以下内容源于网络资源的学习与整理,如有侵权请告知删除。
参考博客
(1)H264 编码基本原理_ByteSaid的博客-CSDN博客_h264编码原理
(2)H264 编码简介_mydear_11000的博客-CSDN博客
(3)什么是I帧,P帧,B帧_Rachel-Zhang的博客-CSDN博客_i帧
(4)H264数据格式解析_qq_34613314的博客-CSDN博客_h264格式
注意“图像编码”与“图像压缩编码”同义,因为图像编码的目的是为了压缩。
一、与图像编码相关的常识
1、图像编码的必要性
(1)图像的数据量非常大,为了有效地传输和存储图像,有必要压缩图像的数据量。随着现代通信技术的发展,要求传输的图像信息的种类和数据量愈来愈大。若不进行数据压缩,便难以推广应用。
(2)举一个例子。假如显示器正在播放一个视频,分辨率是1280*720,帧率是25,那么一秒所产生正常的数据大小为:1280*720*25 / 8/ 1024 / 1024 = 2.74MB,那么90分钟的电影就要14.8GB,这个数据量显然在当前网络下是不现实的。
2、图像编码的可行性
图像数据可以进行压缩有几方面的原因。
(1)首先,原始图像数据是高度相关的,存在很大的冗余。数据冗余造成比特数浪费,消除这些冗余可以节约码字,也就是达到了数据压缩的目的。大多数图像内相邻像素之间有较大的相关性,这称为空间冗余。序列图像前后帧内相邻之间有较大的相关性,这称为时间冗余。
(2)其次,若用相同码长来表示不同出现概率的符号也会造成比特数的浪费,这种浪费称为符号编码冗余。如果采用可变长编码技术,对出现概率高的符号用短码字表示,对出现概率低的符号用长码字表示,这样就可大大消除符号编码冗余。
(3)再次,有些图像信息(如色度信息、高频信息)在通常的视感觉过程中与另外一些信息相比来说不那么重要,这些信息可以认为是心理视觉冗余,去除这些信息并不会明显地降低人眼所感受到的图像质量,因此在压缩的过程中可以去除这些人眼不敏感的信息,从而实现数据压缩。
3、图像编码的技术分类
从不同的角度出发,图像压缩编码技术有不同的分类方法。根据压缩过程有无信息损失,可分为有损编码和无损编码;根据压缩原理进行划分,可以分为预测编码、变换编码、统计编码等。
(1)有损编码
有损编码又称为不可逆编码,是指对图像进行有损压缩,致使解码重新构造的图像与原始图像存在一定的失真,即丢失了一部分信息。由于允许一定的失真,这类方法能够达到较高的压缩比。有损压缩多用于数字电视、静止图像通信等领域(2)无损编码
无损压缩又称可逆编码,是指解压后的还原图像与原始图像完全相同,没有任何信息的损失。这类方法能够获得较高的图像质量,但所能达到的压缩比不高,常用于工业检测、医学图像、存档图像等领域的图像压缩中。(3)预测编码
预测编码是利用图像信号在局部空间和时间范围内的高度相关性,以已经传出的近邻像素值作为参考,预测当前像素值,然后量化、编码预测误差。预测编码广泛应用于运动图像、视频编码如数字电视、视频电话中。(4)变换编码
变换编码是将空域中描述的图像数据经过某种正交变换(如离散傅里叶变换DFT、离散余弦变换DCT、离散小波变换DWT等)转换到另一个变换域(频率域)中进行描述,变换后的结果是一批变换系数,然后对这些变换系数进行编码处理,从而达到压缩图像数据的目的。(5)统计编码
统计编码也称为熵编码,它是一类根据信息熵原理进行的信息保持型变字长编码。编码时对出现概率高的事件(被编码的符号)用短码表示,对出现概率低的事件用长码表示。在目前图像编码国际标准中,常见的熵编码方法有哈夫曼(Huffman)编码和算术编码。
4、图像编码的评价指标
压缩比和失真比是衡量图像压缩的重要指标。压缩比是指压缩过程中输入数据量和输出数据量之比。失真比主要是针对有损编码而言的,是指图像经有损压缩,然后将其解码后的图像与原图像之间的误差,有损压缩会使原始图像数据不能完全恢复,信息受到一定的损失,但压缩比较高,复原后的图像存在一定的失真。
二、H264的编码原理
1、H264的简介
H.264同时也是 MPEG-4 第十部分,是由 ITU-T 视频编码专家组(VCEG)和 ISO/IEC 动态图像专家组(MPEG)联合组成的联合视频组(JVT,Joint Video Team)提出的高度压缩数字视频编解码器标准。这个标准通常被称之为 H.264/AVC(或者 AVC/H.264 或者 H.264/MPEG-4 AVC 或 MPEG-4/H.264 AVC)。H.264是一种面向块,基于运动补偿的视频编码标准。
2、H264编码理论依据
根据一段时间内图像的统计结果,在相邻的几幅图像画面中,有差别的像素少于10%,亮度的差值不超过2%,色度的差值不超过1%。因此对于一段变化不大的图像画面,我们可以先编码出一个完整的图像帧A,随后的B帧不需要全部编码,而只是写入与A帧的差别,这样B帧的大小就只有完整帧的1/10或更小!B帧之后的C帧如果变化不大,我们在C帧中写入与B帧的差别……如此循环。
这一段类似的图像画面的数据就组成了一个序列。当某个图像与之前的图像变化很大,无法参考前面的帧来生成时,我们就结束上一个序列,开始下一段序列。
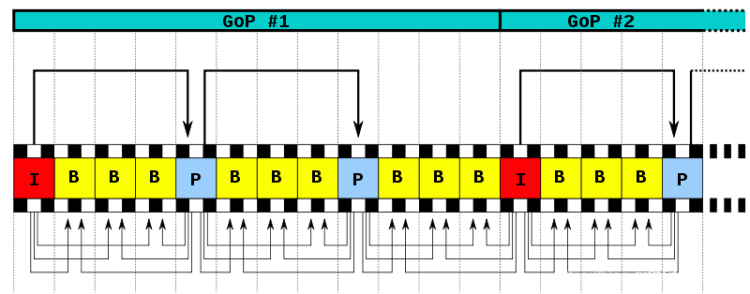
在H264协议里定义了三种帧,完整编码的帧叫I帧,参考之前的I帧生成的、只对差异部分进行编码的帧叫P帧,还有一种参考前后帧进行编码的帧叫B帧。
3、概念:I帧、P帧、B帧
H264结构中,一幅视频图像编码后的数据叫做一帧,一帧由一个片(slice)或多个片组成,一个片又由一个或多个宏块(MB)组成,一个宏块由16x16的 yuv 数据组成。宏块是 H264 编码的基本单位。这里介绍帧的概念。
(1)I帧简介
I帧,又被称为内部画面(intra picture),可以理解为一帧完整的画面,因此解码时不需要参考其他帧的数据,只需要本帧数据就可以完成。
I帧的特点:
a、它是一个全帧压缩编码帧,即它将全帧图像信息进行JPEG压缩编码及传输。
b、解码时仅用I帧的数据就可重构完整图像。
c、I帧描述了图像背景和运动主体的详情。
d、I帧不需要参考其他画面而生成。
e、I帧是P帧和B帧的参考帧(其质量直接影响到同组中以后各帧的质量)。
f、I帧是帧组GOP的基础帧(第一帧),在一组中只有一个I帧。
g、I帧不需要考虑运动矢量。
h、I帧所占数据的信息量比较大。
(2)P帧简介
P帧,又称为“前向预测编码帧”。P帧表示的是这一帧跟之前的一个I帧(或P帧)的差别,P帧没有完整的画面数据,解码时需要用前一帧的画面叠加上本帧定义的差别,生成最终画面。
P帧的预测与重构:在发送端,P帧以I帧为参考帧,在I帧中找出P帧“某点”的预测值和运动矢量,取预测差值和运动矢量一起传送。在接收端,根据运动矢量从I帧中找出P帧“某点”的预测值并与差值相加以得到P帧“某点”样值,从而可得到完整的P帧。
P帧的特点:a、P帧是I帧后面相隔1~2帧的编码帧。
b、P帧采用运动补偿的方法传送它与前面的I或P帧的差值及运动矢量(预测误差)。
c、解码时必须将I帧中的预测值与预测误差求和后才能重构完整的P帧图像。
d、P帧属于前向预测的帧间编码,它只参考前面最靠近它的I帧或P帧。
e、P帧可以作为其后面P帧的参考帧,也可以作为其前后的B帧的参考帧。
f、由于P帧是参考帧,它可能造成解码错误的扩散。
g、由于是差值传送,P帧的压缩比较高。
(3)B帧简介
B帧,又称为“双向预测内插编码帧”。B帧是双向差别帧,也就是B帧记录的是本帧与前后帧的差别。要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累。
B帧的预测与重构:在发送端,B帧以前面的I或P帧和后面的P帧为参考帧,找出B帧“某点”的预测值和两个运动矢量,并取预测差值和运动矢量传送。在接收端,根据运动矢量在两个参考帧中找出预测值并与差值求和,得到B帧“某点”的样值,从而可得到完整的B帧。
B帧特点:
a、B帧是由前面的I或P帧和后面的P帧来进行预测的。b、B帧传送的是它与前面的I或P帧和后面的P帧之间的预测误差及运动矢量。
c、B帧是双向预测编码帧。
d、B帧压缩比最高,因为它只反映与参考帧间运动主体的变化情况,预测比较准确。
e、B帧不是参考帧,不会造成解码错误的扩散。
值得注意的是,I帧、B帧和P帧这些概念,是根据压缩算法的需要,人为定义出来的。它们本质上都是实实在在的物理帧。一般来说,I帧的压缩率是7(跟JPG差不多),P帧是20,B帧可以达到50。可见使用B帧能节省大量的空间,节省出来的空间可以用来保存多一些I帧,这样在相同的码率下,可以提供更好的画质。
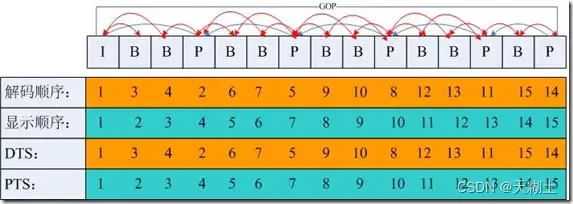
如下图所示,因为有 B 帧这样的双向预测帧的存在,某一帧的解码序列和实际的显示序列是不一样的。其中DTS(Decode Time Stamp)表示用于视频的解码序列;PTS:(Presentation Time Stamp)表示用于视频的显示序列。
4、概念:序列(GOP?)
(1)在H264中,图像以序列为单位进行组织。一个序列是一段内容差异不太大的图像编码后生成的一串数据流,以I帧开始,到下一个I帧结束。
(2)当运动变化比较少时,一个序列可以很长,因为图像画面的内容变动很小,因此可以编一个I帧,然后一直P帧、B帧。当运动变化多时,一个序列就会比较短,比如就包含一个I帧和3、4个P帧。
(3)某个序列的第一幅图像叫做 IDR图像(立即刷新图像),IDR 图像都是 I 帧图像。 H264引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。
(4)IDR 图像一定是 I 帧,但 I 帧不一定是 IDR 图像。一个序列中可以有很多的I图像,I 图像之后的图像可以引用 I 图像之间的图像做运动参考。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
(5)还有一点注意的,对于 IDR 帧来说,在 IDR 帧之后的所有帧都不能引用任何 IDR 帧之前的帧的内容,与此相反,对于普通的 I 帧来说,位于其之后的 B帧 和 P 帧可以引用位于普通 I 帧之前的 I 帧。从随机存取的视频流中,播放器永远可以从一个 IDR 帧播放,因为在它之后没有任何帧引用之前的帧。但是,不能在一个没有 IDR 帧的视频中从任意点开始播放,因为后面的帧总是会引用前面的帧。
5、H264的功能结构
如下图所示,在 H.264/AVC 视频编码标准中,整个系统框架划分为如下两个层面:
(1)视频编码层(VCL,Video Coding Layer):VCL 数据即被压缩编码后的视频数据序列,负责有效表示视频数据的内容,主要包括帧内预测,帧间预测、变换量化、熵编码等压缩单元。
(2)网络抽象层(NAL,Network Abstraction Layer):负责将 VCL 数据封装到 NAL 单元中,并提供头信息,以保证数据适合各种信道和存储介质上的传输。
因此每帧数据就是一个NAL单元。NAL单元的格式如下(图示有两个NAL单元),每个NAL单元都是由1字节的NAL header和若干字节的原始字节序列负荷(RBSP, Raw Byte Sequence Payload) 构成。
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ ... | NAL Header | RBSP | NAL Header | RBSP | ... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+

6、H264 编码原理
H264采用的核心算法是帧内压缩和帧间压缩,帧内压缩是生成I帧的算法,帧间压缩是生成B帧和P帧的算法。
帧内(Intraframe)压缩:也称为空间压缩(Spatialcompression)。当压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。帧内一般采用有损压缩算法,由于帧内压缩是编码一个完整的图像,所以可以独立的解码、显示。帧内压缩一般达不到很高的压缩,跟编码 JPEG 差不多。
帧间(Interframe)压缩:也称为时间压缩(Temporalcompression),它通过比较时间轴上不同帧之间的数据进行压缩。帧间压缩一般是无损的。帧差值(Framedifferencing)算法是一种典型的时间压缩法,相邻几帧的数据有很大的相关性,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
见博客:H264 编码基本原理_ByteSaid的博客-CSDN博客_h264编码原理,很形象与生动。