目录
- 1 淘汰策略
- 1.1 配置
- 1.2 哪些数据将会被淘汰呢?
- 1.2.1 过期key中的
- 1.2.2 所有的key
- 1.2.3 禁止淘汰
- 2 持久化
- 2.1 背景
- 2.1.1 概念
- 2.1.2 fork进程写时复制机制
- 2.1.3 大key
- 2.2 redis持久化的方式
- 2.2.1 aof
- 2.2.2 aof-rewrite
- 2.2.3 rdb
- 2.3 redis持久方案的优缺点
- 2.4 大key对持久化的影响
- 3 高可用性
- 3.1 背景
- 3.2 主从复制
- 3.3 哨兵模式
- 3.4 cluster 集群
- 3.5 hiredis-cluster 安装编译
1 淘汰策略
1.1 配置
redis内存是有限制的,当存储的数据超过限制之后,就有一些数据从内存中被淘汰(被删除掉)
在redis.conf中配置,例如 :
- maxmemory # 配置内存,一般为物理内存的一半,涉及到写时复现,具体看面的章节
- maxmemory-policy noeviction # 选择LRU,LFU,TTL
- maxmemory-samples 5 # 最大样本数,在样本中运行LRU,LFU,TTL等策略
- maxmemory-eviction-tenacity # 参数指定内存驱逐韧性
。。。
1.2 哪些数据将会被淘汰呢?
1.2.1 过期key中的
保存在redisDb dict *expires
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
clusterSlotToKeyMapping *slots_to_keys; /* Array of slots to keys. Only used in cluster mode (db 0). */
} redisDb;
用到的策略有以下4种:
- LRU Least recent use 最长时间没有使用的淘汰
- LFU Least Frequently Used 最少使用次数的淘汰,数据量大的时候,也是要先采用随机采样的方式。
- TTL 最近要过期的 TTL(Time-to-Live)是一个网络术语,指数据包或者消息在网络中允许存在的时间长度。
- 随机策略 # 当内存达到最大后,随机淘汰
这些策略怎么配置呢?要么是配置定的阀值,抽取一定量的样本(数据量比较大的时候)。
这里着重了解一下LRU,LFU,它们对应的代码:(lru用24字节表示,当它表示LRU的时候用的是24个字节;当它表示LFU时,前8个字节表示最少使用次数,后16个字面表示时间)
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
eg: 通过object命令来演示lru
127.0.0.1:6379> object help
1) OBJECT <subcommand> [<arg> [value] [opt] ...]. Subcommands are:
2) ENCODING <key>
3) Return the kind of internal representation used in order to store the value
4) associated with a <key>.
5) FREQ <key>
6) Return the access frequency index of the <key>. The returned integer is
7) proportional to the logarithm of the recent access frequency of the key.
8) IDLETIME <key>
9) Return the idle time of the <key>, that is the approximated number of
10) seconds elapsed since the last access to the key.
11) REFCOUNT <key>
12) Return the number of references of the value associated with the specified
13) <key>.
14) HELP
先设置key为hello,再查看key存在的时间,发现是38秒。这个38秒就是存在lru中的
127.0.0.1:6379> set key hello
OK
127.0.0.1:6379> object idletime key
(integer) 38
1.2.2 所有的key
同上一小节1.2.1,只是减少了TTL策略
- LRU Least recent use 最长时间没有使用的淘汰
- LFU Least Frequently Used 最少使用次数的淘汰
- 随机策略 # 当内存达到最大后,随机淘汰
1.2.3 禁止淘汰
no-eviction:当内存达到最大后,新数据不能写入,会报错
2 持久化
2.1 背景
2.1.1 概念
保存在内存中的数据,在关机后,数据会消失,如果在关机、断电前将数据保存在磁盘中,
重新开机后再把数据从磁盘读入到内存中,这就是持久化。
对于redis就是:内存数据库,redis重启需要加载回原来的数据。
2.1.2 fork进程写时复制机制
- fork子进程时将父进程的页表复制,两个页表一样,它们都映射到同一块物理内存
此时如果要修改内存数据?与子进程之间不就冲突了吗?===> 解决:复制页表的时候,会把页表的每一项都设置为只读状态,父进程依然对外提供服务。 - 因此父进程对数据进行修改时,因为页表只读,写保护中断,从而触发缺页异常,进而进行物理内存的复制(相关页的)
- 父进程的页表修改可读写状态,然后指向新的物理内存
- 子进程的页表指向原来的物理内存
- 在发生写操作的时候,系统才会去复制物理内存
- 避免物理内存的复制时间过长导致父进程长时间阻塞
优点:
- 有独立的运行环境去持久化。
- 只要是父进程没有修改的内存页,子进程与父进程所对应的数据还是一样的。
2.1.3 大key
- kv 中 v 如果占用大量空间
比如v是hash、zset,里面存储了大量的元素。
2.2 redis持久化的方式
2.2.1 aof
aof 基于redis协议,有修改就在当前进程中追加到文件末尾(append only file)
通过系统调用write将数据写到page_buf,然后通过手动sync/fsync 刷到磁盘,或者内核刷到磁盘。
- always 每一个写的命令,持久化一次 在主线程(可能会阻塞) redis.conf: appendonly = yes
- every_sec 在bio_aof_fsync 线程进行(不阻塞主线程)
- no 不用aof持久化的方式,即redis.conf: appendonly no
相关的设置===>redis.conf中查找:appendonly appendfilename appenddirname appendfsync
auto-aof-rewrite-percentage auto-aof-rewrite-min-size
比如下面的两条命令
aof-
127.0.0.1:6379> set tt2 2
OK
127.0.0.1:6379> set ttt3 3
OK
对应的保存在appendfilename "appendonly.aof"里面的数据是
*3
$3
set
$3
tt2
$1
2
*3
$3
set
$4
ttt3
$1
3
redis重启恢复的时候,就可以按照上面redis协议存储的数据来恢复。
2.2.2 aof-rewrite
相对于aof,可以避免重复的命令, eg:
set key1 1
set key1 2
这两条命令即可以优化为set key1 2
工作原理:fork进程,根据内存数据生成aof文件,避免同一个key的历史冗余数据,
在重写aof期间,对redis的写操作会记录到重写缓冲区,当重写aof结束后,附加到aof文件的末尾。
2.2.3 rdb
- rdb 通过fork子进程持久化,基于内存所有数据对象编码直接持久化
- rrdb-aof 混用,通过fork子进程,根据内存数据生成rdb文件;在rdb持久化期间,
对redis的写操作会记录到重写缓冲区,当rdb持久化结束后,附加到aof文件末尾。
2.3 redis持久方案的优缺点
-
aof
优点:数据可靠,丢失较少;持久化过程代价较低
缺点:aof文件过大,数据恢复慢 -
rdb
优点:rdb 文件小,数据恢复快
缺点: 数据丢失较多,持久化过程代价较高 -
混合持久化
从上面知道,rdb 文件小且加载快但丢失多,aof 文件大且加载慢但丢失少;
混合持久化是吸取 rdb 和 aof 两者优点的一种持久化方案;
aof-rewrite 的时候实际持久化的内容是 rdb,等持久化后,持久化期间修改的数据以 aof 的形式附加到文件的尾部;
混合持久化实际上是在 aof-rewrite 基础上进行优化;所以需要先开启 aof-rewrite;
配置:
# 开启 aof
appendonly yes
# 开启 aof复写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 开启 混合持久化
aof-use-rdb-preamble yes
# 关闭 rdb
save ""
# save 3600 1
# save 300 100
# save 60 10000
2.4 大key对持久化的影响
- fsync压力大,数据刷磁盘时间长
- fork的时间长,fork的时候,写时复制造成的持久化时间长
时间长,断电、宕机的影响就会非常的大。
3 高可用性
3.1 背景
工作中重要的服务器一般会有异地备份,如果某个一个服务器坏了,还可以从异地服务器中去恢复。
核心概念:
== 主从复制 是高可用性的基础 ==
1 解决单点故障的问题
2 高可用方案的基础
3.2 主从复制
-
redis采用异步复制,主从之间存在数据不一样的情况,一般都是从服务器发起建立连接的请求,同步数据的请求。
可以是全量数据同步,也可以是增量数据同步,可能带来数据丢失。 -
runid : 标识身份,从数据库须持有与主数据库有相同的runid。
-
环形缓冲区:主数据中有一个环形缓冲区记录同步状态。某个从数据库发送“复制偏移量”到主数据库,
如果它在环形缓冲区,可以进行正常的同步数据,否则,需要全量同步数据。 -
主从复制不能保证高可用(合理时间内有合理的回应),解决了闪电战故障的问题
-
主节点宕机,整体系统没有什么可用性。从而引出下一节,主redis可被取代的哨兵模式。
3.3 哨兵模式
稍作了解,原理图如下:
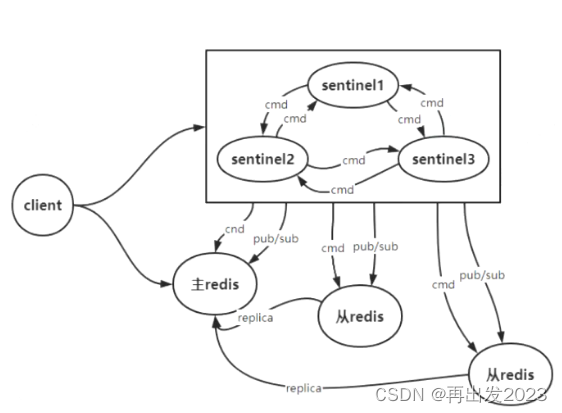
client与哨兵系统建立连接,监听switch-master 主从切换。
通过哨兵系统结点sentinel 不停的探测主redis,与从redis,当主redis宕机后,会分配一个从redis来当redis。
相当于网络中的探活机制
- 网络协议栈 tcp-keepalive
- 应用层 心跳包/ ping/pong(redis) 看网络主循环是不是在运行,应用层有没有死机
当主redis宕机时,哨兵系统可以根据“复制偏移量”谁大谁最新,确立新的主redis。
缺点:架构太复杂,部署麻烦,也不能避免数据丢失。主从切换花的时间需要几十秒,时间较长。
3.4 cluster 集群
可护展,去中心化的集群
图片来源于网络
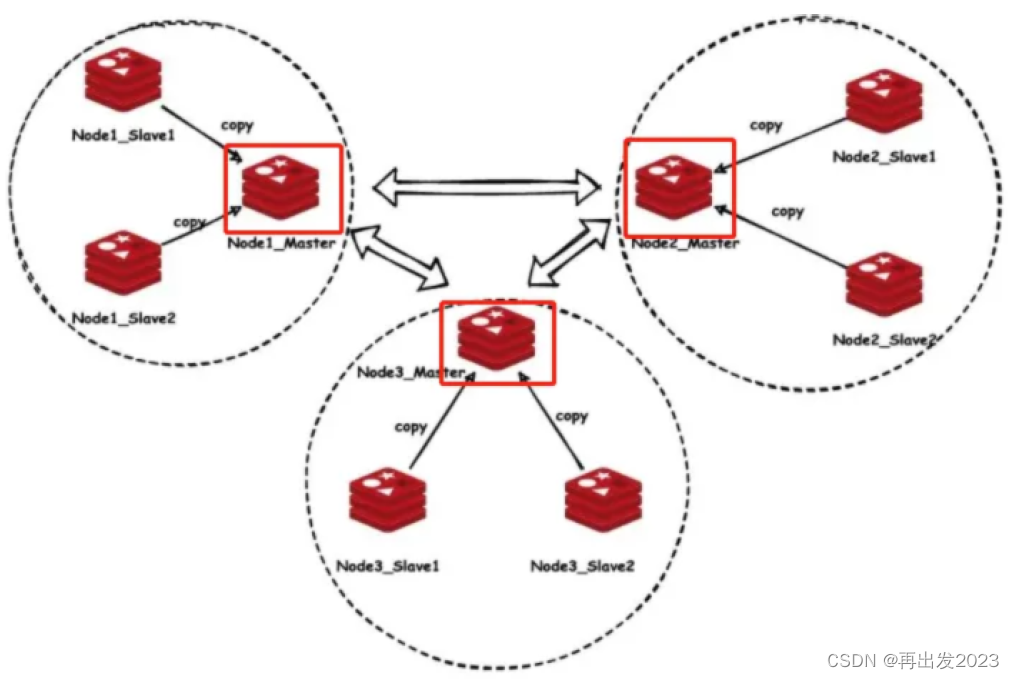
图中有3个主节点,每个主节点各带2个从节点。
- 三个主节点相当于哈希数组的3个槽位,分别用来存储某一个范围的数据(类似于分布式一致性hash),因此主节点存储的数据是不一样的,去中心化的。
- 可以从任何一个节点去进入集群。
- 可以扩容,增加一个主节点,再给它一个hash槽位,分配存储一定范围的数据,可以从之前的主节点的数据迁移一部分过去,之前主节点的数据范围也需要改变。
3.5 hiredis-cluster 安装编译
git clone https://github.com/Nordix/hirediscluster.
git
cd hiredis-cluster
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=RelWithDebInfo -
DENABLE_SSL=ON ..
make
sudo make install
sudo ldconfig
智能创建集群
redis-cli --cluster help
# --cluster-replicas 后面对应的参数 为 一主对应几个从数据库
redis-cli --cluster create host1:port1 ...
hostN:portN --cluster-replicas <arg>
redis-cli --cluster create 127.0.0.1:7001
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004
127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
具体的实验部分,后续更新。。