文章目录
- Geo查找附近商铺
- BitMap实现用户签到
- UV统计
Geo查找附近商铺
Geo是GeoLocation的简称,代表地理坐标,在Redis 3.2中加入了对Geo的支持,允许存储地理坐标信息,常见的命令有:
①GEOADD key x y member [x2 y2 member]:向key中添加多个地理坐标,其中x,y是它的经纬度,member是key中的一个点
②GEODIST key member1 member2 : 获取key中的两个member之间的距离
③GEOHASH key member: 将key的member的坐标以hash字符串的形式返回
④GEOPOS key member: 获取key中的member的坐标
⑤GEOSEARCH key [FROMMEMBER member] [FROMLONLAT longitude latitude] [BYRADIUS radius m|km|ft|mi] [BYBOX width height m|km|ft|mi] [ASC|DESC] [COUNT count [ANY]] [WITHCOORD] [WITHDIST] [WITHHASH]:查找key中距离某一个位置在radis或者width范围内的member,其中查找区域可以是一个圆形或则矩形如果是圆形,那么是通过BYRADIUS radius m|km|ft|mi来说明,其中的m|km等说明的是查找范围的半径的单位,同理如果是BYBOX width height m|km|ft|mi则说明查找范围是一个矩形。WITHDIST则返回的数据中不仅仅返回的是key中在这个范围的member,同时返回这个member到参考点的距离。其中参考点可以选择key中的member,命令是FROMMEMBER member,如果希望自定义的参考点,那么就是FROMLONLAT x y。
值得注意的是,返回的点是默认根据distance升序返回的,也即根据ASC|DESC来指明返回结果是按照distance升序还是降序返回。
⑥GEOSEARCHSTORE: 作用和GEOSEARCH的是一样的,但是它可以将结果保存到指定的key中。
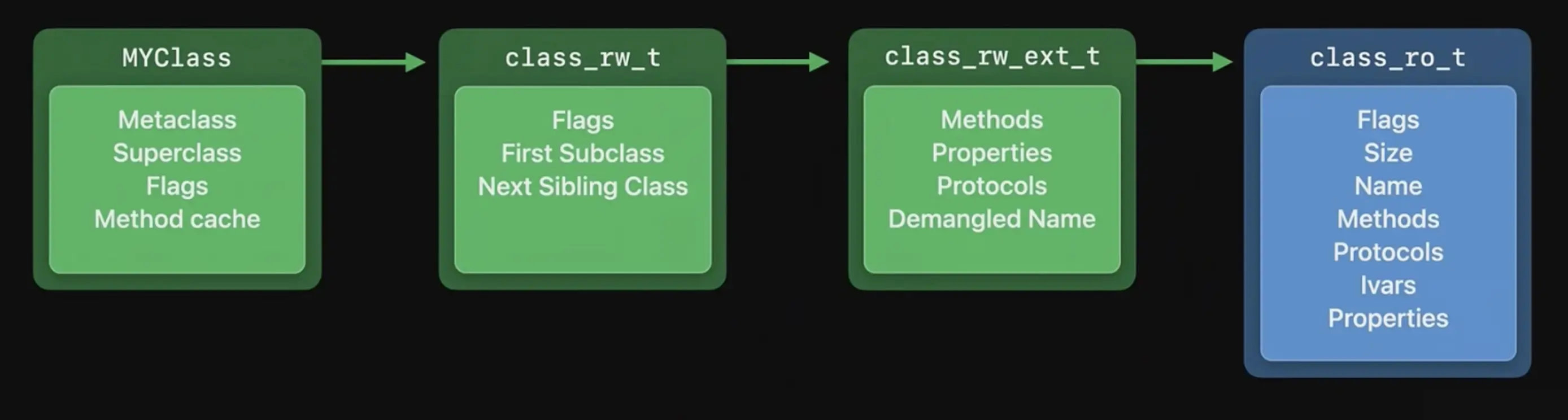
对应的命令运行结果如下所示:
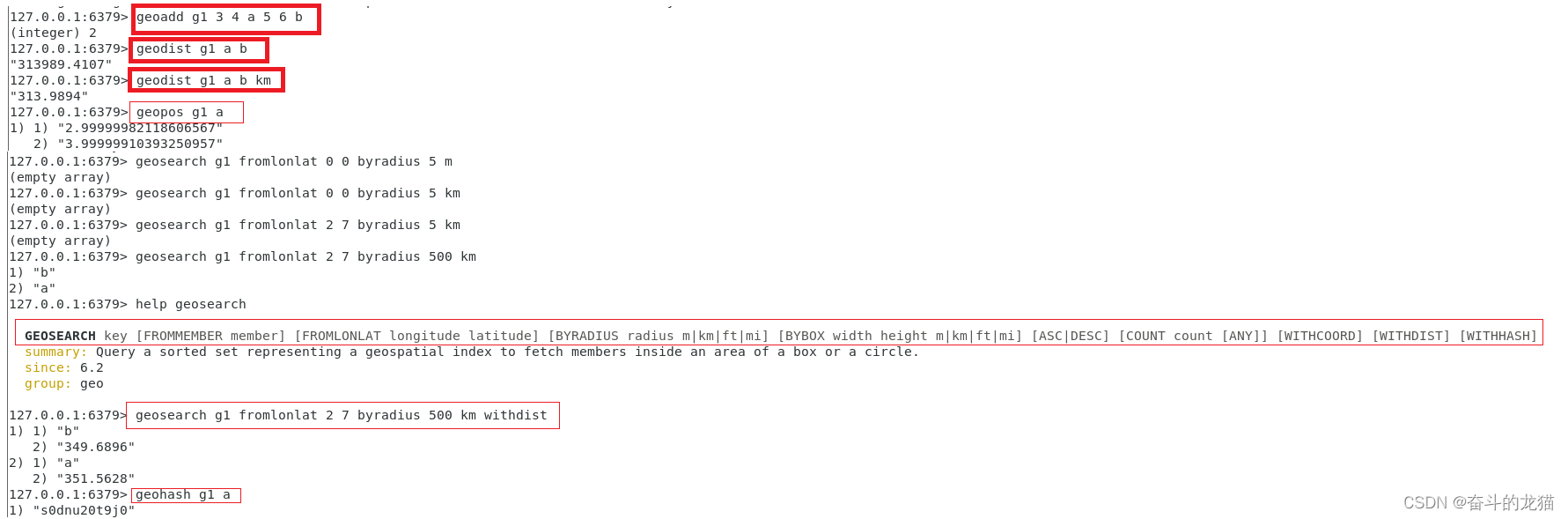
所以我们可以利用命令GEOADD,来将店铺信息以及对应的地理信息添加到redis中,但是考虑到店铺的信息很多,此时如果店铺信息全部存入到redis中的时候就会导致内存占用的问题,因此只需要将店铺的id存入到redis中。
此外,如果希望查询某一个类别的店铺的时候,我们希望能够很快找到属于这一个类别的店铺,所以就需要根据redis中的key的层次结构来实现,因此对应的key就是geo:shop:typeId,key的值就是属于这个typeId的shopId.
因此如果希望查找某一个typeId的店铺的时候,就先从redis中获取所有的shopId,然后再根据得到的shopId来查找数据库从而得到Shop,最后返回给前端即可。
所以在利用Geo来查找附近的商铺的时候,我们需要先将shopId加入到redis中,对应的代码为:
/**
* 将所有商铺的地理位置信息添加到redis中,其中因为
* 商铺的信息很多,所以最后保存到redis中的是这个商铺的id以及地理位置,
* 当我们查询某一个类别的商铺的时候,就会从redis中获取对应的商铺id,然后
* 再查询数据库。
*/
@Test
public void loadShopService(){
//1、获取所有的商铺
List<Shop> shops = shopService.list();
//2、根据商铺的类别id,从而进行分组
Map<Long, List<Shop>> shopMaps = shops.stream().collect(Collectors.groupingBy(Shop::getTypeId));
//3、遍历不同分组的店铺,然后写入到redis中
for(Map.Entry<Long, List<Shop>> entry : shopMaps.entrySet()){
//3.1 获取店铺类别id
Long typeId = entry.getKey();
String key = RedisConstants.SHOP_GEO_KEY + typeId;
//3.2 获取属于这个类别的所有店铺id
List<Shop> value = entry.getValue();
//3.3 将所有的店铺写入到redis中,通过命令GEOADD key x y member,其中
//x,y就是店铺的位置,而member就是这个店铺的id
/*
这种方式需要遍历不同类别的店铺,并且是一条一条添加的,效率可能会有些低,
所以采用的是批量插入到redis的方式
value.forEach(shop -> {
stringRedisTemplate.opsForGeo().add(key, new Point(shop.getX(), shop.getY()), shop.getId().toString());
});*/
List<RedisGeoCommands.GeoLocation<String>> iteration = new ArrayList<>(value.size());
value.forEach(shop -> {
iteration.add(new RedisGeoCommands.GeoLocation<>(shop.getId().toString(), new Point(shop.getX(), shop.getY())));
});
stringRedisTemplate.opsForGeo().add(key, iteration);
}
}
将shopId保存到redis中之后,我们就可以去实现查找附近的店铺了,对应的api接口为ShopController中的queryByType,对应的url为shop/of/type,他会传递4个参数,分别是typeId, current(表示查询的是第current页的数据),x , y(表示x,y这个点作为参考点),其中x,y这2个参数并不是必须的,所以如果没有传递x,y这2个参数的时候,默认是查找第current页的所有店铺,否则就是查找x,y某个范围内的第current页的所有店铺。
所以对应的代码为:
@Override
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {
if(x == null || y == null){
//1、x,y至少有1个为null,那么就是查询所有类型为typeId的第current的店铺
Page<Shop> page = query()
.eq("typeId", typeId)
.page(new Page<Shop>(current, SystemConstants.DEFAULT_PAGE_SIZE));
//1.1 获取第current页的所有记录
List<Shop> records = page.getRecords();
return Result.ok(records);
}
int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;
int end = current * SystemConstants.DEFAULT_PAGE_SIZE;
//2、查询x,y附近的所有店铺GEOSEARCH key FROMLONLAT x y BYRADIUS radius withdist,并且默认根据distance升序返回的
String key = RedisConstants.SHOP_GEO_KEY + typeId;
GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo().search(key,
//以x,y这个点为圆心,半径为5千米的店铺
GeoReference.fromCoordinate(x, y),
new Distance(5000),
//includeDistance表示返回的数据除了携带member信息之外,还包括距离圆心的距离
//limit用来实现分页的,表示获取在这个范围内的点最多有end条(所以不仅仅包括了第current页的,也包括了之前的页的记录,因此下面需要调用skip方法,来获取第current页的记录
RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end)
);
if(results == null){
//2.1 如果距离圆心距离为5km的店铺一个都没有
return Result.ok(Collections.emptyList());
}
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> contents = results.getContent();
if(contents.size() <= from){
//2.2 如果查询到的距离圆心的距离的店铺比current - 1页还要少,那么第current页的记录就是空的
return Result.ok(Collections.emptyList());
}
//2.3 获取第current页的店铺以及每个店铺距离当前圆心的距离
List<Long> shopIds = new ArrayList<>();
Map<Long, Distance> map = new HashMap<>();
contents.stream().skip(from).forEach(result ->{
//对于每个GeoLocation来说,存在2个属性name以及Point,point表示的是位置
Long shopId = Long.parseLong(result.getContent().getName());
shopIds.add(shopId);
map.put(shopId, result.getDistance());
});
//3、获取shopIds中的所有Shop对象,然后将其返回,但是如果没有last方法中的order by子句
//很容易导致最后shops的结果和上面的shopIds顺序不一样,因为在mysql中根据in子句
//查询,因此为了保证两者的顺序一样,才添加了last方法中的order by子句
String idStr = StrUtil.join(",", shopIds);
List<Shop> shops = query().in("id", shopIds)
.last("ORDER BY FIELD (id," + idStr + ")").list();
//3.1 获取每个shop到当前x,y点的距离
shops.forEach(shop -> {
shop.setDistance(map.get(shop.getId()).getValue());
});
return Result.ok(shops);
}
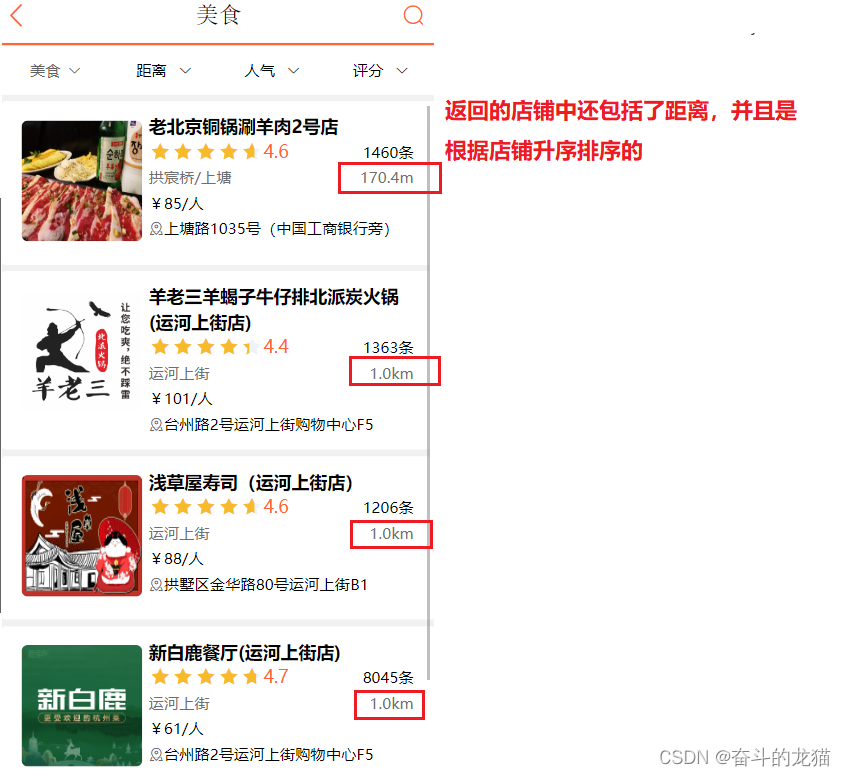
所以实现上面的API接口之后,那么最后的运行结果如下所示:
BitMap实现用户签到
在Redis中,通常利用BitMap这种数据结构来实现用户的签到,因为BitMap是一个二值统计状态的,所以通常用于判断用户是否登录,签到场景,常见的命令有:
①SETBIT key offset value : 设置key中的下标为offset的值为value
②GETBIT key offset: 获取key中的下标为offset的值
③BITFIELD key GET type offset: 这个命令表示获取key中从offset开始的,count为比特数字形成的数字,type说明形成数字对应的形式以及count,例如u2表示返回的是从offset开始的,共2个比特数字形成的无符号十进制数字,i2则表示的是从offset开始的,共2个比特数字形成的有符号十进制数字。但是BITFIELD并不仅仅可以执行获取操作,也可以执行修改、自增操作,只是通常用于获取操作。
④BITPOS key value: 获取第一次出现1或者0的下标
⑤BITCOUNT key: 统计key中一共有多少个1
所以我们要希望实现用户签到功能,那么就可以通过命令SETBIT,在Java客户端中,并没有opsForBit方法,那么应该执行操作呢?其实BitMap是基于String进行操作的,所以是通过opsForValue(),然后调用对应的方法执行的。
同时,要想实现用户签到,那么key的格式应该是userId:年月,因为这样可以清楚知道不同的用户在某一个时间的签到情况,而要设置第day天签到,那么就需要设置key中的下标为day - 1的值即可。所以对应的代码为:
/**
* 实现用户签到功能,那么这时候需要利用到了bitmap数据结构
* 通过命令setBit key offset value,来设置下标为offset的置为value
* value只能为1、0.
* 所以要统计某一个用户在哪一个时间签到,那么对应的key就是一个时间
* 所以key = userId:currentDate
* @return
*/
@Override
public Result sign() {
//1、获取当前的登录用户
Long userId = UserHolder.getUser().getId();
//2、获取当前的时间
LocalDateTime dateTime = LocalDateTime.now();
String dateString = dateTime.format(DateTimeFormatter.ofPattern(":yyyyMM"));
//3、设置key
String key = RedisConstants.USER_SIGN_KEY + userId + dateString;
//4、获取offset,来设置key中的哪一个bit位的值,这时候getDayOfMonth是从1开始的,所以还需要减1
int day = dateTime.getDayOfMonth();
//5、通过opsForValue调用setBit来实现签到功能
stringRedisTemplate.opsForValue().setBit(key, day - 1, true);
return Result.ok();
}
要想统计用于当前用户至今为止的连续签到次数,那么这时候仅仅通过GETBIT命令无法满足我们的要求,因为这个只能获取下标为offset的值,而我们需要获取范围的值,因此就需要利用BITFIELD命令了。要想获取至今为止的连续签到次数,也就是从当月的第1天到至今为止的连续签到次数,所以offset就是0,表示从当月的第1天开始,而要查day天的比特数据,因为至今为止一共有day天,所以就有day个比特数字。
但是需要获取的是连续签到天数,所以我们在获取从第1天到至今为止的十进制数字之后,就需要不断和1进行与运算,从而获取至今为止的签到天数,一旦比特数字为0,说明签到,此时就可以退出循环了,否则就不断右移。如下所示:

所以对应的代码为:
/**
* 获取当前用户到当前这一天为止的连续签到次数
* 这时候需要利用到了命令bitfield,它是可以获取从offset开始的,
* 长度为len的比特数字对应的十进制数字。
* 所以这时候我们因为需要统计的是从第一天开始,到今天为止
* 的连续签到次数,那么获取从0开始,长度为day的比特数字对应的十进制数字
* 然后再和1进行与运算,从而可以得知当前这一天为止的连续签到次数
* @return
*/
@Override
public Result signCount() {
//1、获取当前的登录用户
Long userId = UserHolder.getUser().getId();
//2、 获取当前的日期
LocalDateTime dateTime = LocalDateTime.now();
String dateFormat = dateTime.format(DateTimeFormatter.ofPattern(":yyyyMM"));
//3、 获取签到对应的key
String key = RedisConstants.USER_SIGN_KEY + userId + dateFormat;
//4、 获取当前这一天是这个月份的第几天,对应的day就是我们需要统计多少个比特为的个数
int day = dateTime.getDayOfMonth();
//5、获取从0开始的,长度为day的二进制数字对应的无符号十进制数字
//bitfield key get u[day] offset
//之所以返回的是一个集合,因为BITFIELD也可同时进行其他的操作,例如SET,INCR
List<Long> result = stringRedisTemplate.opsForValue().bitField(key,
BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(day)).valueAt(0)
);
if(result == null || result.isEmpty()){
return Result.ok(0);
}
//6、获取对应的无符号十进制数字
Long num = result.get(0);
if(num == 0L || num == null){
return Result.ok(0);
}
int count = 0;
System.out.println(Long.toBinaryString(num));
//6.1 统计到今天为止的连续签到次数
while(true){
if((num & 1) == 0){
//如果当前的比特位为0,说明没有签到,直接退出
break;
}else{
++count;
}
num >>>= 1;
}
return Result.ok(count);
}
UV统计
UV: 全称为Unique Visitor,也叫独立访客量,是指通过互联网、浏览这个网页的自然人。1天内同一个用户多次访问这个网站的时候,只记录1次。
PV:全称为Page Visitor,也叫页面访问量或点击量,用户每次访问网站的一个页面,都会记录1次PV。当用户多次打开页面,就记录多次PV,所以PV往往用来衡量网站的流量。
所以如果需要通过服务器来实现UV的时候,就需要判断之前这个用户是否已经统计过了,所以在用户访问量非常巨大的时候,那么导致占用内存巨大。
所以就有了HyperLogLog这种数据结构,它是从Loglog算法派生的概率算法,用于确定非常大的基数,而不需要存储所有值。
Redis中的HyperLogLog是基于String操作的,单个HLL占用的内存永远小于16kb,但是测量结果是具有概率性的,拥有小于0.81%的误差,但是在UV统计中,这个误差是完全可以忽略的。常见的命令有:
①PFADD key elemet1 [element2 element3…]:向key中添加多个element,如果这个element已经存在key中了,那么不会执行添加操作
②PFCOUNT key: 获取key中的元素个数
③PFMERGE destKey sourceKey1 [sourceKey2 sourceKey3…]:将多个sourceKey合并到destKey中
所以这里通过HyperLogLog实现UV统计的代码如下所示:
/**
* 测试HyperLogLog:
* HyperLogLog数据结构是基于String操作的,占用的内存很小,不超过16KB,但是
* 他是一个具有概率性的结果,也即是说插入1000000条数据,但是最后的key中
* 存在的元素个数可能没有1000000条,但是它的概率不超过0.81%,这对于UV统计
* 来说,完全可以忽略的。常见的命令有:
* 1、PFADD key element1 element2 -> 对应java客户端的方法是opsForHyperLogLog().add(key, element...)
* 2、PFCOUNT key: 统计key中的元素个数, -> opsForHyperLogLog().size()
* 3、PMERGE destKey sourceKey1 sourceKey2 : 将多个sourceKey合并到destKey中
* 其中PFADD 命令条件元素到key的时候,如果新添加的元素已经存在了,那么不会进行添加操作
*/
@Test
public void testHyperLogLog(){
//未添加的时候,redis中的内存为1476440,添加之后是1490800
//所以添加的数据大小为14kb,小于16kb
String[] users = new String[1000];
int j = 0;
String key = "hll2";
for(int i = 0; i < 1000000; ++i){
j = i % 1000;
users[j] = "user_" + i;
if(j == 999){
//每一千条,就将数组插入到redis中
stringRedisTemplate.opsForHyperLogLog().add(key,users);
}
}
//打印key中有多少个元素,因为HyperLogLog是一个具有概率性的结果,所以最后
//的结果可能不一定有1000000条,但是概率小于0.81%
Long count = stringRedisTemplate.opsForHyperLogLog().size(key);
System.out.println(count);
}