进程间通信的必要性
进程间通信,是建立在多进程之上的。如果是单进程,则无法使用并发能力,更加无法进行多进程协同。多进程要想实现多进程协同(目的),就必须进行进程间通信(手段)。
具体的进程间通信的目的(实例):比如:1. 数据传输:一个进程需要将它的数据发送给另一个进程。2. 资源共享:多个进程之间共享同样的资源。 3. 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。4. 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
多进程通过进程间通信,比如具体的上方几个目的,实现多进程协同。(鉴于现在代码经验和知识的匮乏,可能无法切实理解到什么情况下需要多进程协同,但是这样的需求和场景肯定是存在的,需要后面不断的学习)
进程间通信的技术背景
进程是具有独立性的,这是在学习进程时,进程的一大特点。
进程 = 进程的内核数据结构 + 进程对应的代码和数据。不管是两个独立的进程,还是父进程fork创建子进程,进程的内核数据结构还有代码和数据都是有独立性的。因为虚拟地址空间+页表的存在,进程的虚拟地址通过页表映射到物理内存的不同区域,即使是父进程fork创建子进程,子进程的内核数据结构也会有独立的一份,而代码和数据在创建之初和父进程共享,但是因为写时拷贝技术的存在,子进程的代码和数据仍然是具有独立性的(比如,非常量全局数据,在父子进程之一写时,会拷贝一份。而代码,比如调用execl函数进行进程切换时,也会发生代码的写时拷贝)
因此,基于进程独立性,进程间如果想进行通信,成本是比较高的。
进程间通信的本质理解:
因为进程是具有独立性的,所以,
要想实现进程间通信,首先要让不同进程看到同一份资源(同一块"内存",这个内存是特定的结构组织的),这个内存资源,不能隶属于任何一个进程,而更应该强调共享(其实就是属于操作系统管理的)
管道IPC:匿名管道
示意图
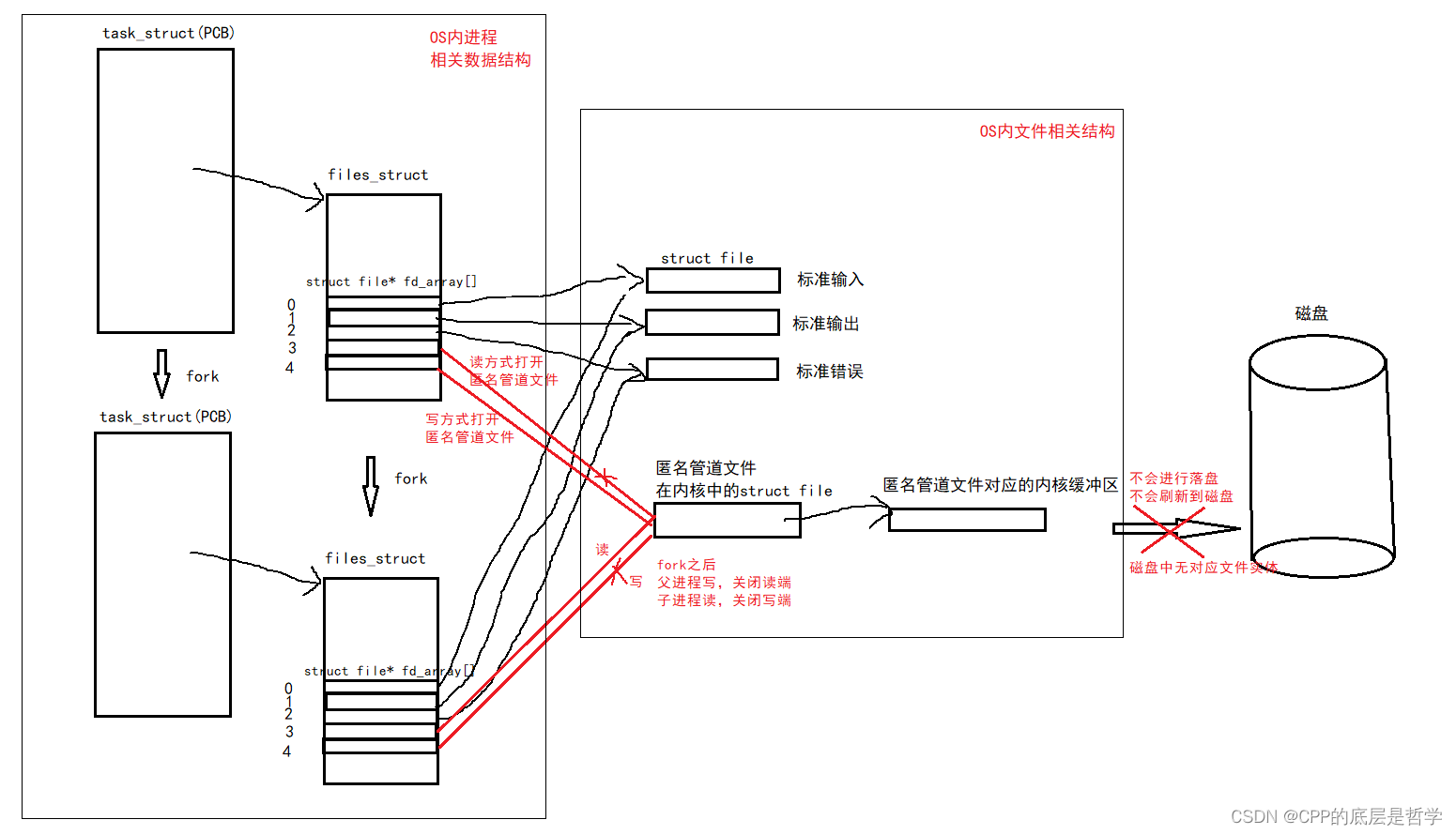
匿名管道的本质原理:
在父进程fork创建子进程时,子进程会有自己独立的内核数据结构(如页表,虚拟地址空间,PCB,文件描述符表等),而这其中的文件描述符表中每一个元素存储的是该进程打开的所有文件对应的内核struct file结构体的地址。
当父进程fork创建子进程,子进程的内核数据结构都是从父进程那里直接拷贝过来的(包括虚拟地址空间,页表等),当然,部分字段还是需要修改的(如pid等),而其中的文件描述符表是与父进程完全一致的(包括内容)。
因此,当父进程以读和写方式打开某一个文件之后,进行fork,子进程继承了父进程的文件描述符表,子进程也以读和写方式打开了这个文件。因为管道是单向通信的,故父子进程关闭自己不需要的一端之后,就可以通过该匿名管道文件进行通信。
demo示例代码:
#include <unistd.h>
#include <iostream>
#include <string>
#include <cstring>
#include <cassert>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
int main()
{
// 创建管道
int pipefd[2] = {0}; // pipefd[0] 读端fd, pipefd[1] 写端fd
int ret = pipe(pipefd); // On success, zero is returned. On error, -1 is returned, and errno is set appropriately.
assert(ret != -1);
(void)ret;
#ifdef DEBUG
cout << "pipefd[0](管道读端) : " << pipefd[0] << endl;
cout << "pipefd[1](管道写端) : " << pipefd[1] << endl;
#endif
// 创建子进程
pid_t id = fork();
assert(id != -1);
if (id == 0)
{
// 子进程,用于读取,不写入
close(pipefd[1]);
// 子进程读数据时的缓冲区
char buff[1024];
int count = 0;
while (true)
{
ssize_t sz = read(pipefd[0], buff, sizeof(buff) - 1);
if(sz > 0)
{
buff[sz] = '\0';
cout << "child pid :" << getpid() << " " << buff << "haha" << endl;
// cout << "test" <<endl;
}
else if(sz == 0)
{
cout << "Pipe close, child quit!!!\n";
break;
}
// 测试管道的读端关闭,写继续写。则OS终止写进程。
// if(count++ == 5)
// {
// cout << "read close" << endl;
// close(pipefd[0]);
// break;
// }
}
exit(0);
}
// 父进程,用于写入,不读取
close(pipefd[0]);
string s = "I am father process";
int count = 0;
char buff[100];
while (true)
{
// 现在制造一个,父进程持续向管道内写入的程序
snprintf(buff, sizeof(buff), "%s : %d", s.c_str(), count++);
write(pipefd[1], buff, strlen(buff));
sleep(1);
// 写端关闭,读端read返回值为0,标志读到文件结尾。
if (7 == count)
{
close(pipefd[1]); // 父进程关闭管道的写端
cout << "Pipe close!!!\n";
break;
}
}
// 父进程回收子进程
int status = 0;
pid_t result = waitpid(id, &status, 0); // 阻塞式等待,等待成功返回0,调用失败返回-1
if (WIFEXITED(status))
{
cout << "Child process " << result << " quit code : " << WEXITSTATUS(status) << endl;
}
else
{
cout << "Child process quit abnormally" << endl;
}
assert(result > 0);
return 0;
}pipe 系统调用
创建匿名管道时,是有专门的系统调用的,因为管道文件和普通文件在性质上是有差别的。
int pipe(int pipefd[2]);
该系统调用用于创建一个纯内存级的匿名管道文件,参数为输出型参数,pipefd[0]保存读端文件描述符,pipefd[1]保存写端文件描述符(整型,文件描述符表的下标)。
注意:
1. 管道是一种单向通信的进程间通信方式,父子进程需要关闭自己不需要的一端的文件描述符(其实不关闭也不影响,但是从严谨和避免资源浪费的角度考虑,最好关闭)。
2. 这里的内核中匿名管道文件是一种纯内存级文件,在磁盘中没有对应的文件实体,不会把内核缓冲区中的数据进行落盘和持久化。(这里也完全没必要进行落盘和持久化 ,因为进行磁盘IO是会降低效率的,且进程间通信产生的数据大部分都是临时数据)所有的进程间通信都是内存级通信
3. fork创建子进程,父进程的内核数据结构会拷贝一份,因为进程具有独立性,且这样做本身也是很有必要的。但是一个文件在OS内核中只会有一个对应的struct file,故父子进程文件描述符表中struct file*指向的是同一个struct file,这里struct file只有一份。这是OS的进程管理和文件管理,属于两个模块。
管道读写的4种情况:
1. 写慢,读快,则将管道里数据读完就会read阻塞等待,需要等待写端写入数据
2. 读慢,写快,管道写满就不能再写了,需要等待读端读取数据
3. 写端关闭,read不会阻塞,read读到管道结尾,返回0
4. 读关,写仍然在写,则OS会终止写端进程
(这里可以用demo代码进行测试验证)
管道的特点:
1. 这里的匿名管道适用于具有亲缘关系的进程之间进行进程间通信 - 常用于父子进程。(后面的命名管道文件可用于无关联的两个进程之间进行IPC)
2. 管道提供了访问控制,内核会对管道操作进行同步与互斥
(同步和互斥是相对专业的用语,访问控制其实就是管道读写的前两种情况,也就是读写双方会互相协同,而不是不管写端是否写数据,读端都一直读。
3. 管道提供流式的通信服务 - 面向字节流
4. 管道的本质就是文件,管道的生命周期随进程
5. 管道是单向通信的,半双工的(一方读,一方写),数据只能向一个方向传输。如果需要进程双向通信,则需创建两个管道。
管道IPC:命名管道
上方讲的匿名管道适用于有亲缘关系的两个进程之间进行IPC。其实用的就是文件描述符表继承机制,从而让双方进程看到同一份资源。
而对于没有亲缘关系的两个进程来说,无法利用文件描述符表的继承机制,但是也可以直接打开磁盘中的同一个文件,这样在OS内核中就只有一个struct file结构体,也实现了让两个进程看到同一份资源。
mkfifo - C标准库函数&&Linux命令 用于创建命名管道
mkfifo是Linux下的一个命令,可用于创建命名管道文件
$ mkfifo filename
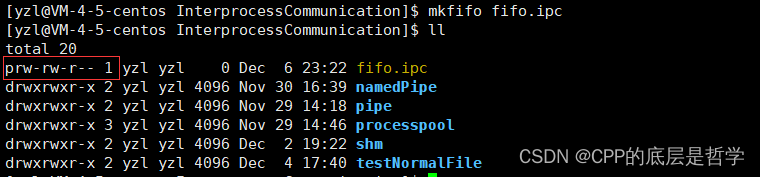
同时,mkfifo也是一个C标准库函数
int mkfifo(const char *filename,mode_t mode);
第一个参数为命名管道的绝对/相对路径,第二个参数为管道文件的权限设置。
命名管道的本质理解:
mkfifo C标准库函数,可用于创建一个命名管道(文件),此文件在磁盘中有对应文件实体,也就有了路径,而路径是具有唯一性的。
让两个进程打开磁盘中的同一命名管道文件,则路径的唯一性使得这两个进程使用open打开此fifo之后,文件描述符表中的struct file*指向的是OS内核中的同一个struct file(对应那个命名管道文件),这样就让两个进程看到同一份资源了。
注意:
此命名管道文件在内核缓冲区中的数据,依旧不会刷新到磁盘中,磁盘中那个命名管道文件,仅仅是一个文件名+属性,没有内容。
进程间利用命名管道文件进行IPC仍然是纯内存级的,因为不会进行落盘/持久化数据。
命名管道 vs 匿名管道
其实,匿名管道和命名管道都是基于文件的,本质都是利用文件,让两个进程看到同一份资源从而进行IPC。FIFO(命名管道)与pipe(匿名管道)之间的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的语义。
匿名管道使用的pipe可以创建并直接以读和写方式打开匿名管道文件(纯内存级,磁盘无对应实体)并利用文件描述符表的继承机制 让进程看到同一份资源从而IPC。
而命名管道文件是用mkfifo创建命名管道文件,之后,双方进程使用系统调用open分别以读和写方式打开这个fifo,实现IPC
匿名管道文件:pipe -> ipc
命名管道文件:mkfifo -> open -> ipc
对于管道的访问控制(同步与互斥),生命周期随进程,提供字节流服务,单向通信,半双工的特点,命名管道同样具有,因为本质都是管道...
命名管道示例代码:
comm.hpp
#ifndef _COMM_H_
#define _COMM_H_
#include <iostream>
#include <string>
#include <cassert>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <unistd.h>
#include "Log.hpp"
#define PATHNAME "/home/yzl/InterprocessCommunication/namedPipe/fifo.ipc"
#endifLog.hpp
#ifndef _LOG_H_
#define _LOG_H_
#include <iostream>
#include <ctime>
#define Debug 0
#define Notice 1
#define Warning 2
#define Error 3
const std::string msg[] = {
"Debug",
"Notice",
"Warning",
"Error"
};
// 输出日志信息,其实就是 时间戳+日志等级(日志用于做什么的标记)+信息。
std::ostream &Log(std::string message, int level)
{
std::cout << " | " << (unsigned)time(nullptr) << " | " << msg[level] << " | " << message;
return std::cout;
}
#endifmutiServer.cxx
#include "comm.hpp"
void getMessage(int fd)
{
// 三个子进程读取管道文件数据,随机一个子进程读取成功,也只会有一个。
char buffer[1024];
while (true)
{
ssize_t sz = read(fd, buffer, sizeof(buffer) - 1);
if (sz > 0)
{
buffer[sz] = '\0';
std::cout << "[ " << getpid() << " ] " << "client say : " << buffer << std::endl;
}
else if (sz == 0)
{
std::cout << "read end of file, client quit, server quit too" << std::endl;
break;
}
else
{
perror("server::read");
exit(3);
}
}
}
int main()
{
// 1. 创建命名管道
int ret = mkfifo(PATHNAME, 0666); // 000 110110110 rw-rw-rw- 受文件掩码影响
if (ret == -1)
{
perror("mkfifo");
exit(1);
}
Log("创建命名管道文件成功", Debug) << " step1" << std::endl;
// 2. 然后就是文件的常规操作了
// 因为这里是管道,所以,有一些和普通磁盘文件不同的地方
// 这里当写端进程没有打开管道文件时,这里open会阻塞
int fd = open(PATHNAME, O_RDONLY); // 只读打开
if (fd == -1)
{
perror("open");
exit(2);
}
Log("server只读打开命名管道文件成功", Debug) << " step2" << std::endl;
// 3. 利用命名管道文件进行通信
for(int i = 0; i < 3; ++i)
{
pid_t id = fork();
if(id == 0)
{
// 子进程,继承父进程的文件描述符,已经打开了命名管道文件,进行数据读取
getMessage(fd);
exit(0);
}
}
// 父进程等待
for(int i = 0; i < 3; ++i)
{
waitpid(-1, nullptr, 0); // 阻塞式等待随机一个子进程
}
Log("父进程等待三个子进程退出成功", Debug) << std::endl;
// 4. 读取结束,关闭文件
close(fd);
Log("关闭命名管道文件成功", Debug) << " step 3" << std::endl;
// 5. ipc结束,删除命名管道文件
unlink(PATHNAME);
Log("删除命名管道文件成功", Debug) << " step 4" << std::endl;
return 0;
}client.cxx
#include "comm.hpp"
int main()
{
// client只写打开管道文件,管道文件由server提供
int fd = open(PATHNAME, O_WRONLY);
if(fd == -1)
{
perror("client::open");
exit(1);
}
Log("client open fifo.ipc success", Debug) << std::endl;
// 写数据
std::string str;
std::cout << "Please input the message that you want to sent to server by fifo.ipc" << std::endl;
while(std::getline(std::cin, str))
{
write(fd, str.c_str(), str.size());
}
// 关闭文件
int n = close(fd);
assert(n == 0);
Log("client close fifo.ipc success(reader of named pipe)", Debug) << std::endl;
return 0;
}System V 共享内存 IPC
示意图
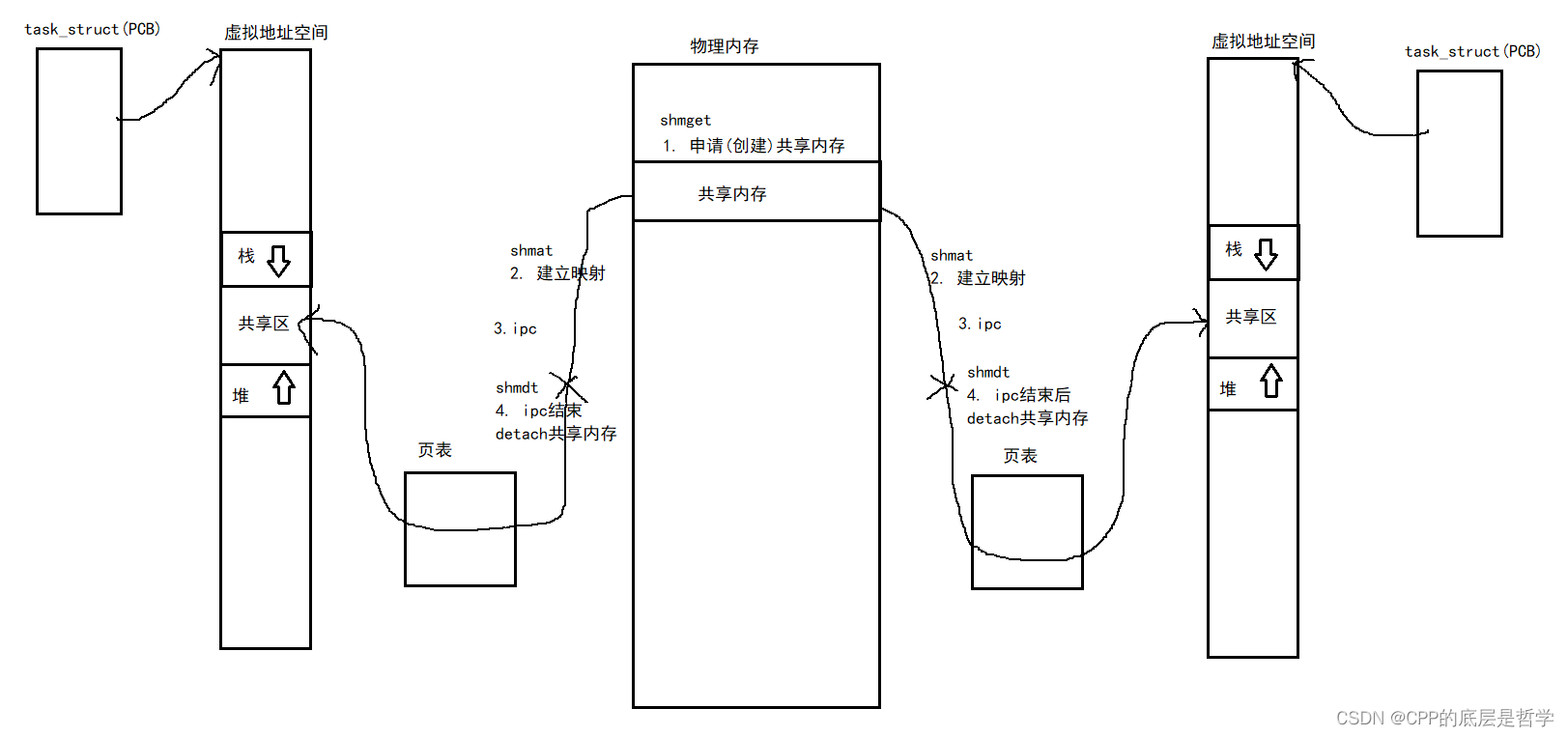
通过共享内存进行IPC:
进程间通信的前提是让不同进程看到同一份资源。
SHM:先在物理内存中创建(申请)一段共享内存(内存空间),再通过页表建立起这段内存空间(SHM)与进程的虚拟地址空间之间的映射关系,这样进程就可以使用虚拟地址通过页表映射直接访问这段物理内存,即可在多个进程之间进行进程间通信。
这段物理内存会被映射进虚拟地址空间中栈区与堆区之间的共享区(回顾,动态库的加载链接也是会被加载到共享区。)
在申请SHM,attachSHM之后,进程就可以像使用一段malloc出的内存空间一样使用这段SHM。这里和管道的使用方式和本质是有区别的,具体看下方。
共享内存的生命周期随操作系统,而不是随进程
共享内存本质理解(OS管理的角度)
对于共享内存的理解不能只理解为一段物理内存中的内存空间。共享内存的提供/管理者是操作系统,OS内可能会有很多共享内存,则OS必须要管理这些共享内存,管理的本质就是:先描述,再组织。所以,OS必须要对这些共享内存建立对应的内核数据结构,去描述这些SHM。
故,共享内存 = 共享内存块 + 共享内存对应的内核数据结构
所以,如果进程申请4096字节的共享内存空间,则OS为了这段共享内存所占用的内存空间一定大于4096字节(因为还有内核数据结构)
(其实管道也是需要管理的,只是管道的本质就是文件,所以管道管理 = 文件管理。而这里的共享内存是OS为了进程间通信单独设立的一个模块。)
共享内存IPC示例代码:
comm.hpp
#pragma once
#include <iostream>
#include <string>
#include <cassert>
#include <cstring>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/stat.h>
#include "Log.hpp"
#define PATH_NAME "."
#define PROJ_ID 306
#define SHM_SIZE 4096
#define WRITE O_WRONLY
#define READ O_RDONLY
#define FIFO_PATH "./fifo"
std::string transToHex(key_t key)
{
char buff[32];
snprintf(buff, sizeof(buff), "0x%x", key);
return buff;
}
// 利用命名管道进行访问控制
// 这里包含了命名管道文件的创建和删除,创建和析构对象时自动执行。还剩下打开,读写,关闭行为。
class Fifo
{
public:
Fifo()
{
int n = mkfifo(FIFO_PATH, 0666);
assert(n != -1);
(void)n;
Log("create FIFO success", Notice) << std::endl;
}
~Fifo()
{
unlink(FIFO_PATH);
Log("delete FIFO success", Notice) << std::endl;
}
};
// 打开一个文件的包装函数
int OpenFIFO(std::string pathname, int flags)
{
int fd = open(pathname.c_str(), flags);
assert(fd != -1);
return fd;
}
// 共享内存的读方调用Wait,利用管道的访问控制进行等待。
void Wait(int fd)
{
Log("等待中...", Notice) << std::endl;
uint32_t temp = 0;
ssize_t sz = read(fd, &temp, sizeof(uint32_t));
assert(sz == sizeof(uint32_t));
(void)sz;
}
// 共享内存的写方调用Awaken,利用管道的访问控制,唤醒管道读方,从而让共享内存的读方读取数据。
void Awaken(int fd)
{
Log("唤醒中...", Notice) << std::endl;
uint32_t temp = 0;
ssize_t sz = write(fd, &temp, sizeof(uint32_t));
assert(sz != -1);
(void)sz;
}
void CloseFIFO(int fd)
{
close(fd);
}shmServer.cc
#include "comm.hpp"
// 共享内存的server,创建共享内存,attach detach 删除
Fifo fifo;
int main()
{
// 1. 先创建Key
key_t key = ftok(PATH_NAME, PROJ_ID);
assert(key != -1);
Log("create key done", Debug) << " server key : " << transToHex(key) << std::endl;
// 2. 创建共享内存,建议创建一个全新的共享内存
// key所对应的共享内存不存在则创建,存在则报错,目的:创建一个全新的共享内存,要带权限
int shmid = shmget(key, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666); // 返回这个共享内存的标识符id,此时还没有和进程关联起来
if(shmid == -1)
{
perror("shmget");
exit(1);
}
Log("create shm done", Debug) << " shmid : " << shmid << std::endl;
// sleep(10);
// 3. attach共享内存 (上面shmget只是获取了共享内存的id,这里进行attach,将物理内存中的共享内存和自己的地址空间的共享区建立映射关系)
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
if(shmaddr == (void*)-1)
{
perror("server::shmat");
exit(2);
}
Log("attach shm done", Debug) << " shmid : " << shmid << std::endl;
// sleep(10);
// 4. 通过shm,进行ipc
int fd = OpenFIFO(FIFO_PATH, READ);
while(true)
{
Wait(fd); // 利用管道进行访问控制,等待写入!写入数据后,再进行读取
printf("%s\n", shmaddr);
if(strcmp(shmaddr, "quit") == 0)
break;
// sleep(1);
}
CloseFIFO(fd);
// 5. detach共享内存
int ret = shmdt(shmaddr);
assert(ret != -1);
(void)ret;
Log("detach shm done", Debug) << " shmid : " << shmid << std::endl;
// sleep(10);
// 6. 删除共享内存
// 共享内存的生命周期随OS,而不是随进程。并非attach的进程数到0就自动销毁。
// IPC_RMID即便是有进程和当下的shm挂接,依旧删除共享内存
ret = shmctl(shmid, IPC_RMID, nullptr);
assert(ret != -1);
(void)ret;
Log("delete shm done", Debug) << " shmid : " << shmid << std::endl;
return 0;
}shmClient.cc
#include "comm.hpp"
int main()
{
// 创建key
key_t key = ftok(PATH_NAME, PROJ_ID);
Log("create key done", Debug) << " client key : " << transToHex(key) << std::endl;
// 获取(创建、申请)共享内存
// int shmid = shmget(key, SHM_SIZE, IPC_CREAT);
int shmid = shmget(key, SHM_SIZE, 0);
if(shmid == -1)
{
perror("shmget");
exit(1);
}
Log("get shm done", Debug) << " shmid : " << shmid << std::endl;
// sleep(10);
// attach共享内存
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
if(shmaddr == (void*)-1)
{
perror("shmat");
exit(2);
}
Log("attach shm done", Debug) << " shmid : " << shmid << std::endl;
// sleep(10);
// 利用共享内存进行ipc
int fd = OpenFIFO(FIFO_PATH, WRITE);
// test3
while(true)
{
// 用键盘输入数据
// 事实证明,输入abc\n 则 sz = 4
ssize_t sz = read(0, shmaddr, SHM_SIZE - 1);
if(sz > 0)
{
Awaken(fd); // 确认写入共享内存数据后,利用命名管道的访问控制,唤醒读端
shmaddr[sz - 1] = '\0';
if(strcmp(shmaddr, "quit") == 0)
break;
}
}
CloseFIFO(fd);
// // test2
// // 果然,共享内存这块内存空间是完全类似于一段数组的,读写操作随意,且读操作只是读,不会进行清空操作。
// std::string s = "aaaaaaaaa";
// sprintf(shmaddr, "%s", s.c_str()); // aaaaaaaaa\0
// sleep(3);
// std::string s2 = "ccc";
// sprintf(shmaddr, "%s", s2.c_str()); // ccc\0
// shmaddr[s2.size()] = 'b';
// sleep(3);
// test1
// char c = 'a';
// for(; c <= 'd'; ++c)
// {
// shmaddr[c-'a'] = c;
// // snprintf(shmaddr, SHM_SIZE - 1, "My pid : %d, %c", getpid(), c);
// // 每隔2s写一次
// sleep(2);
// }
// detach共享内存
int ret = shmdt(shmaddr);
assert(ret != -1);
(void)ret;
Log("detach shm done", Debug) << " shmid : " << shmid << std::endl;
// client不需要删除共享内存
return 0;
}Log.hpp和命名管道那里一样,略了...
创建,attach,detach,删除共享内存的相关系统调用
1. key_t ftok(const char *pathname, int proj_id);
用于创建key值,第一个为随意一个文件路径,第二个为随意一个整数,创建的key值用于在内核层面标识每一个共享内存,创建共享内存shmget需要用到。
ftok函数内部就是算法,用于生成一个唯一的关键值。(类似哈希函数的道理),值无所谓,重点是要唯一。
2. int shmget(key_t key, size_t size, int shmflg);
用于创建/获取共享内存,即在物理内存中申请一段共享内存空间。第一个参数为ftok创建的key值,第二个为共享内存段空间大小(最好是页的整数倍(4kb,4096字节),避免资源浪费,因为你申请4097,则OS创建的SHM段大小也为8kb),第三个参数为宏的组成,IPC_CREAT IPC_EXCL 共享内存权限设置的组合。
IPC_CREAT | IPC_EXCL:若key对应的SHM不存在,则创建,并返回SHM的用户层shmid,若已经存在,则出错返回(SHM的创建者可以使用这个,因为这样可以保证SHM一定是全新的)
IPC_CREAT:若key对应的SHM已经存在,则返回,不存在,则创建并返回。
注意SHM创建进程要加SHM的权限设置。
3. void *shmat(int shmid, const void *shmaddr, int shmflg);
建立共享内存和进程虚拟地址空间的映射关系,关联/attach起来。shmid即shmget返回的SHM在用户层的标识符(类似文件描述符),后面两个设置为nullptr和0即可... 略了..
4. int shmdt(const void *shmaddr);
解除共享内存和进程虚拟地址空间的映射关系,进行detach。参数为shmat的返回值,即共享内存的虚拟地址。
5. int shmctl(int shmid, int cmd, struct shmid_ds *buf);
用代码,系统调用删除共享内存。
shmctl(shmid, IPC_RMID, nullptr)即可
shmget的第一个参数 key值 和 返回值shmid的关系:
key值,是当进程间想通过共享内存进行IPC时,用key值在OS内核层面标识每个共享内存的唯一性。 这样,两个进程通过同一个key值,就可以获取到同一个共享内存,这里shmget的返回值是用户层共享内存的一个id值,类似open的返回值文件描述符。
后面进行shmat shmctl都是使用shmid,而key,仅仅是在shmget,创建/获取该共享内存时,帮助进程间获取到同一个共享内存。
key是在内核层面标识共享内存。shmid是在用户层标识共享内存。
Linux关于共享内存的命令:
ipcs -m 查看当前OS中所有的共享内存
key shmid owner perms(权限) bytes(共享内存大小) nattach(该SHM挂接的进程数量)
ipcsrm -m shmid
使用命令删除一个共享内存。 共享内存的生命周期随OS,而不是随进程,若某进程创建共享内存,attach,detach,而没有删除,则进程结束,该共享内存不会自动销毁。
从虚拟地址空间角度理解共享内存和管道的区别
共享内存机制:在物理内存中申请一段内存空间,通过用户空间页表(页表分为用户空间页表和内核空间页表)建立起物理内存和进程的虚拟地址空间之间的映射关系,具体映射到虚拟地址空间中的堆栈间的共享区。这样,进程就可以使用shmat返回的虚拟地址通过用户空间页表映射直接访问这段物理内存,这是不需要OS内核的。
而虚拟地址空间分为0~3G的用户空间和3~4G的内核空间,上方的共享区就是在用户空间中。进程可以直接访问用户空间,但是不能直接访问内核空间,访问内核空间需要通过系统调用。
管道机制:管道机制的本质是文件机制,进程间通过访问内核中的同一个文件,从而看到同一份资源进行IPC,而不管是匿名管道还是命名管道,本质都是内核中的struct file以及文件的内核缓冲区。这部分数据本身是存储在物理内存中的,通过内核空间页表映射到虚拟地址空间的内核空间中,这就是为什么进程间通过管道通信需要使用write,read这样的系统调用,因为内核空间的访问必须通过系统调用。(这里也是虚拟地址空间机制对于物理内存的保护的体现)
共享内存的特点:
1. 共享内存是最快的进程间通信方式,一旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到内核,换句话说是进程不再通过执行进入内核的系统调用(如read,write)来传递彼此的数据
比如:管道这样的ipc,写端:键盘输入数据,到我们用代码定义的缓冲区中,之后用write写入到内核中的管道文件缓冲区中。读端:通过read系统调用读取管道文件缓冲区中的数据,到字符数组中(缓冲区),再用printf打印出来。 这里面经过了4次拷贝(不考虑文件的用户层缓冲区,即标准库定义的缓冲区)
而共享内存,我们可以直接用键盘向共享内存中写入,再用printf直接打印出共享内存中的数据,这是2次拷贝。
4次与2次拷贝直接决定了共享内存是最快的ipc方式,本质还是因为通过共享内存进行IPC不用通过操作系统内核传递数据,而是直接访问物理内存。
2. 共享内存缺乏访问控制,共享内存没有进行同步与互斥
上方示例代码中,server端运行起来后,不管client端有没有执行,不管这个共享内存的attach进程数是几个,有没有人写入,server端都是一直读取,这是缺乏访问控制的表现。(上方代码中,利用管道,增加了访问控制)
3. 共享内存的生命周期随操作系统,不同于管道的生命周期随进程
如果不进行shmctl 和 命令行上的ipcsrm -m,则进程结束后,共享内存仍然存在。