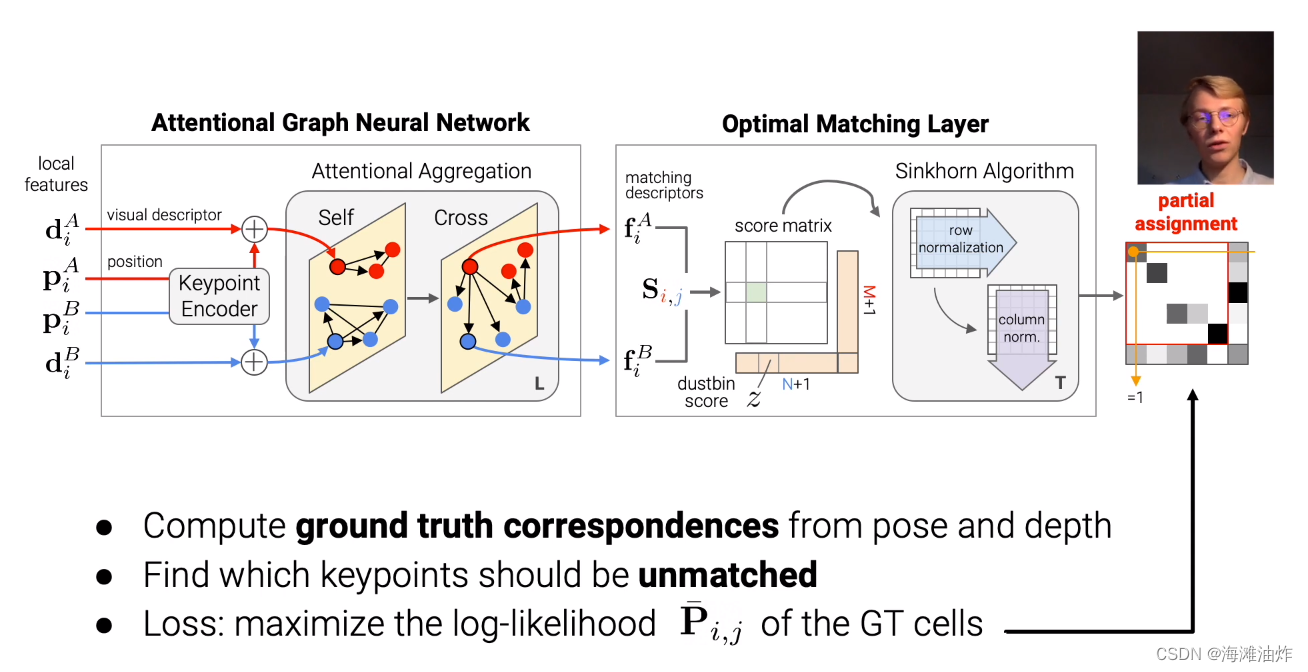
【paper】 SimplE Embedding for Link Prediction in Knowledge Graphs
【简介】 本文是加拿大英属哥伦比亚大学的两位学者发表在 NIPS 2018 上的工作,文章提出了 SimplE(Simple Embedding)。这篇和前面一篇差不多,也是对 1927 年的 CP 进行改进(简化),传统CP为实体分配的两个向量是独立训练的,SimplE利用关系的逆在三元组打分函数中加上了一个对称项,使得每个实体的两个向量依赖学习,并且 SimplE 的复杂度随 embedding 维度呈线性。
SimplE 可以被视为双线性模型,并且是 fully expressive,可以通过参数共享(赋权)编码背景知识;尽管(或者是因为)其简单,在实验中表现效果好。
模型
1927 年的 CP(Canonical Polyadic)在链接预测上表现效果通常很差,因为它为每个实体分配两个向量(作为头尾实体时的不同表示),但是两个向量是分别学习的,如:
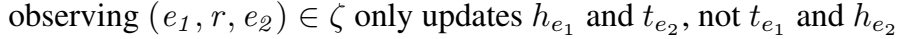
对此,SimplE 仍然保留每个实体分配两个向量的设置,但也为每个关系分配两个向量:

对于每个 triple,simplE 定义的相似度函数为:

同时,还考虑了另一种情况,称为 SimplE-ignr:在训练时候更新参数时两部分都考虑,而在测试时不再考虑反向关系部分,只保留前半部分:
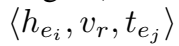
在训练时使用 L2 正则化:

其中,
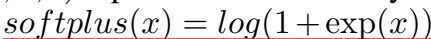
之所以没有选择 margin-based 的 loss 是因为它比 log-likelihood 更容易导致过拟合。
理论分析
没看。
不过对双线性模型家族的各模型的关系矩阵进行了一个直观的展示和对比:

实验
链接预测

整合背景知识

就是 8 种对称关系定义的规则,也不知道它是咋整合的==|
【code】 GitHub - Mehran-k/SimplE: SimplE Embedding for Link Prediction in Knowledge Graphs
双线性模型(五)(CP、ANALOGY、SimplE) - 胡萝不青菜 - 博客园