环境准备
安装Tesseract:点这里参考本人博客
下载第三方库
pip install Pytesseract
这个库只自带了一个英语的语言包,这个时候如果我们图片中有对中文或者其他语言的识别需求,就需要去下载其他语言包
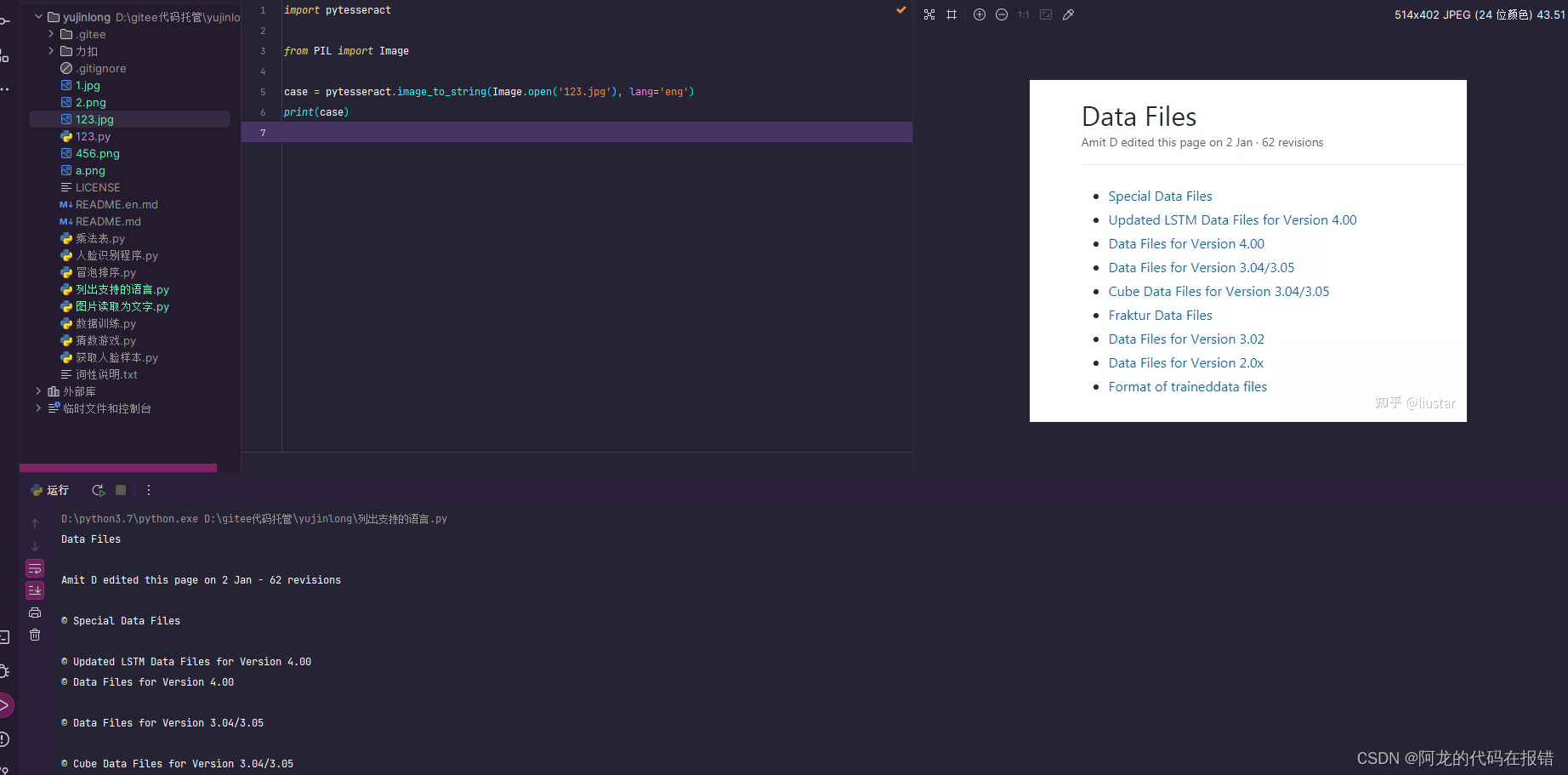
下载其他语言包
进入官网以后进入Traineddata Files

找到这个位置
tessdata_best适用于愿意以大量速度换取稍微好一点的准确性的人。它也是 唯一可用于高级用户的某些再培训方案的文件集。
tessdata 中的第三组是唯一支持旧识别器的集合。4 年 00 月的 2016.4 文件既有旧版 LSTM 模型,也有旧版 LSTM 模型。tessdata 中的当前文件集具有旧模型和较新的 LSTM 模型(tessdata_best 中 00.00.<> alpha 模型的整数版本)。
点这里直接拿传送的到github的语言包下载地址
下载完成后将traineddata文件拷贝到tesseract的安装目录下tessdata中(像这样!!!!)

小案例
输出tesseract的版本号
import pytesseract
from PIL import Image
# 输出版本号
print(pytesseract.get_tesseract_version())
结果:5.0.1.20220107
输出能够识别的语言列表
import pytesseract
from PIL import Image
# 输出版本号
print(pytesseract.get_languages())
结果:['chi_sim', 'chi_sim_vert', 'eng', 'osd']
读取中文
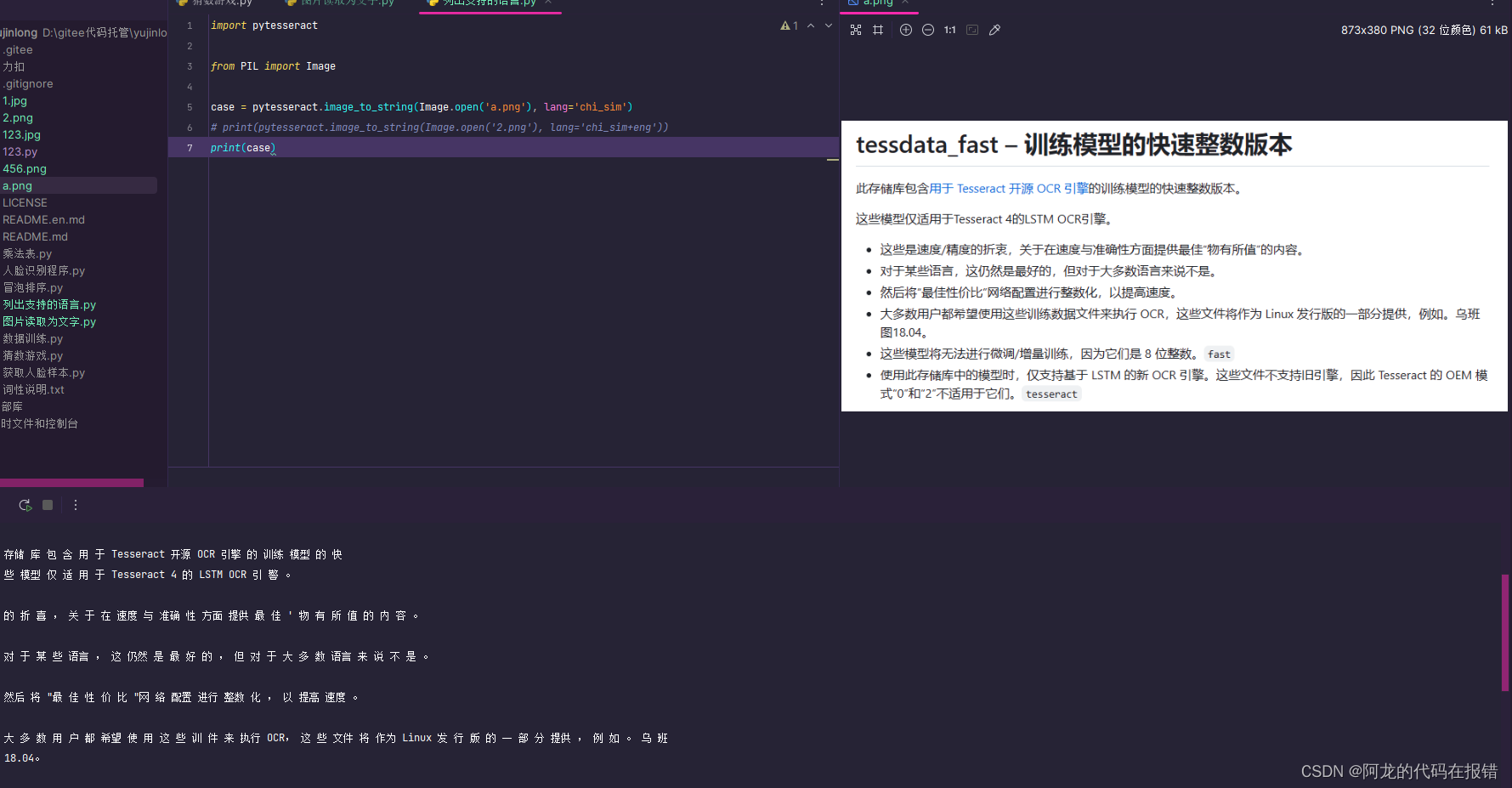
import pytesseract
from PIL import Image
case = pytesseract.image_to_string(Image.open('a.png'), lang='chi_sim')
print(case)
读取英文
import pytesseract
from PIL import Image
case = pytesseract.image_to_string(Image.open('a.png'), lang='chi_sim')
print(case)
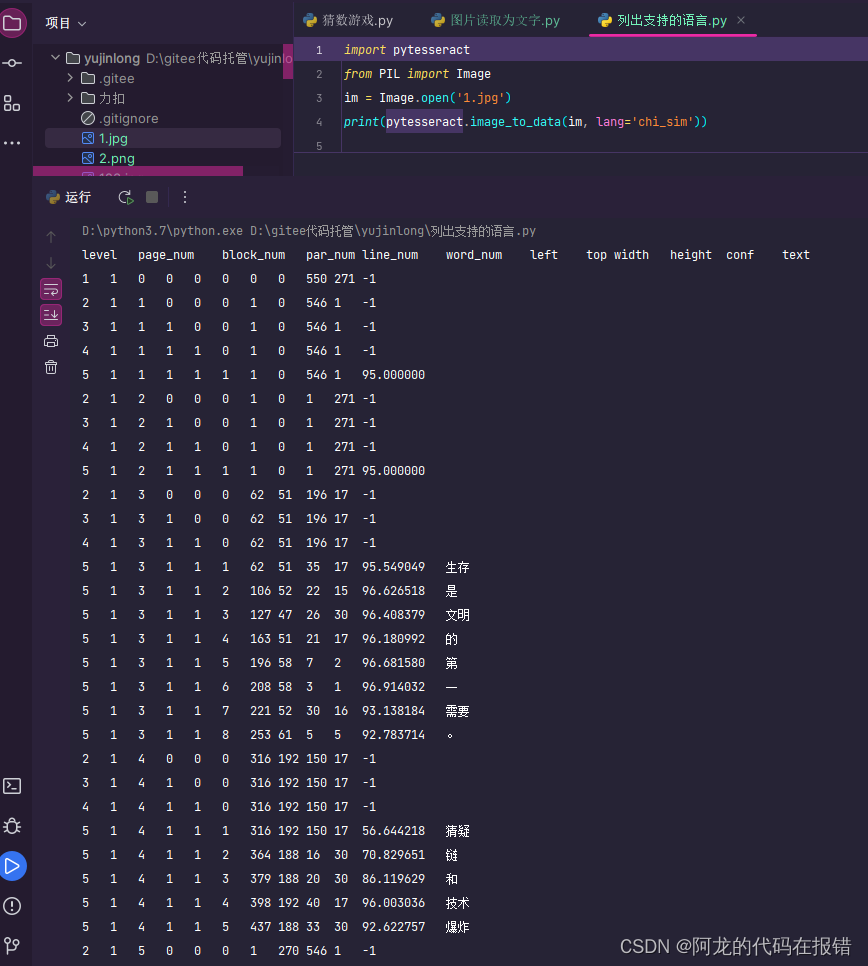
4、获取图片中文字的详细信息
image_to_data()用来获取识别出来的文字的详细信息,包含识别到的文本内容,可信度,位置等:
import pytesseract
from PIL import Image
im = Image.open('1.jpg')
获取图片中文字的详细信息
print(pytesseract.image_to_data(im, lang='chi_sim'))
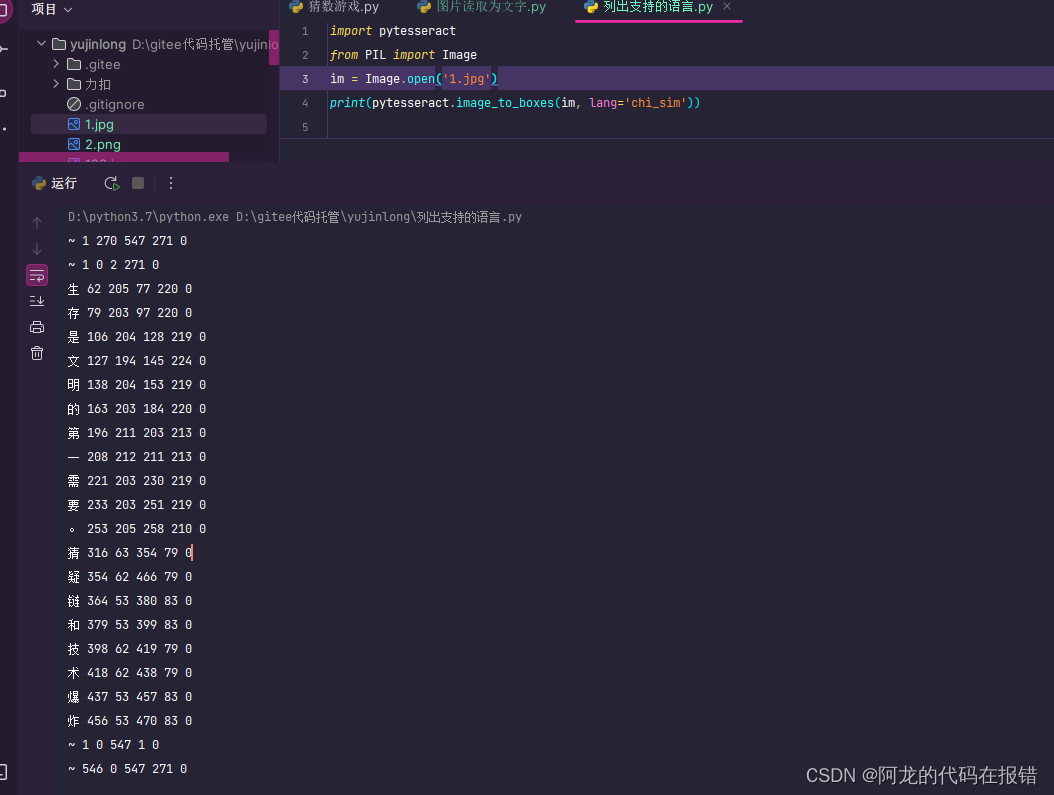
5、识别图片中的文字和位置
image_to_boxes()用来获取识别出来的文字和位置信息:
import pytesseract
from PIL import Image
im = Image.open('1.jpg')
print(pytesseract.image_to_boxes(im, lang='chi_sim'))
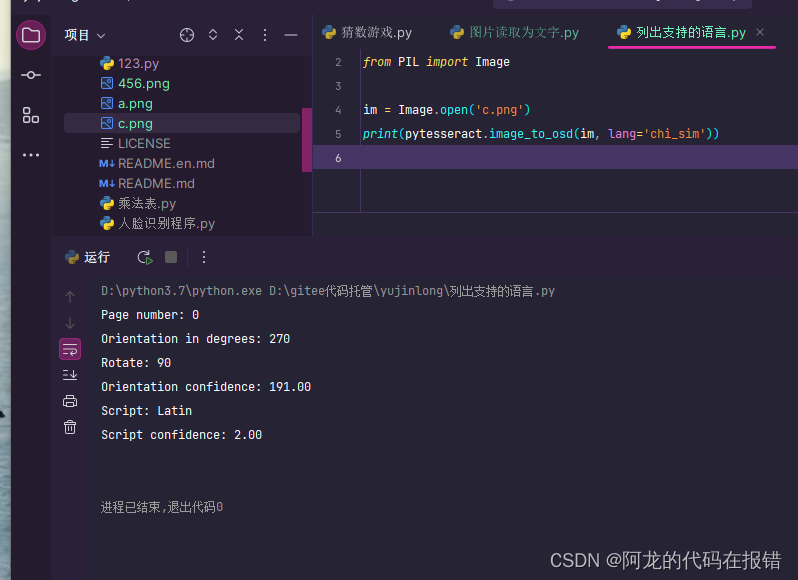
识别osd信息
image_to_osd()返回识别到的osd信息:
import pytesseract
from PIL import Image
im = Image.open('c.png')
print(pytesseract.image_to_osd(im, lang='chi_sim'))

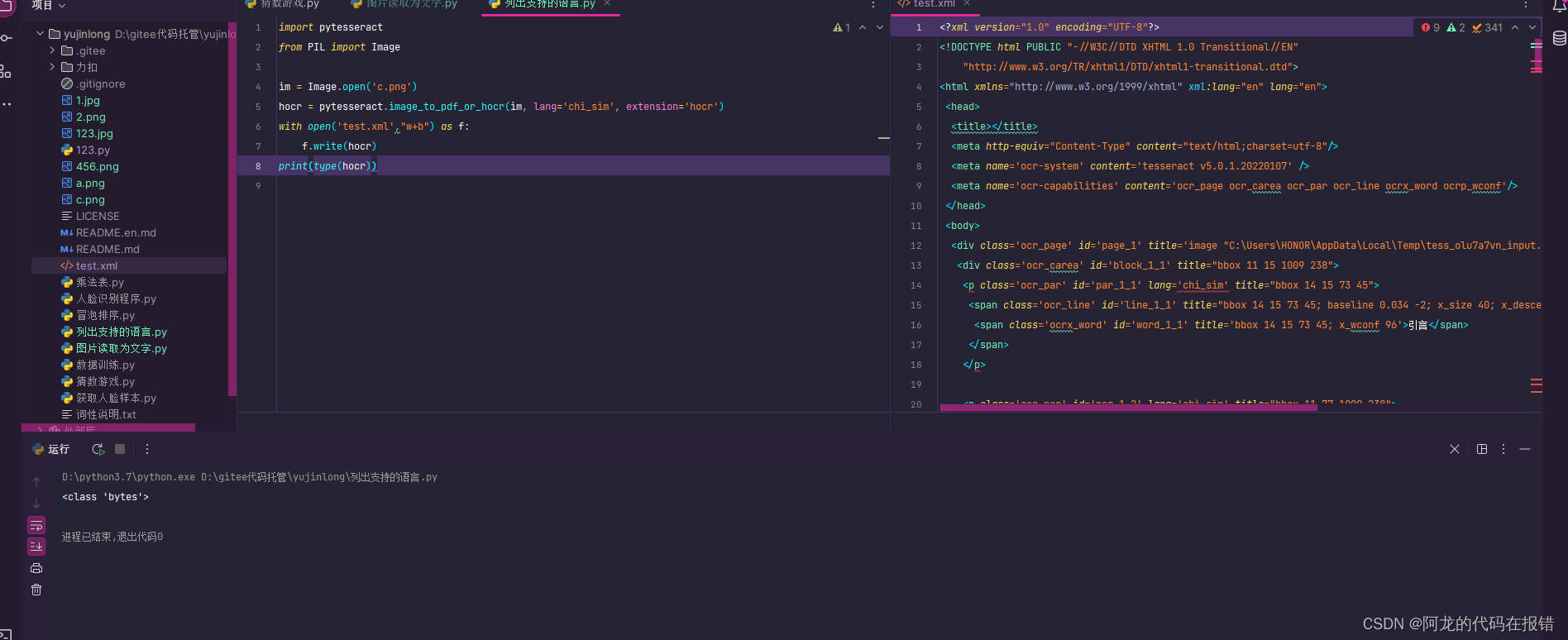
7、识别并生成xml文件
image_to_pdf_or_hocr()可以将识别的文字信息转为xml格式字节流,从而可以写入到xml文件中,其中入参extension设置为’hocr’:
import pytesseract
from PIL import Image
im = Image.open('c.png')
hocr = pytesseract.image_to_pdf_or_hocr(im, lang='chi_sim', extension='hocr')
with open('test.xml',"w+b") as f:
f.write(hocr)
print(type(hocr))