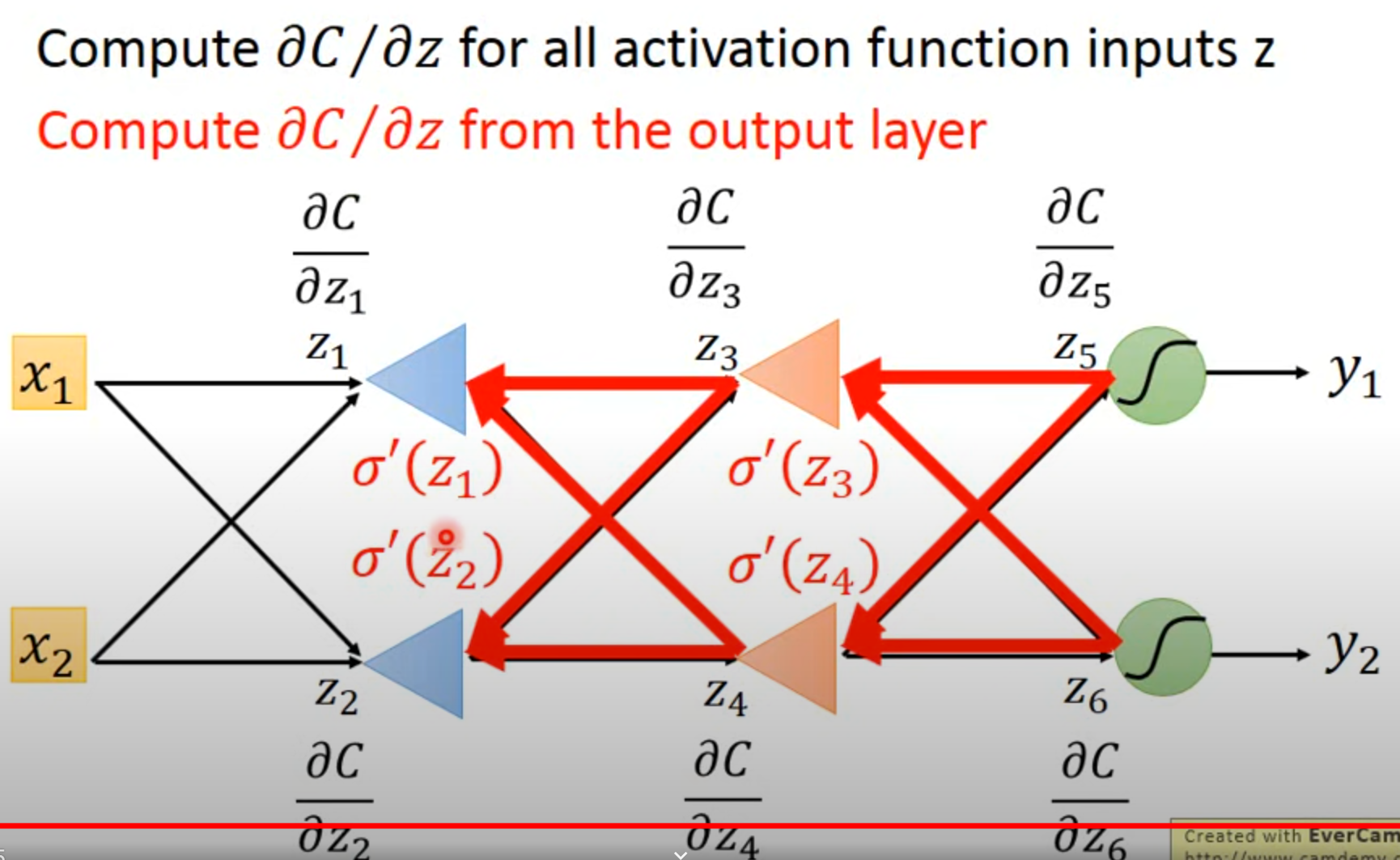
消失梯度
网络训练过程中,如果每层网络的梯度都小于 1,各层梯度的偏导数会与后面层
传递而来的梯度相乘得到本层的梯度,并向前一层传递。该过程循环进行,最后导
致梯度指数级地减小,这就产生了梯度消失现象。这种情况会导致神经网络层数较
浅的部分梯度接近 0。一般来说,产生很小梯度的原因是使用了类似于 Sigmoid 这样
的激活函数,当输入的值过大的时候这类函数曲线会趋于直线,梯度近似
为零。针对这个问题,主要的解决办法是使用更加易于优化的激活函数,比如,使用
ReLU 代替 Sigmoid 和 Tanh 作为激活函数。
爆炸梯度
网络训练过程中,如果参数的初始值过大,而且每层网络的梯度都大于 1,反向
传播过程中,各层梯度的偏导数都会比较大,会导致梯度指数级地增长直至超出浮
点数表示的范围,这就产生了梯度爆炸现象。如果发生这种情况,模型中离输入近
的部分比离输入远的部分参数更新得更快,使网络变得非常不稳定。在极端情况下,
模型的参数值变得非常大,甚至于溢出。
梯度裁剪
针对梯度爆炸的问题,常用的解决办法为梯度裁剪(Gradient Clipping)。