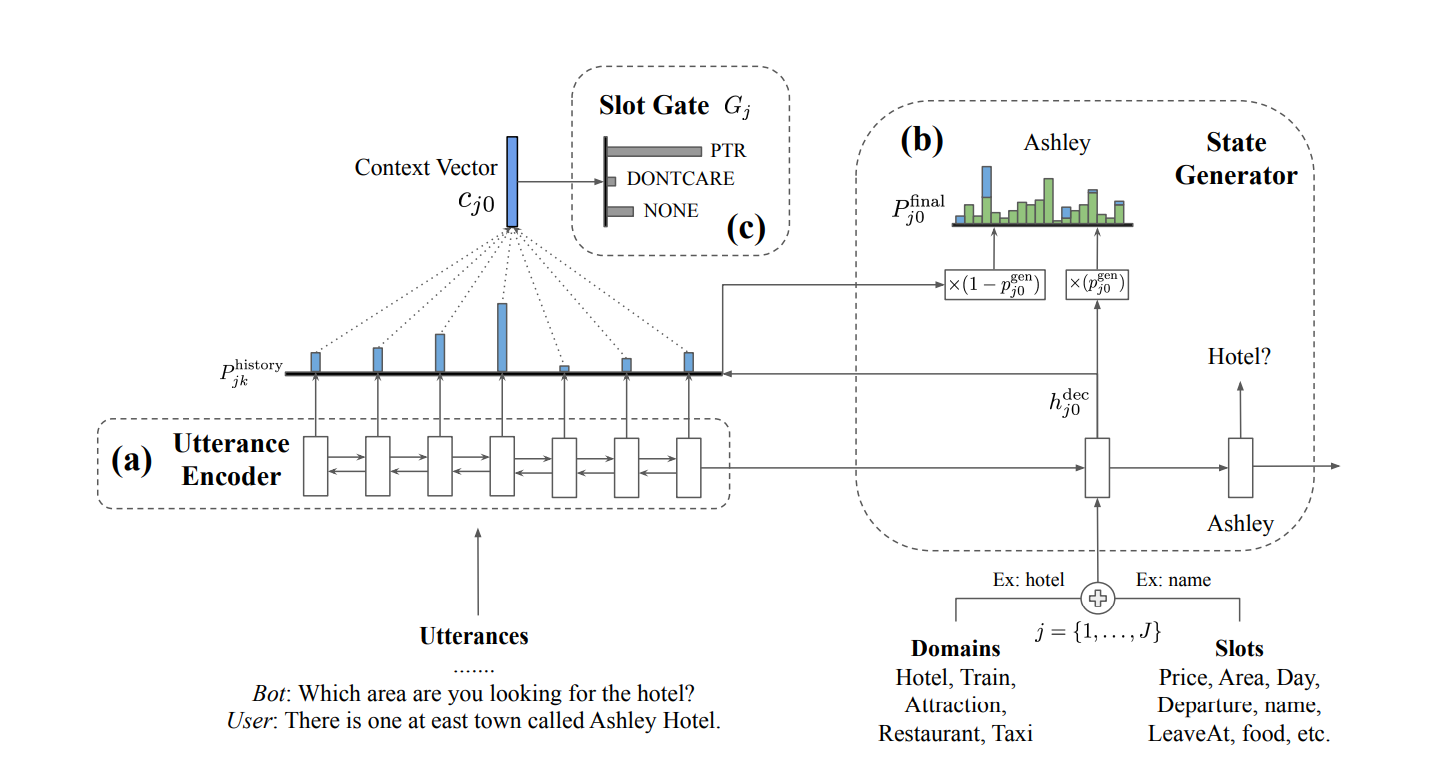
具体来说,把DST看成是seq2seq任务,根据当前的对话历史和指定的slot,试图用一个Decoder来生成slot对应的value。 在生成的过程中,显示地加上拷贝机制。
为什么这种方法是有效的呢,论文给出了一个例子:
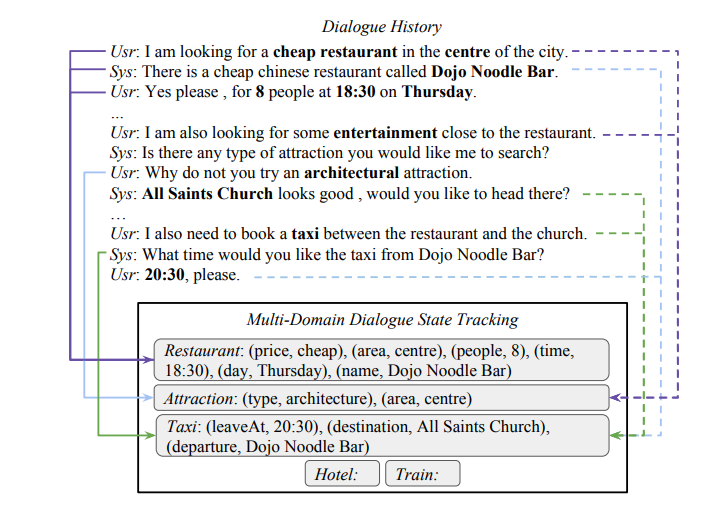
该例子想表达的是,在DST任务中,不同slot对应的value其实都出现在对话历史中,所需要做的就是通过某种方式拷贝过来。
具体的实现中,作者构建了一个模型,接收两个输入,第一个输入是对话历史,第二个输入是domain和slot的组合。输出是slot对应的value。
下面介绍一下作者是如何加入拷贝机制。
要介绍拷贝机制,不得不提到的一篇论文是 : Pointer Networks
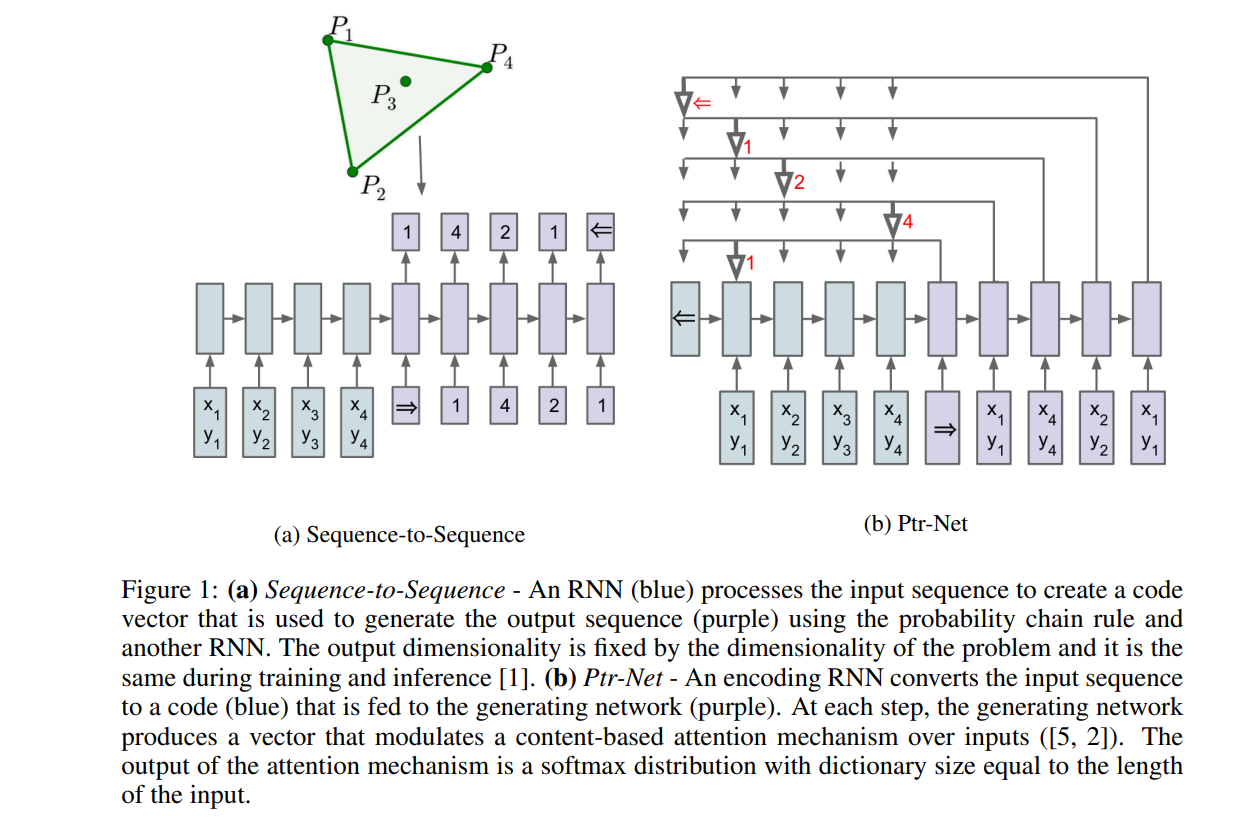
作者试图用seq2seq模型解决求凸包的问题,这里面的
x
x
x和
y
y
y不再是语句,而是点组成的序列。
这里会存在一个挑战,就是在解码的时候,不再是一个固定的词表,因为我们无法确定所处理的点有多少个。上面的例子中输入中只包含了4个点,实际也可能包含100个点。那么指针网络是如何处理这个挑战的呢?
指针网络把原来解码器在词典大小的多分类任务分解成多个二分类任务,或者说是一个匹配任务,匹配指的是使用当前时间步的隐状态对输入序列进行匹配。这样就可以解决输出序列词表大小是由输入序列所决定的问题。
这个例子中输入序列中包含4个点,那么在输出时就基于这4个点做决策,即在解码时用当前时间步隐藏状态与输入中所有点进行匹配,如果匹配到了输入中的第一个点,那么就认为输出时应该考虑第一个点。
指针网络可以为我们带来从输入序列中拷贝某些内容到输出序列的能力,这种能力对传统的seq2seq模型是非常有用的,尤其是对于机器翻译来说,因为机器翻译很多情况下输入序列中的某些词可以直接原封不动地移到输出序列中,比如对于阿拉伯数字。这种思想形成了拷贝网络(CopyNet)
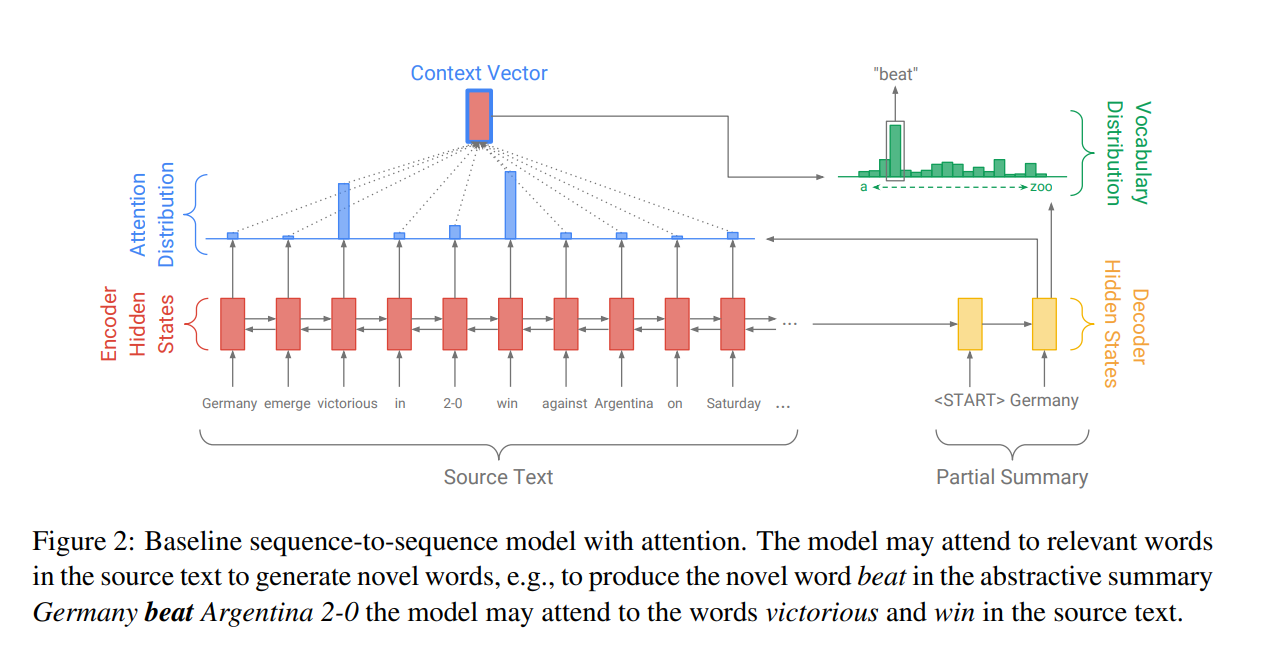
CopyNet由指针网络所启发,对于序列 X X X编码成隐向量,对于解码器来说,根据当前时间步的隐状态除了对所有的输入向量做Attention之外,还修正原来输出的概率分布(Vocabulary Distribution)。修正具体的做法是,根据当前时间步的隐状态去匹配输入序列中每个位置的词,得到一个匹配分数。根据这些分数(权重)可以得到输入中这些词的概率分布(Attention Distribution),然后这个概率分布与原来输出的概率分布进行加权平均。这样某些出现在输入序列的词,有可能被直接拷贝到输出序列中。
回到DST任务,加入拷贝机制后就可以高效地从输入中抽取需要的槽值。为了更加适应于DST任务,作者还设计了一些小的分类器来处理特殊的槽值,比如上面提到的 不关心。如果用户说餐厅的位置在哪里都可以,那么就代表不关心餐厅的具体位置。
对话策略
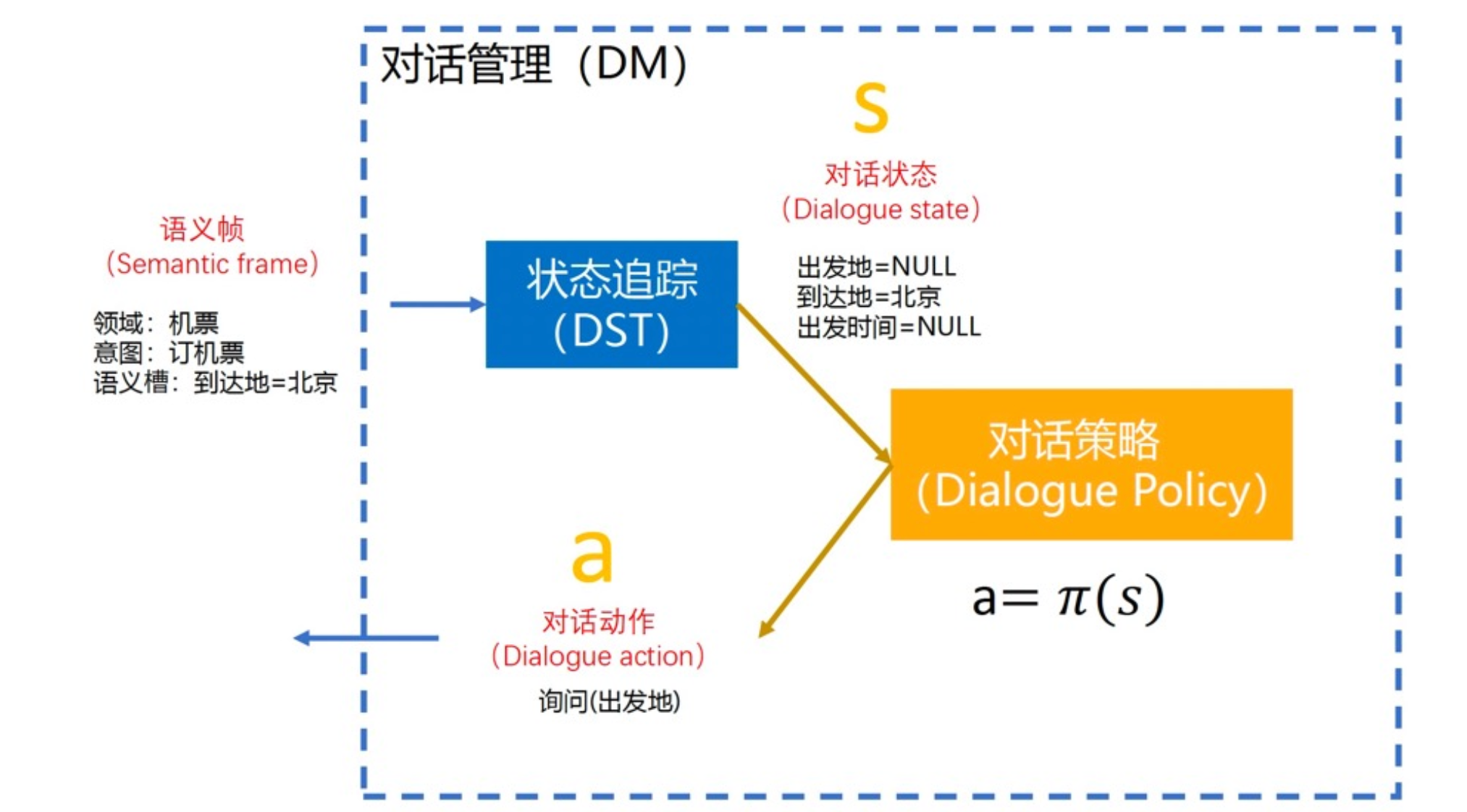
对话管理除了有状态追踪,还有对话策略。
对话策略所做的事情就是根据当前的对话状态,得到一个相应的对话动作。
对话状态就是,假设现在已知到达地,但不知道出发地,那么对话策略可能生成的对话动作就是去询问出发地。
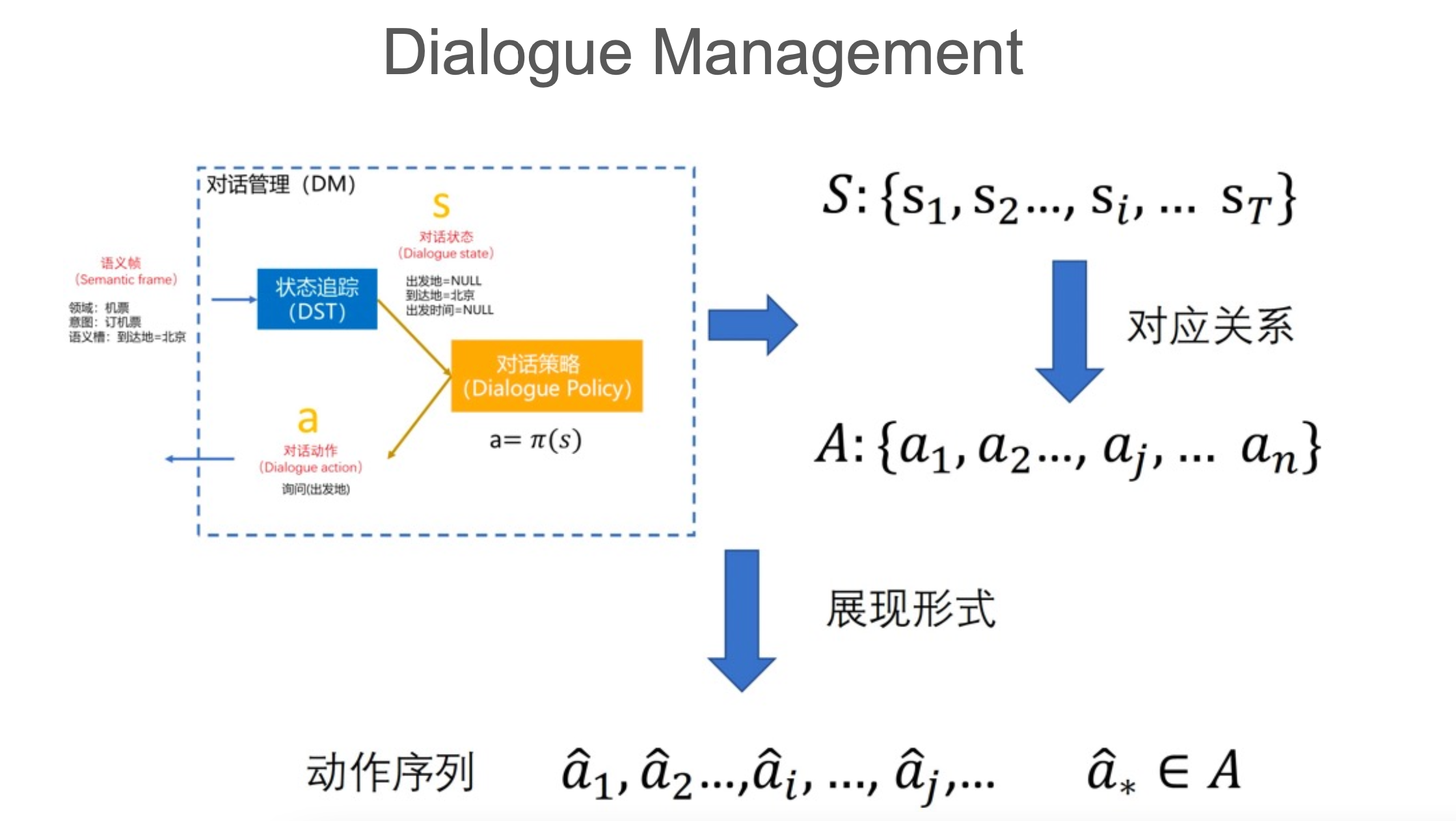
对话管理的核心其实就是对话策略,对话状态追踪的目的就是给对话策略模块使用的。
随着对话的进行,可以观察到一系列对话状态序列,对话策略需要基于这一系列对话状态序列预测出对应的相应的动作序列。
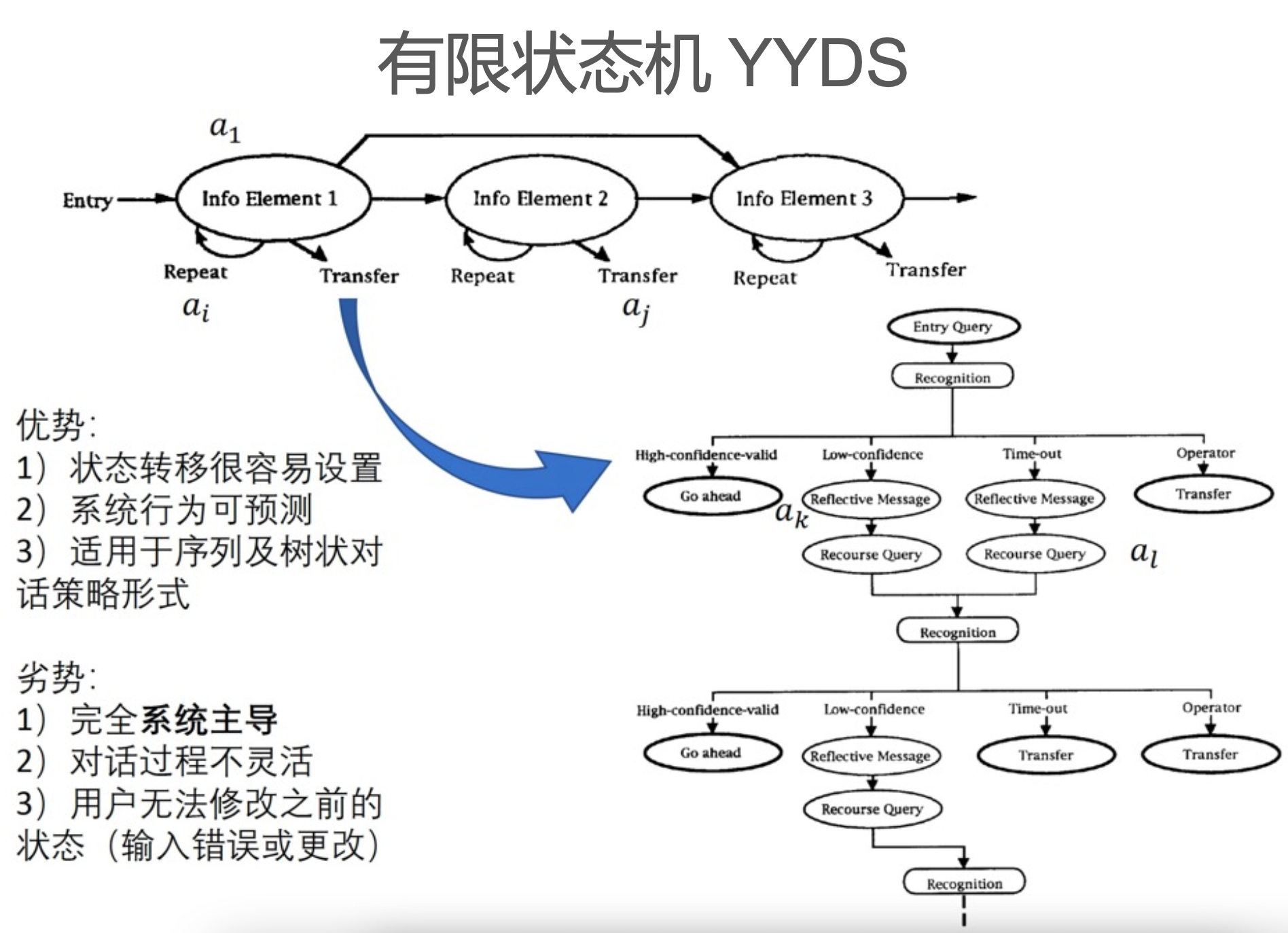
对话策略有一个很简单,并且至今还在活跃的方式——有限状态机。有限状态机可以简单地看成是一些if-else判断。这是一种基于规则的方式。
我们这里重点介绍基于强化学习的方式。
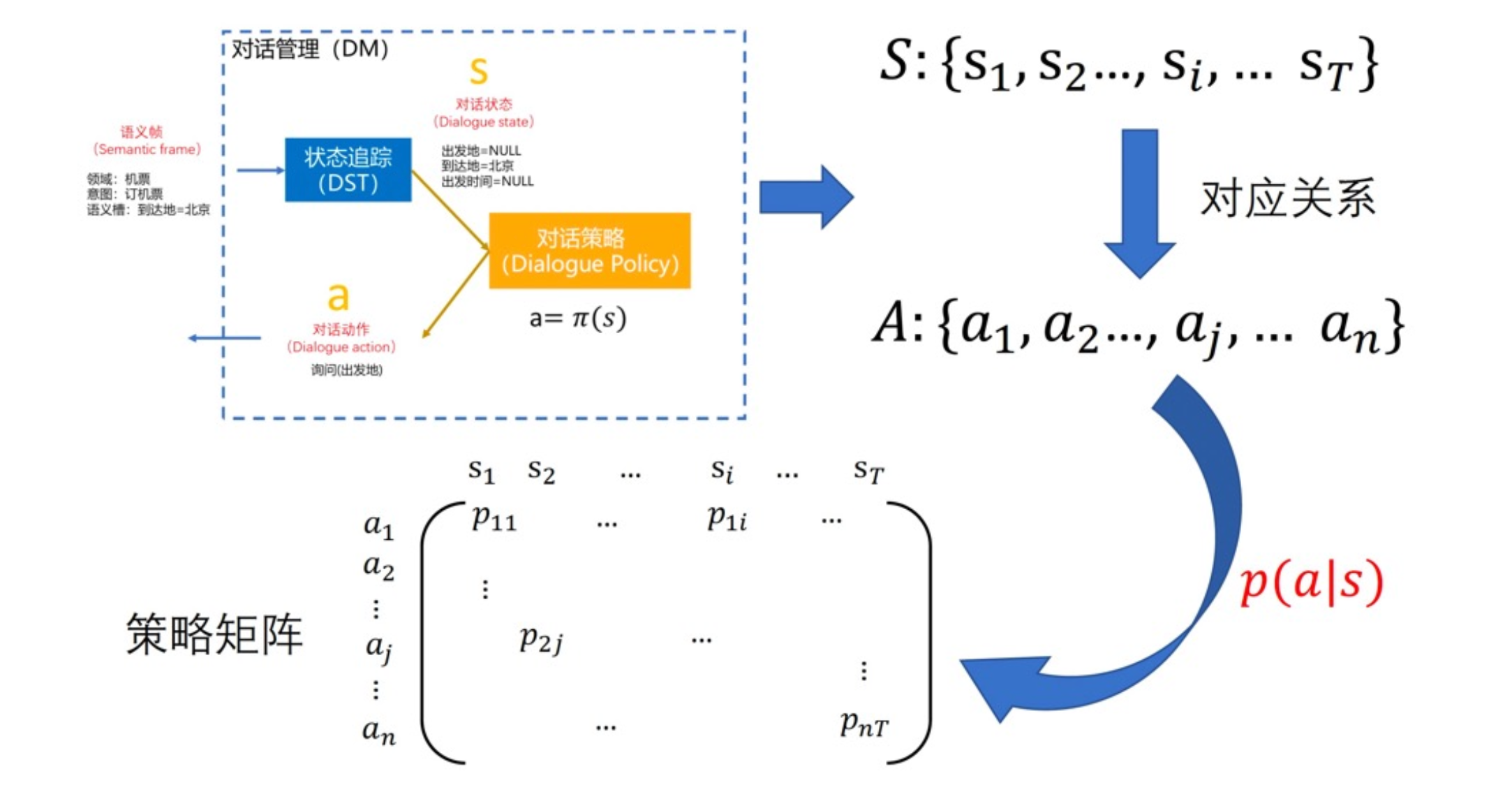
方式是寻找一个概率模型,给定一个状态,然后在所有的动作空间中预测出概率分布。
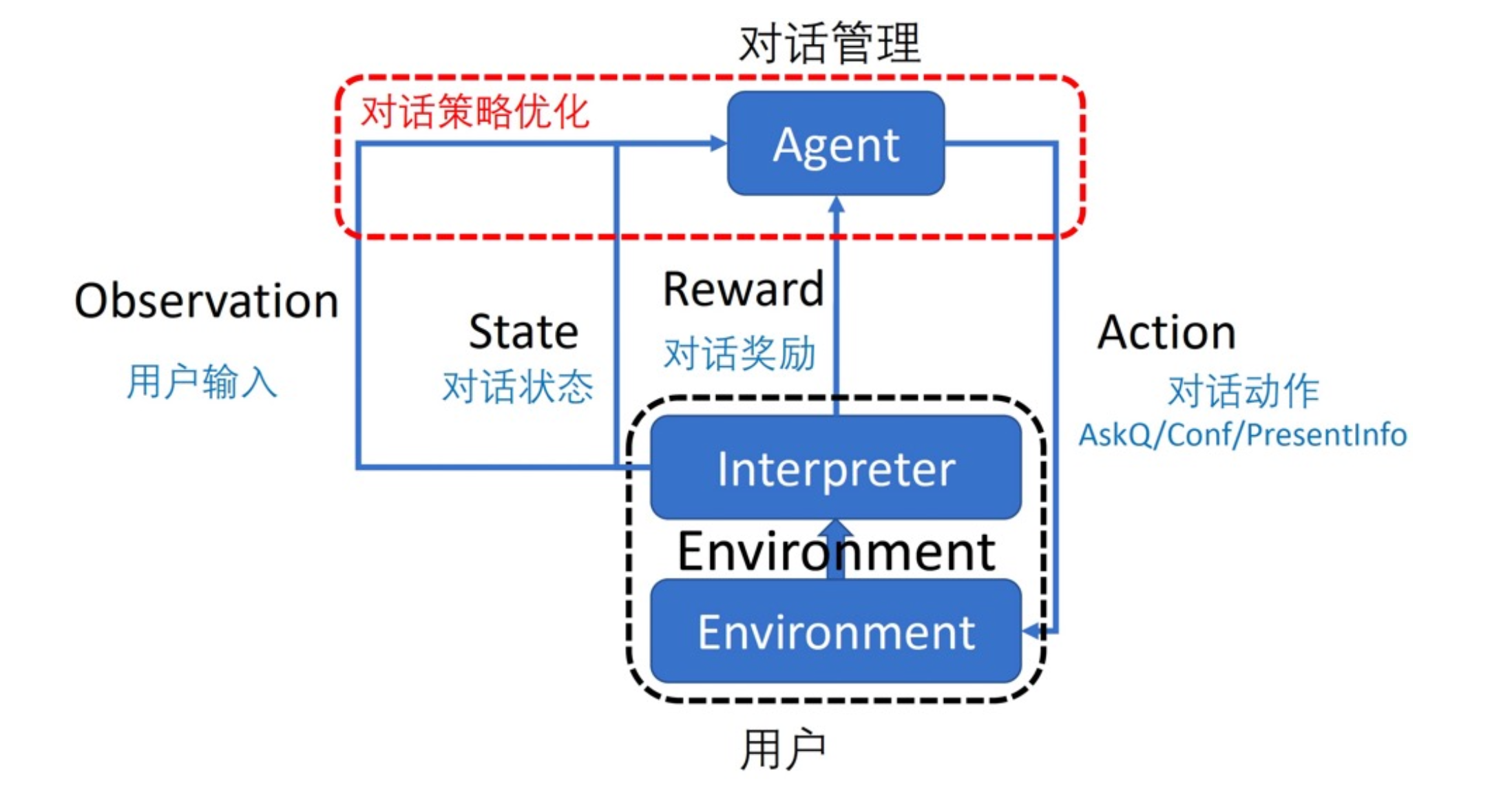
整套思想和强化学习的思想不谋而合。强化学习做对话策略的话,就是想得到一个策略函数
π
\pi
π,对于特定的状态,可以执行一个动作,强化学习的agent根据这个动作和环境进行交互可以得到反馈信号(奖励)。
我们可以把对话管理模块当成强化学习中的agent,把用户当成是交互环境,当执行了某个动作,即询问了用户某个问题后,用户会给出一些反馈。但有些反馈会延迟,比如我们可以在对话结束后让用户主动为本次对话评分;如果用户中途突然结束对话或一直请求人工,那么可以认为是负反馈。
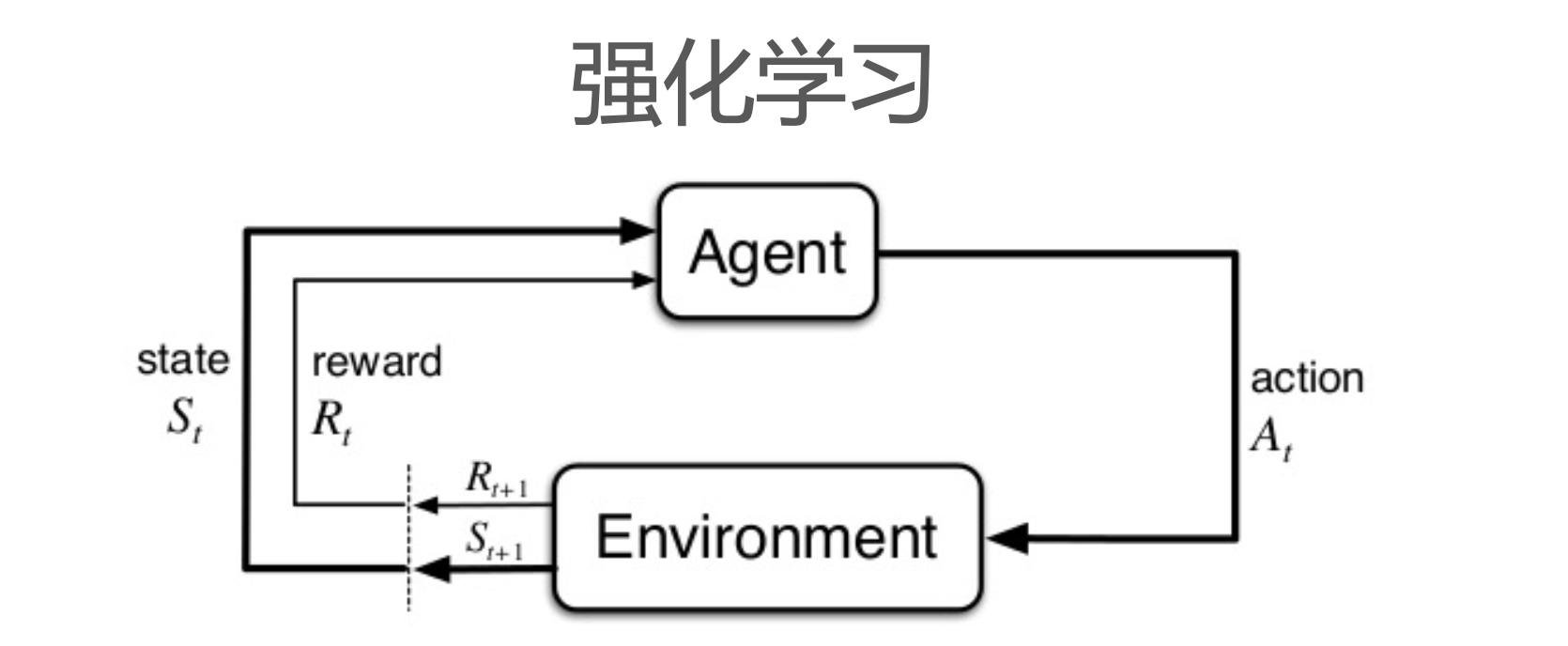
那么在强化学习中如何学习策略函数呢?
-
Agent的目标是最大化长期reward的累加值,即return;
-
但在计算时,会对未来的reward进行打折:
- G t = R t + 1 + λ R t + 2 + λ 2 R t + 3 + ⋯ G_t = R_{t+1} + \lambda R_{t+2} + \lambda^2 R_{t+3} + \cdots Gt=Rt+1+λRt+2+λ2Rt+3+⋯
-
强化学习理论推导的基石是马尔科夫性质:
- 下一时刻的状态 S t + 1 S_{t+1} St+1只与当前状态 S t S_t St和当前动作 A t A_t At有关: P [ S t + 1 ∣ S t ] = P [ S t + 1 ∣ S 1 , ⋯ , S t ] P[S_{t+1}|S_t] = P[S_{t+1}|S_1,\cdots, S_t] P[St+1∣St]=P[St+1∣S1,⋯,St]
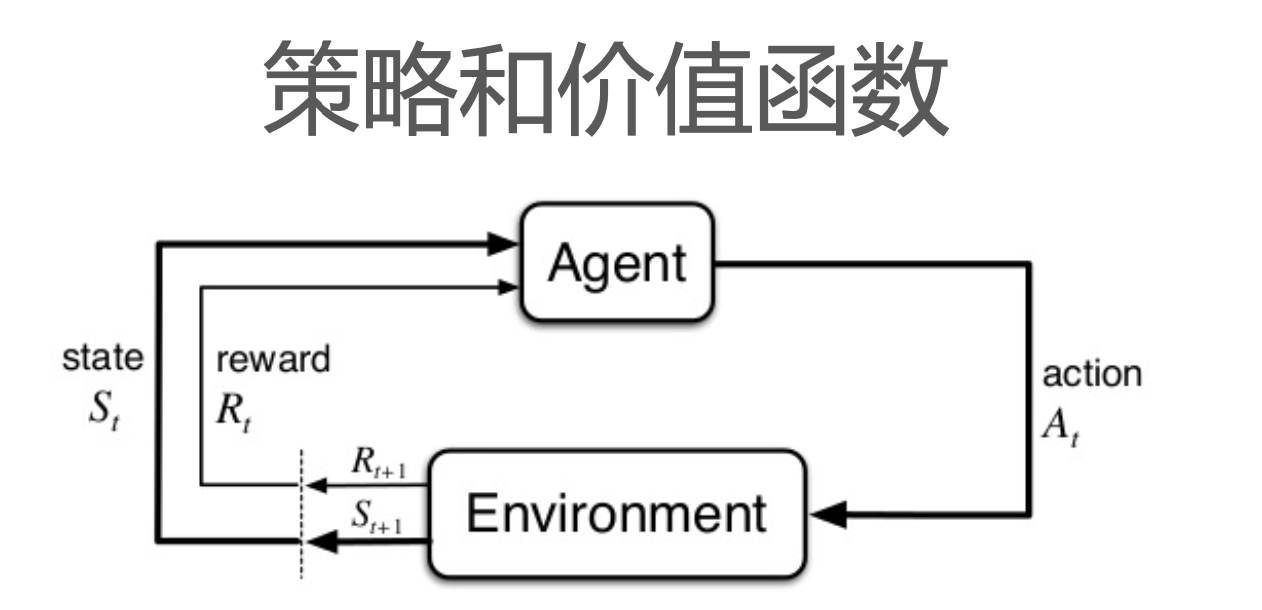
有了这个概念我们可以来理解强化学习中的三个函数:
-
策略 π \pi π告诉我们在 s s s状态时采取动作 a a a的概率:
- π ( a ∣ s ) = P π [ A = a ∣ S = s ] \pi(a|s) = P_\pi [A=a|S=s] π(a∣s)=Pπ[A=a∣S=s]
-
状态价值函数和行为价值函数计算了在状态 s s s时和进行动作 a a a的期望回报:
V π ( s ) = E π [ G t ∣ S t = s ] Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] V_\pi(s) = E_\pi [G_t|S_t=s] \\ Q_\pi(s,a) = E_\pi [G_t|S_t = s, A_t=a] Vπ(s)=Eπ[Gt∣St=s]Qπ(s,a)=Eπ[Gt∣St=s,At=a]
我们的最终目的是找到最优策略,但这是很难的,但我们可以变成找到最优动作价值函数或状态价值函数。
也可以尝试使用神经网络来建模策略函数,使用梯度下降方法优化策略函数中的参数,最大化奖励——Policy Gradient。
Policy Gradient利用参数化action来计算return,并在这基础上计算梯度。
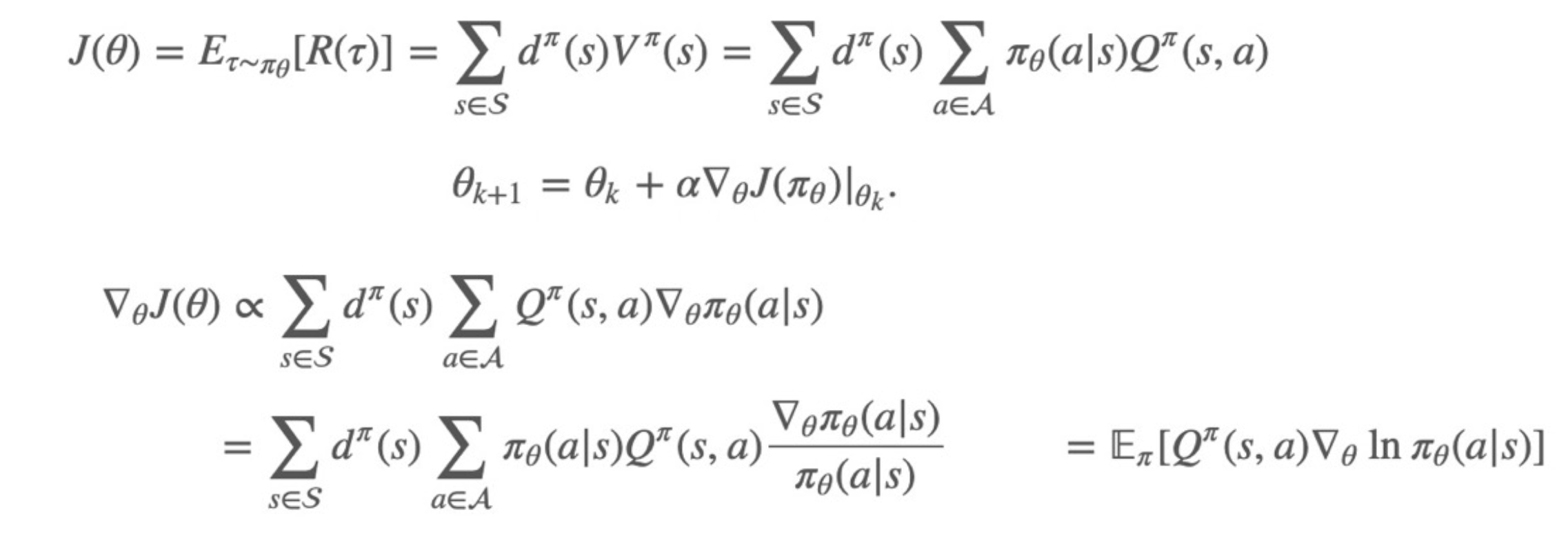
这些强化学习的内容后续会专门用一系列文章来介绍。
对话生成
落地的场景中基本都是套模板,就是每个问题设计几个问句去随机。
比较fancy的方式就是通过神经网络来生成,不过可控性不好。
端到端对话系统

端到端一个成功的尝试是通过将对话历史、对话状态、机器回应都拉成一个文本输入给GPT模型生成回复,尤其是现在ChatGPT这么火,如果输入给ChatGPT模型得到的效果会更好。
参考
- 贪心学院课程
- Structured Discriminative Model For Dialog State Tracking
- Neural Belief Tracker: Data-Driven Dialogue State Tracking ⭐
- Fully Statistical Neural Belief Tracking
- Large-Scale Multi-Domain Belief Tracking with Knowledge Sharing
- Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems ⭐
- Pointer Networks ⭐
- Get To The Point: Summarization with Pointer-Generator Networks ⭐