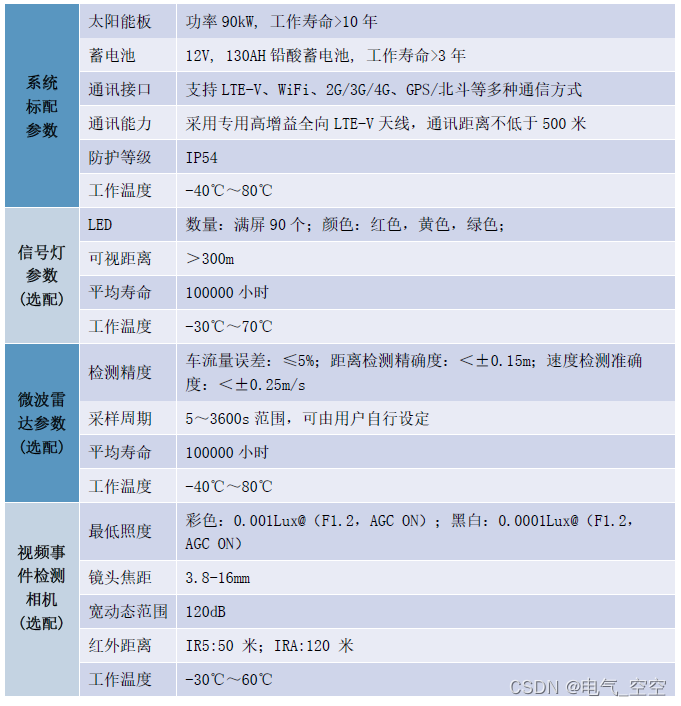
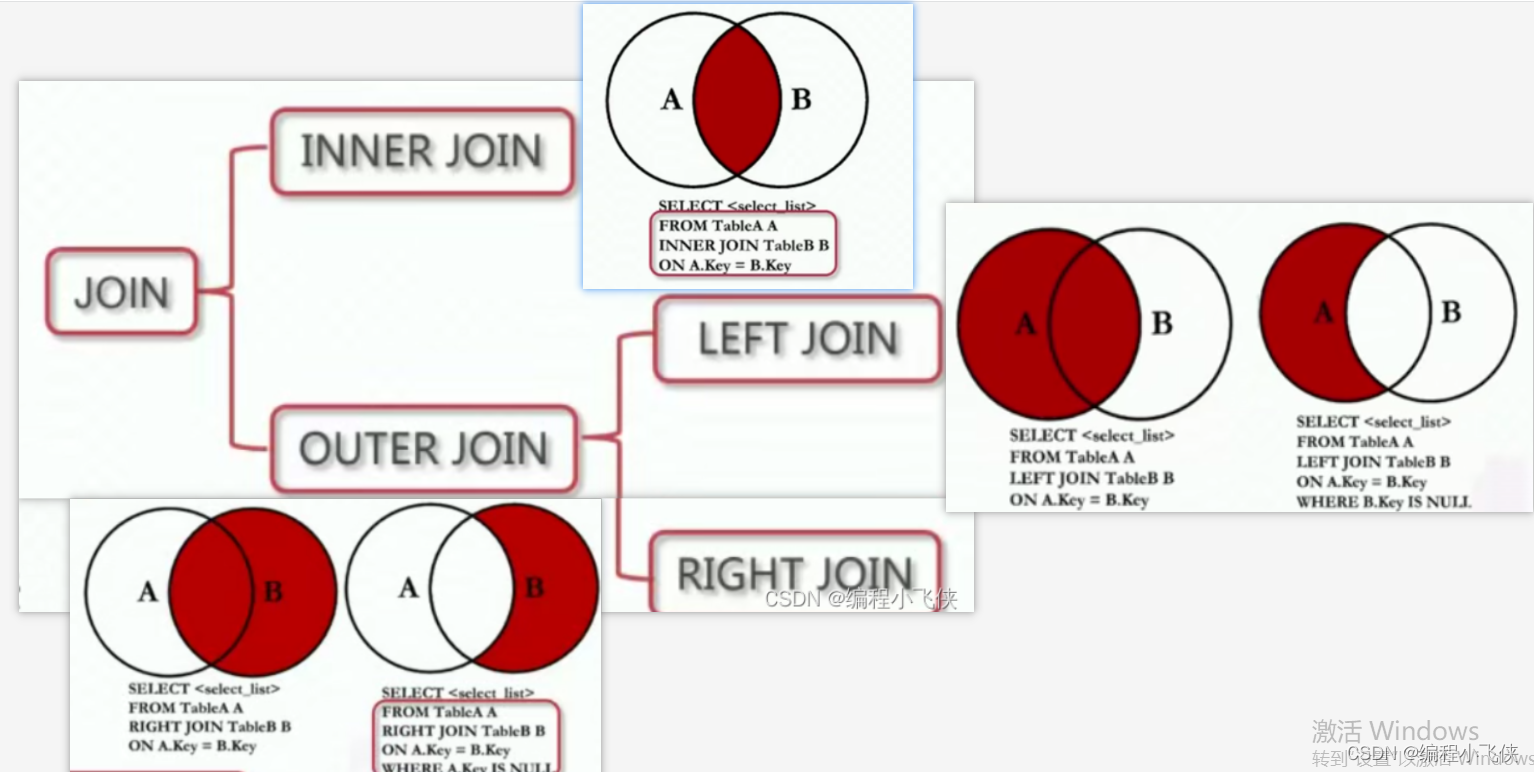
https://github.com/LiuChuang0059/100days-ML-code/blob/master/Day1_Data_preprocessing/README.md#step-6-feature-scaling—特征缩放
数据预处理
数据帧(Data Frame) 二维的表格形式,类似于电子表格或关系型数据库中的表。数据帧通常被用来存储和操作结构化数据。数据以行和列的形式组织。每一列代表一个变量,每一行代表一个观察或数据点。
例子:
data = {
'Name': ['John', 'Emma', 'Mike', 'Lisa'],
'Age': [28, 24, 32, 29],
'City': ['New York', 'San Francisco', 'Chicago', 'Los Angeles']
}
df = pd.DataFrame(data)
# 打印数据帧
print(df)
# 输出:
# Name Age City
# 0 John 28 New York
# 1 Emma 24 San Francisco
# 2 Mike 32 Chicago
# 3 Lisa 29 Los Angeles
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 6 02:15:40 2018
@author: liuchuang
"""
### Step 1: Importing the libraries
import numpy as np
import pandas as pd
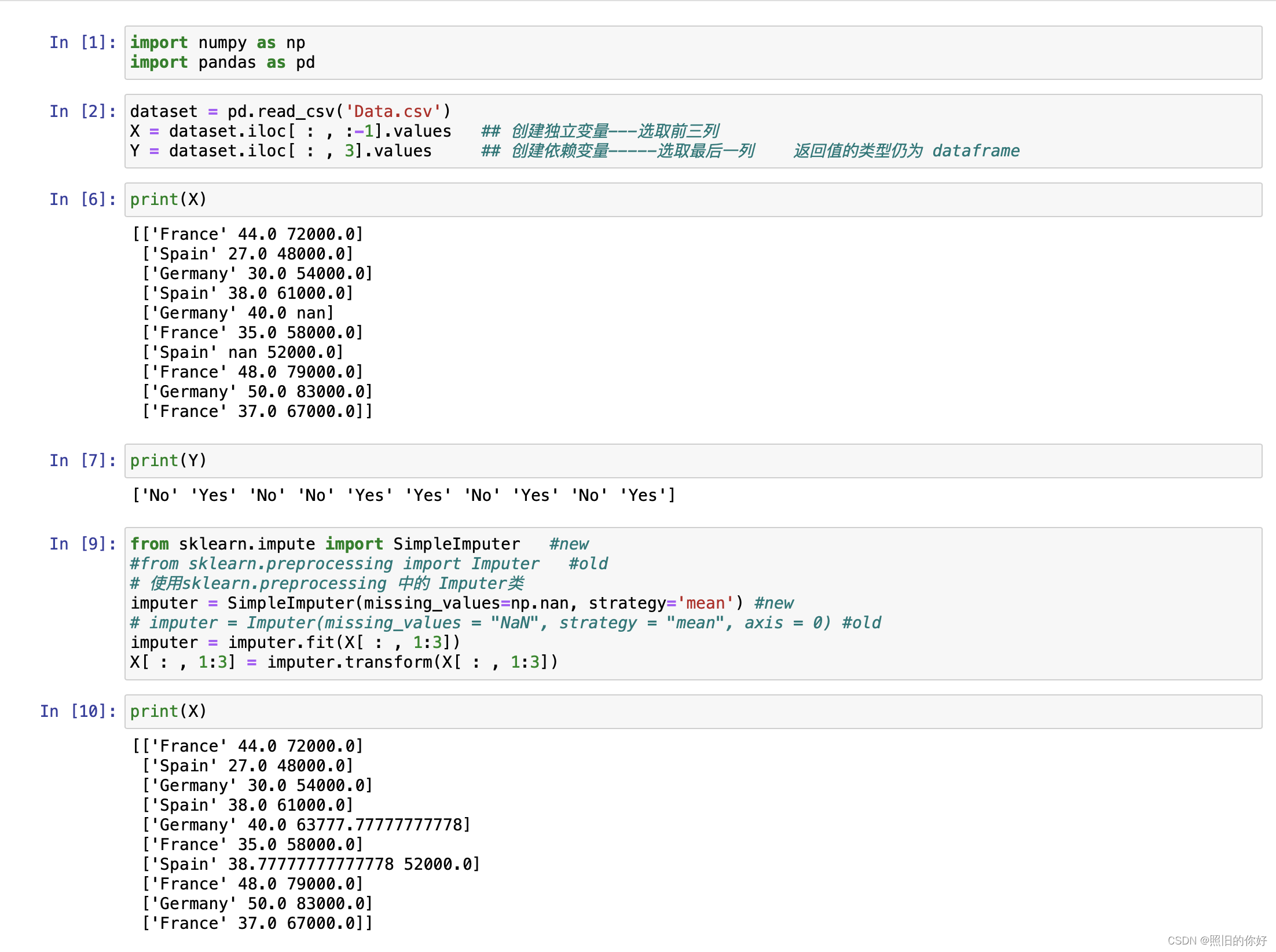
### Step 2: Importing dataset
dataset = pd.read_csv('Data.csv')
# iloc 方法的索引是基于位置的,而不是基于标签的
X = dataset.iloc[ : , :-1].values
# 使用 Pandas 库中的 iloc 方法从数据集中提取特征(自变量)的部分
# 通过 iloc 方法可以按照索引位置来选择数据。
# 在这里,: 表示选择所有的行,-1 表示选择除了最后一列之外的所有列。
# .values 用于将结果转换为 NumPy 数组
Y = dataset.iloc[ : , 3].values #选择索引为 3 的列
### Step 3: Handling the missing data
### 使用整列的中位数或者平均值表示缺失值
from sklearn.impute import SimpleImputer #new
#from sklearn.preprocessing import Imputer #old-教程里的
# 从 Scikit-learn 0.22 版本开始,Imputer 类已被 SimpleImputer 类取代
# 使用sklearn.preprocessing 中的 Imputer类
imputer = SimpleImputer(missing_values=np.nan, strategy='mean') #new
# 使用均值mean来填充缺失值,其他方法: median(中位数)、most_frequent(最频繁值)
# imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0) #old
imputer = imputer.fit(X[ : , 1:3])
# 使用 fit 方法将 SimpleImputer 对象适应(fit)到数据集的指定列
# X[:, 1:3] 表示选取数据集 X 的所有行(:),以及列索引为 1 到 2(不包括索引 3)的列(1:3)
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
# 使用 transform 方法将填充后的数据替换原始数据集中指定的列
# imputer 对象将使用之前计算得到的填充信息来填充 X 数据集中选定的列,将缺失值替换为填充值
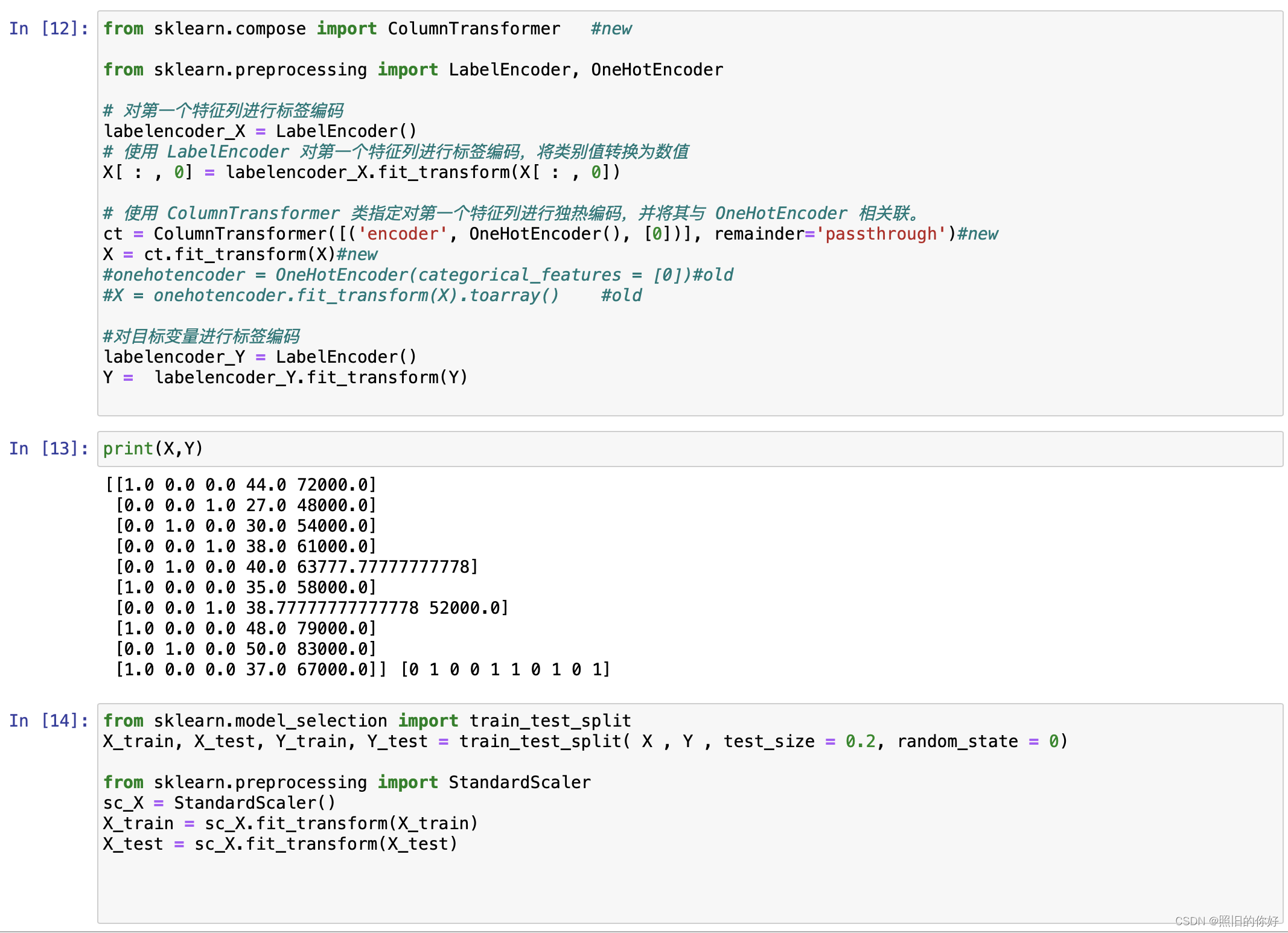
### step4: Encoding categorical data
from sklearn.compose import ColumnTransformer #new
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# 对第一个特征列进行标签编码
labelencoder_X = LabelEncoder()
# 使用 LabelEncoder 对第一个特征列进行标签编码,将类别值转换为数值
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
# 使用 ColumnTransformer 类指定对第一个特征列进行独热编码,并将其与 OneHotEncoder 相关联。
ct = ColumnTransformer([('encoder', OneHotEncoder(), [0])], remainder='passthrough')#new
X = ct.fit_transform(X)#new
#onehotencoder = OneHotEncoder(categorical_features = [0])#old
#X = onehotencoder.fit_transform(X).toarray() #old
# 使用 ColumnTransformer 来代替过时的 categorical_features 参数,以实现对指定列的独热编码
#对目标变量进行标签编码
labelencoder_Y = LabelEncoder() #使用 LabelEncoder 对目标变量进行标签编码
Y = labelencoder_Y.fit_transform(Y)
### Step 5: Splitting the datasets into training sets and Test sets
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
# 数据集分成训练集和测试集
# 分的比例通常 8:2
# 使用sklearn.cross_validation 中 train_test_split 类
### Step 6: Feature Scaling---特征缩放
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)
# 使用欧几里得距离
# 特征与 标度有关,一个特征比其他的特征范围更大 该特征值成为主导