目录
- 1. 背景
- 2. 质量分 version 5
- 2.1 version 4 存在问题分析
- 2.2 version 5 改进
- 2.3 消融分析
- 2.3.1 正向积极得分消融实验
- 2.3.2 正向累积得分单变量实验
- 2.3.3 非高分文章消融实验
- 2.4 V4 和 V5 版本质量分分布对比
- 3. 总结
- 4. 参考
1. 背景
博客质量分顾名思义是用于衡量一篇博客的质量,其在 CSDN 的热榜、推荐、搜索等多个模块中发挥着关键性的作用。下图是质量分的工作机制:

先回顾一下,在第 4 版本 (后续称为 V4) 的质量分中,主要对得分进行了平滑,使得质量分结果分布更均匀,不会过度集中在头部 [80, 100] 和尾部 [0, 20),详见博客。
但是,在 V4 的质量分体系中无明显层次结构 (也可称为可解释性),即博主在博文中加入新的元素 (例如:图片、链接、代码等),质量分没有按阶梯式增高,在博文中加入一些影响阅读的元素之后 (例如:死链、虚假链接、代码混乱等) ,质量分也没有按阶梯式降低。
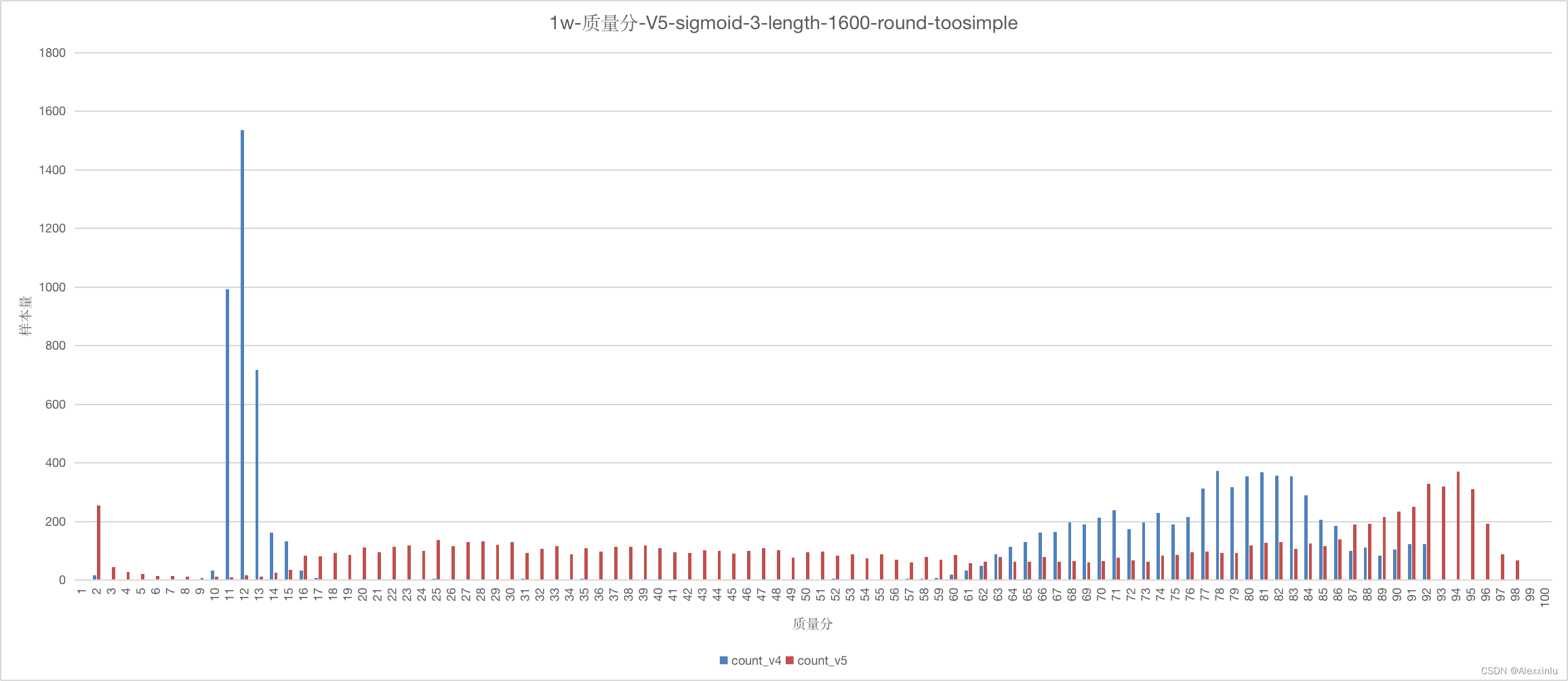
此外,虽然 V4 的质量分分布更加均匀,但还是不够,详见图 5,该图随机统计了 1 万篇博客质量分的分布情况,其中蓝色部分的柱状图是 V4 的质量分分布情况,可以看出得分主要分布在 [0, 20] 和 [50, 94] 两个区间段。
针对上述问题,第 5 版本 (后续称为 V5) 的质量进行了一系列的改进,在保证 V4 高质量博客数据保留约 90% 的情况下 (即 V4 中 80 分以上的博客在 V5 中有约 90% 仍在 80 分以上) ,得分分布更均匀,质量分体系层次结构也更清晰。
接下来,将对第 5 版本质量分的改进进行详细阐述。
2. 质量分 version 5
2.1 version 4 存在问题分析
下图是 V4 版本质量分计算流程:

从图 2 可以看出,V4 版本质量分计算流程存在以下问题:
- 正向积累得分中,目录 和 标准目录 作为两个不同的项,存在冗余;
- sigmoid 归一化中,sigmoid 函数将得分强制映射到了 (0.5, 0.938), 使得 0.5 和 0.938 以下的得分极少出现,此外 (此处得分为缩放前的得分,取值为[0, 1]);
- sigmoid 归一化应该放在最后阶段,而不是中间阶段;
- 文章是否有投票 可以直接放到正向累加得分中;
- 计算逻辑中只有正向积累得分 (亦称加分项) 和惩罚项,而没有减分项。从得分系统设计逻辑的完备性来看,应该分为以下三个部分:
- 加分项:从0到1,逐步加分;
- 减分项:从1到0,逐步减分;
- 强惩罚因子:严重违规的情况,直接乘以一个较低的惩罚因子,例如:0.1, 0.2。
此外,除了上述计算流程上的问题,V4 版本的质量分在多个得分项上面还存在以下问题:
- 代码得分:可理解为代码量得分,英文为
lines of code,即代码的行数,而 V4 版本中的计算方式是代码中 token 的数量; - 各子得分项不够平滑:以 内容长度得分 为例,使用的是 Min–max normalization (代码如下所示),该归一化方法存在截断的情况,如果输入值大于最大值,则得分就不会发生变化了,并且也不够平滑,例如:
-
内容长度得分,如果文章长度的最大值是 2000,文章 1 的长度为 2000,文章 2 的长度是 3000,则文章 1 和文章 2 的得分是一样的。
-
目录得分,目录得分是基于正文中的多级子标题的数量进行计算的,标题数越多,则得分越高。V4 版本直接使用的是 Min–max normalization,其中 min = 0,max = 10。该归一化方法不够平滑,如果博文中只有 2 个子标题,则得分只有 0.2,但质量分的初衷是鼓励用户正确使用多级标题,有的文章确实不需要过多的多级标题,可能 2 个子标题就可以将文章结构划分得很清楚,即 2 个子标题应该得到 0.5 以上的得分。
def min_max_normalization(value, max_value, min_value): if value > max_value: value = max_value if value < min_value: value = min_value if min_value > max_value: tmp_value = max_value max_value = min_value min_value = tmp_value norm_value = (value - min_value) / (max_value - min_value) return norm_value
-
2.2 version 5 改进
针对 V4 版本中存在的问题,V5 版本进行了相应的改进,改进后的计算流程如下图所示:

从图 3 可以看出,V5 版本针对 V4 版本在计算流程方面进行了如下改进:
- 将 目录 和 标准目录 进行合并,统一为目录得分;
- sigmoid 在进行平滑时候,放到了最后一个阶段,并且新的 sigmoid 函数映射的得分区间为 (0.017, 0.983),相比之前的 (0.5, 0.938),得分分布更加均匀,函数图像如下所示:

- 文章是否有投票 直接放到了加分项中;
- 计算逻辑直接拆分成了三个部分:加分项、减分项和强惩罚项;
- 新增 非 IT 技术文章 减分项
- 文章结构太简单 从强惩罚因子变为减分项,因为文章结构简单已经在 文章内容长度得分 以及 标签多样性得分 等多个地方有所体现,故无需进行强惩罚;
- 新增 图片得分;
- 优化各个子加分项权重,使得分呈阶梯式增高或降低;
- 计算流程最后一步的得分取整
int(score * 100)改为round(score * 100),因为 python 中的 int() 默认是向下取整,round 是四舍五入。
此外,除了计算流程上的优化,V5 版本还对每个字得分项上的计算逻辑进行了优化,具体如下:
- 代码得分 直接使用代码行数以及代码块个数进行衡量;
- 针对多个子得分项不够平滑的问题,V5 中减少了 Min–max normalization 函数的使用,改为使用分段函数,或者其他更为平滑的曲线。V5 版本针对 内容长度得分、目录得分、代码得分、内容长度得分、链接得分、图片得分 等多个子得分项进行了平滑以及计算逻辑微调,例如:
- 对于 内容长度得分 中的截断问题,使用分段函数处理
def __cal_content_length_score(self, content): """ 计算内容长度得分 v5 """ content_len_base = self.content_len_range["max"] / 2 content_len_cut_off_point = sigmoid(self.content_len_range["max"] / content_len_base) content_len = len(content) # 分段函数,平滑内容长度较大时的得分 if content_len <= self.content_len_range["max"]: score = min_max_normalization( content_len, self.content_len_range["max"], self.content_len_range["min"]) score *= content_len_cut_off_point else: score = sigmoid(content_len / content_len_base) return score - 对于 目录得分 中不够平滑问题,使用幂函数进行平滑
def __cal_heads_toc_score(self, sample): """ 计算目录得分 v5 """ # 1. 正文中的多级标题 (即 h1, h2, h3, h4) 得分 heads_list = sample["catalog"] heads_num = len(heads_list) # 平滑,当 heads_num 较小时,得分变化不至于过小 heads_score = min(math.pow(heads_num / self.heads_num_para["max"], 0.25), 1) # 2. toc 得分 if "toc" in sample: toc_score = 1.0 else: toc_score = 0.0 # 3. 加权 score = heads_score * self.heads_toc_weight["heads"] \ + toc_score * self.heads_toc_weight["toc"] return score
- 对于 内容长度得分 中的截断问题,使用分段函数处理
2.3 消融分析
本文进行了部分消融实验,测试各个 V5 版本中各个因素的影响:
2.3.1 正向积极得分消融实验
通过逐步去掉影响质量分的某个要素,观察质量分的变化。
下表中,质量分-V5-sigmoid 表示 V5 版本最终的质量分,质量分-V5-base 表示 V5 版本 sigmoid 平滑前的质量分。由于 sigmoid 函数的特性 (函数图像见图 4),会平滑掉高分段和低分段分数的差异性,中分段的差异性会更加明显,这也符合一个常识性假设:“分数越高,就越难提升分数”。
因此,为了观察每个要素对质量分的影响,对比 质量分-V4 和 质量分-V5-base 即可。从下表中标红的得分可知,V5 版本要优于 V4 版本,V5 版本更能体现随着要素的减少,质量分呈现阶梯式的降低。
| 博客 | 质量分-V4 | 质量分-V5-base | 质量分-V5-sigmoid | 长度 | 标题 | 图片 | 链接 | 目录 | 标准目录 | 代码 | 投票 | 元素多样性 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 测试博客1 | 91 | 97 | 98 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 8 |
| 测试博客2 | 91 | 92 | 97 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 8 |
| 测试博客3 | 89 | 86 | 95 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 7 |
| 测试博客4 | 83 | 84 | 95 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 6 |
| 测试博客5 | 82 | 81 | 93 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 6 |
| 测试博客6 | 79 | 75 | 90 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 4 |
| 测试博客7 | 78 | 70 | 84 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 4 |
| 测试博客8 | 76 | 65 | 78 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 |
| 测试博客9 | 76 | 64 | 77 | 0.75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 |
| 测试博客10 | 76 | 62 | 76 | 0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 |
| 测试博客11 | 68 | 46 | 55 | 0.25 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 |
| 测试博客12 | 10 | 23 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
2.3.2 正向累积得分单变量实验
通过每次只去掉一个影响质量分的某个因素,观察质量分的变化。
理由同上,直接对比 质量分-V4 和 质量分-V5-base,从下表中标红的得分可知,V5 版本要优于 V4 版本,每去掉一个要素,V5 版本的得分降低更加明显。
| 博客链接 | 质量分-V4 | 质量分-V5-base | 质量分-V5-sigmoid | 长度 | 标题 | 图片 | 链接 | 目录 | 标准目录 | 代码 |
|---|---|---|---|---|---|---|---|---|---|---|
| 测试博客1 | 91 | 92 | 97 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 测试博客2 | 89 | 86 | 95 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 测试博客3 | 86 | 90 | 97 | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
| 测试博客4 | 91 | 88 | 96 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 测试博客5 | 91 | 88 | 96 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| 测试博客6 | 91 | 87 | 96 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| 测试博客7 | 90 | 87 | 96 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| 测试博客8 | 91 | 92 | 97 | 0.75 | 1 | 1 | 1 | 1 | 1 | 1 |
| 测试博客9 | 90 | 91 | 97 | 0.5 | 1 | 1 | 1 | 1 | 1 | 1 |
| 测试博客10 | 89 | 86 | 95 | 0.25 | 1 | 1 | 1 | 1 | 1 | 1 |
| 测试博客11 | 15 | 52 | 58 | 0.1 | 1 | 1 | 1 | 1 | 1 | 1 |
2.3.3 非高分文章消融实验
上述两个对比实验使用的是高分文章,由于 sigmoid 在高分段平滑性强的影响,很难看出差异性。为了进一步证明 V5 版本的优势,下表是非高分文章的对比实验,可以看出,V5 版本的质量分变化更加平滑。最明显的例子就是第 1 行和第 2 行的数据,使用 V4 版本测试时,在第1 行的 12 分博客的基础上,逐字逐句地增加博客的长度, 质量分会从 12 分一下跳到 70 分,而 V5 版本的变化是均匀的。
| 博客 | 质量分-V4 | 质量分-V5 |
|---|---|---|
| 软件测试的案例分析 - 闰年1 | 12 | 30 |
| 软件测试的案例分析 - 闰年2 | 70 | 54 |
| 软件测试的案例分析 - 闰年3 | 67 | 41 |
| 软件测试的案例分析 - 闰年4 | 71 | 60 |
| 软件测试的案例分析 - 闰年4.1 | 73 | 71 |
| 软件测试的案例分析 - 闰年4.2 | 84 | 84 |
| 软件测试的案例分析 - 闰年4.2 (加投票) | 85 | 89 |
| 软件测试的案例分析 - 闰年5 | 83 | 95 |
2.4 V4 和 V5 版本质量分分布对比
随机抽取 10000 条博客数据,对比V4 和 V5 版本质量分分布情况,由下图可知,相比 V4 (蓝色部分) 版本,V5 版本 (红色部分) 的分布更加均匀,得分的覆盖范围也更广。
3. 总结
质量分 V5 版本进行了较大的更新,由 2.3 节的对比实验可知,相比 V4 版本,随着文章内容的变化,V5 版本的得分变化更加均匀与合理。同时,由 2.4 节的分布对比可知,V5 版本的得分分布更加均匀,分布覆盖范围也更广。这些变化进一步带来的好处就是质量分变化的 可解释性 更强。
除了上述主动的优化,在修改代码的过程中,还发现了若干隐藏的 Bug,进一步确保了质量分计算的正确性。
此外,为了避免新版本 V5 对 V4 版本中高质量博客 (80 分以上) 的影响,通过函数变换,保证 V4 版本中约 90%的高质量博客仍在 80 分以上。
最后,希望各位用户多多提宝贵的建议,您的建议是我们后续持续优化的动力,感谢!
4. 参考
- 博客质量分计算(三)——发布 version 4
- 博客质量分计算(二)
- 博客质量分计算(一)
- CSDN-AI小组2023-半年-研发总结