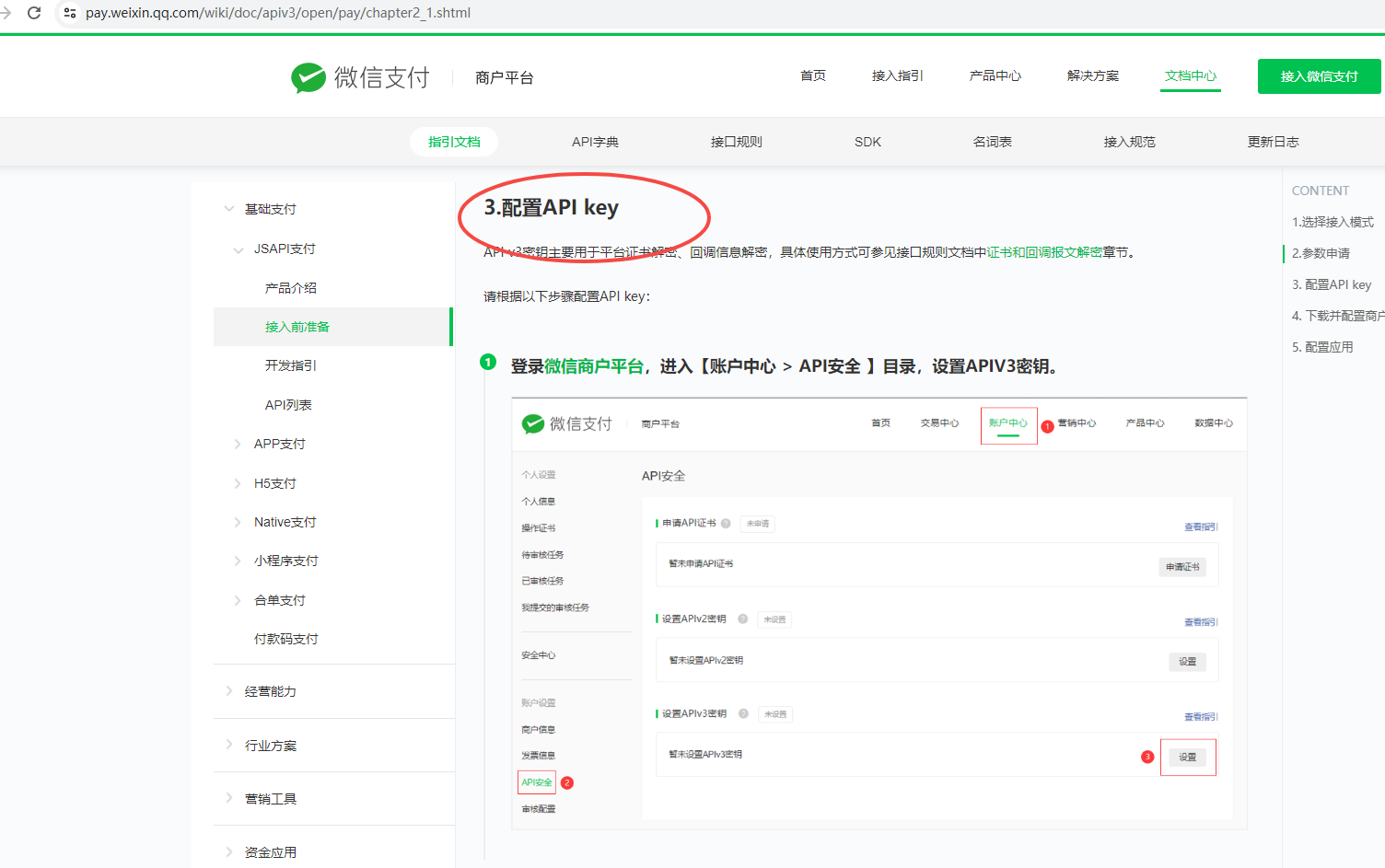
前段时间,同事在代码中 KW 扫描的时候出现这样一条:
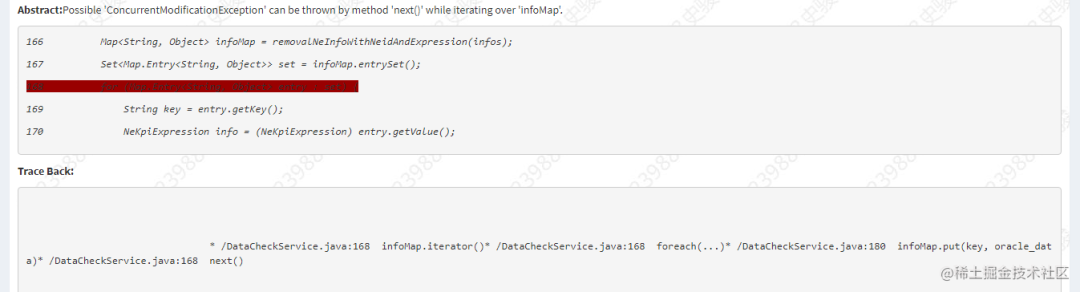
上面出现这样的原因是在使用 foreach 对 HashMap 进行遍历时,同时进行 put 赋值操作会有问题,异常 ConcurrentModificationException。
于是帮同简单的看了一下,印象中集合类在进行遍历时同时进行删除或者添加操作时需要谨慎,一般使用迭代器进行操作。
于是告诉同事,应该使用迭代器 Iterator 来对集合元素进行操作。同事问我为什么?这一下子把我问蒙了?对啊,只是记得这样用不可以,但是好像自己从来没有细究过为什么?
于是今天决定把这个 HashMap 遍历操作好好地研究一番,防止采坑!
foreach 循环?
Java foreach 语法是在 JDK 1.5 时加入的新特性,主要是当作 for 语法的一个增强,那么它的底层到底是怎么实现的呢?下面我们来好好研究一下:
foreach 语法内部,对 collection 是用 iterator 迭代器来实现的,对数组是用下标遍历来实现。Java 5 及以上的编译器隐藏了基于 iteration 和数组下标遍历的内部实现。
注意:这里说的是“Java 编译器”或 Java 语言对其实现做了隐藏,而不是某段 Java 代码对其实现做了隐藏,也就是说,我们在任何一段 JDK 的 Java 代码中都找不到这里被隐藏的实现。这里的实现,隐藏在了Java 编译器中,查看一段 foreach 的 Java 代码编译成的字节码,从中揣测它到底是怎么实现的了。
我们写一个例子来研究一下:
public class HashMapIteratorDemo {String[] arr = {"aa","bb","cc"};public void test1() {for (String str: arr) {}}}
将上面的例子转为字节码反编译一下(主函数部分):
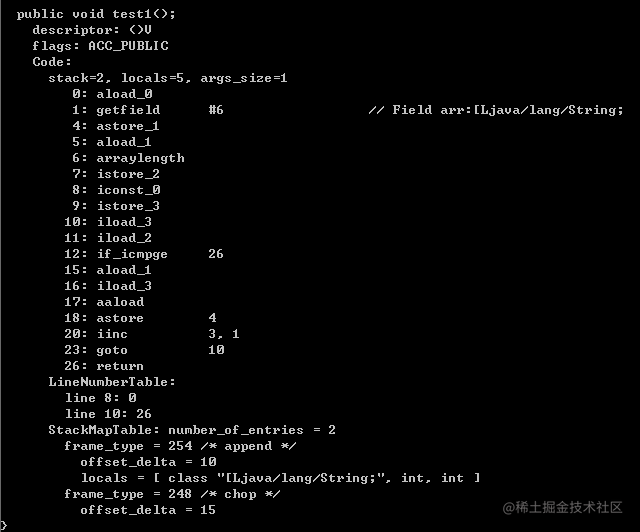
也许我们不能很清楚这些指令到底有什么作用,但是我们可以对比一下下面段代码产生的字节码指令:
public class HashMapIteratorDemo2 {String[] arr = {"aa","bb","cc"};public void test1() {for (int i = 0; i < arr.length; i++) {String str = arr[i];}}}
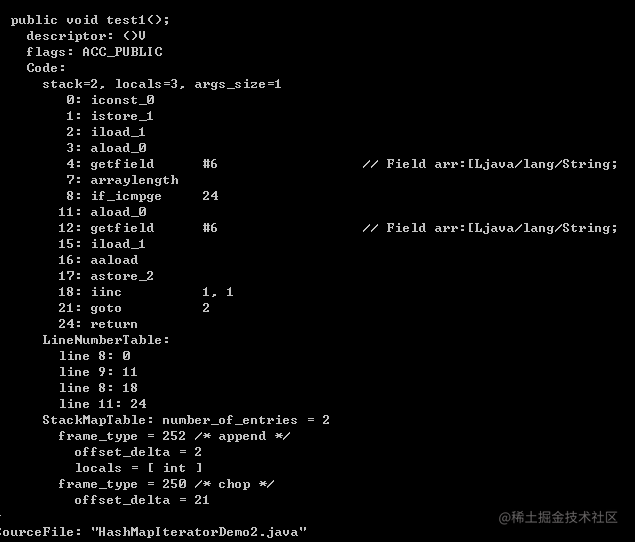
看看两个字节码文件,有木有发现指令几乎相同,如果还有疑问我们再看看对集合的 foreach 操作:
通过 foreach 遍历集合:
public class HashMapIteratorDemo3 {List < Integer > list = new ArrayList < > ();public void test1() {list.add(1);list.add(2);list.add(3);for (Integervar: list) {}}}
通过 Iterator 遍历集合:
public class HashMapIteratorDemo4 {List < Integer > list = new ArrayList < > ();public void test1() {list.add(1);list.add(2);list.add(3);Iterator < Integer > it = list.iterator();while (it.hasNext()) {Integervar = it.next();}}}
将两个方法的字节码对比如下:
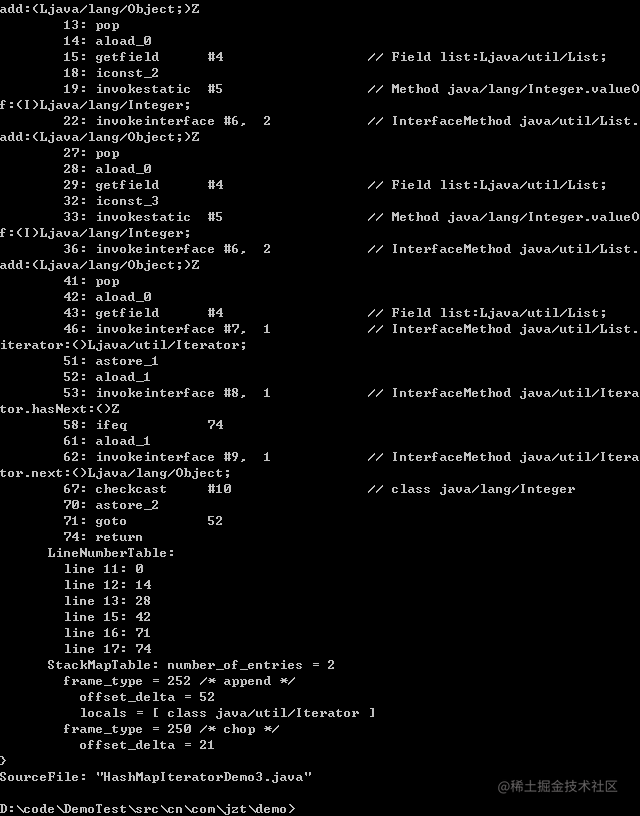
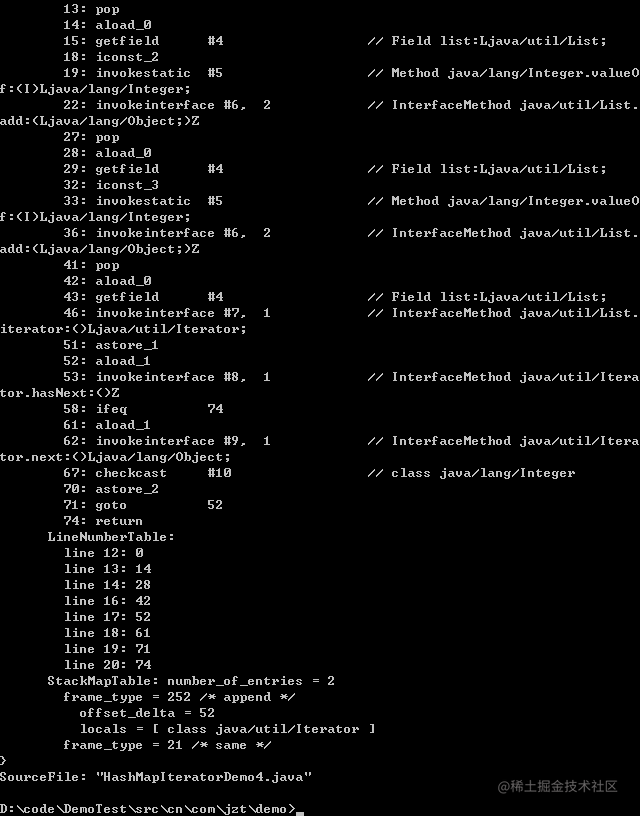
我们发现两个方法字节码指令操作几乎一模一样;
这样我们可以得出以下结论:
对集合来说,由于集合都实现了 Iterator 迭代器,foreach 语法最终被编译器转为了对 Iterator.next() 的调用;
对于数组来说,就是转化为对数组中的每一个元素的循环引用。
HashMap 遍历集合并对集合元素进行 remove、put、add
1、现象
根据以上分析,我们知道 HashMap 底层是实现了 Iterator 迭代器的 ,那么理论上我们也是可以
使用迭代器进行遍历的,这倒是不假,例如下面:
public class HashMapIteratorDemo5 {public static void main(String[] args) {Map < Integer, String > map = new HashMap < > ();map.put(1, "aa");map.put(2, "bb");map.put(3, "cc");for (Map.Entry < Integer, String > entry: map.entrySet()) {int k = entry.getKey();String v = entry.getValue();System.out.println(k + " = " + v);}}}
输出:

OK,遍历没有问题,那么操作集合元素 remove、put、add 呢?
public class HashMapIteratorDemo5 {public static void main(String[] args) {Map < Integer, String > map = new HashMap < > ();map.put(1, "aa");map.put(2, "bb");map.put(3, "cc");for (Map.Entry < Integer, String > entry: map.entrySet()) {int k = entry.getKey();if (k == 1) {map.put(1, "AA");}String v = entry.getValue();System.out.println(k + " = " + v);}}}
执行结果:

执行没有问题,put 操作也成功了。
但是!但是!但是!问题来了!!!
我们知道 HashMap 是一个线程不安全的集合类,如果使用 foreach 遍历时,进行add, remove 操作会 java.util.ConcurrentModificationException 异常。put 操作可能会抛出该异常。(为什么说可能,这个我们后面解释)
为什么会抛出这个异常呢?
我们先去看一下 Java API 文档对 HasMap 操作的解释吧。

翻译过来大致的意思就是:该方法是返回此映射中包含的键的集合视图。
集合由映射支持,如果在对集合进行迭代时修改了映射(通过迭代器自己的移除操作除外),则迭代的结果是未定义的。集合支持元素移除,通过 Iterator.remove、set.remove、removeAll、retainal 和 clear 操作从映射中移除相应的映射。简单说,就是通过 map.entrySet() 这种方式遍历集合时,不能对集合本身进行 remove、add 等操作,需要使用迭代器进行操作。
对于 put 操作,如果这个操作时替换操作如上例中将第一个元素进行修改,就没有抛出异常,但是如果是使用 put 添加元素的操作,则肯定会抛出异常了。我们把上面的例子修改一下:
public class HashMapIteratorDemo5 {public static void main(String[] args) {Map < Integer, String > map = new HashMap < > ();map.put(1, "aa");map.put(2, "bb");map.put(3, "cc");for (Map.Entry < Integer, String > entry: map.entrySet()) {int k = entry.getKey();if (k == 1) {map.put(4, "AA");}String v = entry.getValue();System.out.println(k + " = " + v);}}}
执行出现异常:

这就是验证了上面说的 put 操作可能会抛出 java.util.ConcurrentModificationException 异常。
但是有疑问了,我们上面说过 foreach 循环就是通过迭代器进行的遍历啊?为什么到这里是不可以了呢?
这里其实很简单,原因是我们的遍历操作底层确实是通过迭代器进行的,但是我们的 remove 等操作是通过直接操作 map 进行的,如上例子:map.put(4, "AA"); //这里实际还是直接对集合进行的操作,而不是通过迭代器进行操作。所以依然会存在 ConcurrentModificationException 异常问题。
2、细究底层原理
我们再去看看 HashMap 的源码,通过源代码,我们发现集合在使用 Iterator 进行遍历时都会用到这个方法:
final Node < K, V > nextNode() {Node < K, V > [] t;Node < K, V > e = next;if (modCount != expectedModCount)throw new ConcurrentModificationException();if (e == null)throw new NoSuchElementException();if ((next = (current = e).next) == null && (t = table) != null) {do {} while (index < t.length && (next = t[index++]) == null);}return e;}
这里 modCount 是表示 map 中的元素被修改了几次(在移除,新加元素时此值都会自增),而 expectedModCount 是表示期望的修改次数,在迭代器构造的时候这两个值是相等,如果在遍历过程中这两个值出现了不同步就会抛出 ConcurrentModificationException 异常。
现在我们来看看集合 remove 操作:
(1)HashMap 本身的 remove 实现:
public V remove(Object key) {Node < K, V > e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;}
(2)HashMap.KeySet 的 remove 实现
public final boolean remove(Object key) {return removeNode(hash(key), key, null, false, true) != null;}
(3)HashMap.EntrySet 的 remove 实现
public final boolean remove(Object o) {if (o instanceof Map.Entry) {Map.Entry << ? , ? > e = (Map.Entry << ? , ? > ) o;Object key = e.getKey();Object value = e.getValue();return removeNode(hash(key), key, value, true, true) != null;}return false;}
(4)HashMap.HashIterator 的 remove 方法实现
public final void remove() {Node < K, V > p = current;if (p == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();current = null;K key = p.key;removeNode(hash(key), key, null, false, false);expectedModCount = modCount; //--这里将expectedModCount 与modCount进行同步}
以上四种方式都通过调用 HashMap.removeNode 方法来实现删除key的操作。在 removeNode 方法内只要移除了 key, modCount 就会执行一次自增操作,此时 modCount 就与 expectedModCount 不一致了;
final Node < K, V > removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node < K, V > [] tab;Node < K, V > p;int n, index;if ((tab = table) != null && (n = tab.length) > 0 &&...if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode)((TreeNode < K, V > ) node).removeTreeNode(this, tab, movable);else if (node == p)tab[index] = node.next;elsep.next = node.next;++modCount; //----这里对modCount进行了自增,可能会导致后面与expectedModCount不一致--size;afterNodeRemoval(node);return node;}}return null;}
上面三种 remove 实现中,只有第三种 iterator 的 remove 方法在调用完 removeNode 方法后同步了 expectedModCount 值与 modCount 相同,所以在遍历下个元素调用 nextNode 方法时,iterator 方式不会抛异常。
到这里是不是有一种恍然大明白的感觉呢!
所以,如果需要对集合遍历时进行元素操作需要借助 Iterator 迭代器进行,如下:
public class HashMapIteratorDemo5 {public static void main(String[] args) {Map < Integer, String > map = new HashMap < > ();map.put(1, "aa");map.put(2, "bb");map.put(3, "cc");Iterator < Map.Entry < Integer, String >> it = map.entrySet().iterator();while (it.hasNext()) {Map.Entry < Integer, String > entry = it.next();int key = entry.getKey();if (key == 1) {it.remove();}}}}