整理一道颇具争议的题目
#include<stdio.h>
#define Mul(x,y) ++x*++y
int main()
{
int a=1,b=2,c=3;
printf("%d",Mul(a+b,b+c));
}
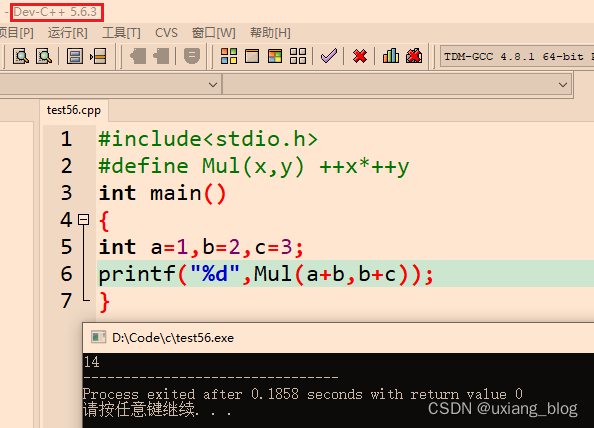
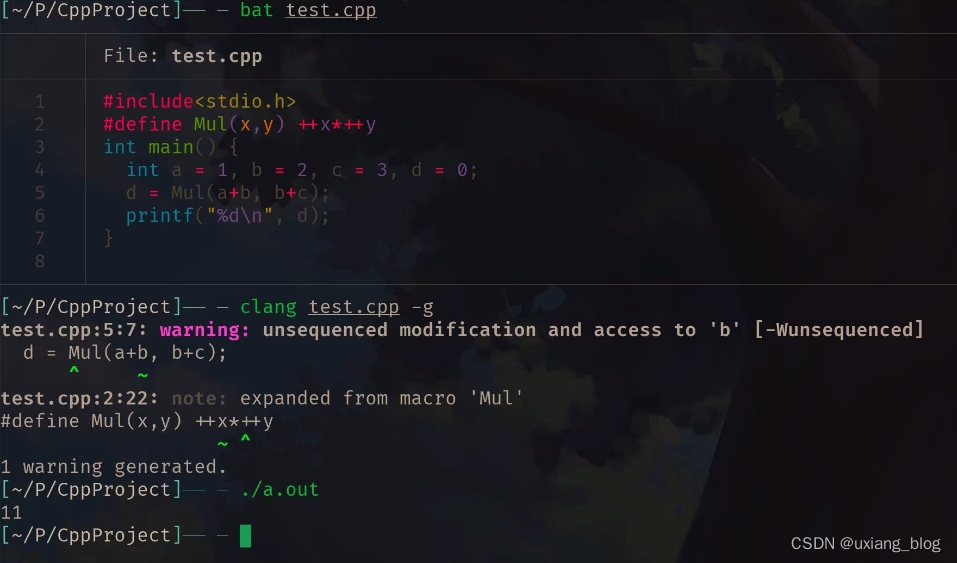
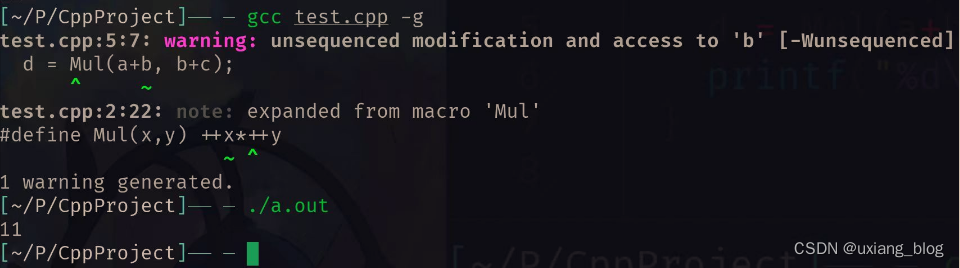
关于这道题目,根据不同的编译器,答案会出现两种答案 11和14,见下面:
关于dev C++:
关于clang
关于gcc
为了看清楚这个问题究竟是哪里出现问题了,先做一个简化处理,我修改了一下这个程序,使得问题出现的地方更加明显。
#include<stdio.h>
#define Mul(x,y) ++x*++y
int main()
{
int a=1,b=2,c=3;
printf("%d",Mul(a+b,b+c));
}
//计算过程为++a+b*++b+c,
//其中“++a”,和“c”的部分没有任何问题,它们两个算出的结果“++a+c”为5,那么就剩下b*++b就是问题所在。
//当然这些定位是根据一番debug,才得到把问题的关键点定位到了b*++b这个地方的,知道了什么地方出问题了,由此并作简化处理。
#include<stdio.h>
#define Mul(x,y) x*++y
int main()
{
int b=2;
printf("%d\n",Mul(b,b));
}
//这样就会得到一下两种结果,这就是为什么会出现11和14的结果。
//2*3 = 6;6+5=11
//3*3 = 9;9+5=14
那造成这两种答案的根本答案是什么?只是编译器不同造成的吗?当然不是,继续探究后发现了真相。以下是两位大佬的回答。
A:f(x)g(x)在规范里没有规定先计算f()还是g(), b++b在不同编译器下表现就不一样了。
还给出了书上的原话:
例如,在形如
x=f()+g();
的语句中,f()可以在 g()之前计算,也可以在 g()之后计算。因此,如果函数 f或g改变了另一个函数所使用的变量,那么 x 的结果可能会依赖于这两个函数的计算顺序。为了保证 特定的计算顺序,可以把中间结果保存在临时变量中 。函数调用、嵌套赋值语句、自增与自减运算符都有可能产生"副作用’–在对表达式 求值的同时,修改了某些变量的值。在有副作用影响的表达式中,其执行结果同表达式中的 变量被修改的顺序之间存在着微妙的依赖关系,下列语句就是一个典型的令人不愉快的情况:
a[i]=i++;
问题是·数细下标;是引用旧值还是引用新值?对这种情况编译器的解释可能不同,并因此 产生不同的结果。C 语言标准对大多数这类问题有意未作具体规定。表达式何时会产生这种副 作用(对变量赋值),将由编译器决定,因为最佳的求值顺序同机器结构有很大关系
----------来自于《C程序设计语言 第2版》。
B:是的 主要是由于这些副作用,代码到真正的机器执行运行,中间还有个编译器在帮你做一些修改,编译器会决定一些不明确行为到底应该怎么做最合适。一些支持函数式编程的语言就在尽量避免这个问题,一切皆表达式,每个表达式都有一个对应确定的类型。
没错,就是C语言中对计算顺序没有做规定,编译器会对这些不确定做最适合的调整,所以才是有不同的结果,也算是C语言的缺憾吧,当然人无完人,何况是编程语言了,但是只要防止这些缺陷,注意这些缺陷,避免这些缺陷,就能达到最完美的效果!因为中间有些自己的从不正确的想法逐渐得到了修正,特此记录,以便巩固。