在多线程中使用哈希表, 首先是不能使用HashMap的. 因为其本身并非线程安全. 与其相反HashTable则是安全的. 其原因在于本身给关键的方法加了锁. 但即便如此, 与HashTable相比, 更推荐使用ConcurrentHashMap. 其原因在于, 它在HashTable的基础上做了较多的优化:
上述提到, HashTable线程安全的前提是加锁. 但其加锁是对方法加锁. 这意味着其加锁对象是this, 加了一把大锁.

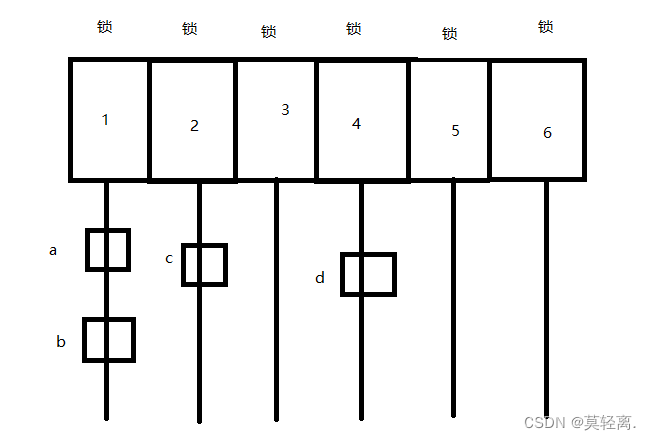
如图所示, 在这个哈希表中, 假设有两个线程要对key为1的链表中的a, b进行增删查改. 很显然, 若不进行加锁, 就会引发线程安全. 因此当其中一个线程访问时, 整个哈希表都相当于加了一个大锁, 进而防止线程安全.
但如果两个线程访问的是c和d呢? 很显然这个时候其实无需加锁. 因为二者根本是在不同的链表上的. 在这种情况下加锁毫无意义. 二者访问根本不会收到影响. 只会白白因为加锁而浪费资源和时间.
因此, ConcurrentHashMap优化的第一个地方就是将这个大锁进行细化. 在JDK1.8以前, 是将哈希表数组中的每几个进行上锁. 但是这样效果并不好, 之后就直接进行单独加锁. 即将每个链表的头结点作为加锁对象. 这样既可以保证访问同一个链表时加锁, 不同链表之间也能有效同时进行访问.
ConcurrentHashMap第二个优化的地方是其只针对写操作加锁. 也就是说ConcurrentHashMap的读和写之间是没有冲突的. 换句话说, 完全可能存在脏读. 读到只写完一半的数据. 为避免出现这种情况, ConcurrentHashMap使用如volatile和代码的控制以实现原子性.
同时ConcurrentHashMap也尽量多使用了CAS, 以减少加锁次数. 但无论如何, 其效率的提升也不过是相对的.
ConcurrentHashMap第三个优化的地方是扩容. 哈希表的扩容是put操作使其元素数量达到所规定的负载因子时, 会创建一个更大的数组空间将旧数组中的所有数据搬运过去. 但问题在于, 如果数据量本身很大, 那这个搬运过程是极其耗时耗力的. 很可能出现运行卡顿.
ConcurrentHashMap所采用的也是化大为小进行搬运. 在进行扩容后, 会将新旧数组同时进行保留.每次put就将数据放到新数组中, 同时也从旧数组中搬运一部分到新数组中. 如此反复, 最后搬运结束. 这样搬运避免一次性搬运过多的数据而造成卡顿.
-------------------------------最后编辑于2023.7.3 晚上八点半左右