MQ
MQ的基本概念
MQ全称Message Queue(消息队列),实在消息的传输过程中保存消息的容器。多用于分布式系统之间的通信。
分布式系统的两种通信方式:直接调用、借助第三方间接完成
发送者成为生产者,接受者称为消费者
MQ的优势和劣势
优势:
- 应用解耦:提高容错性和可维护性
- 异步提速:提升用户体验和系统吞吐量
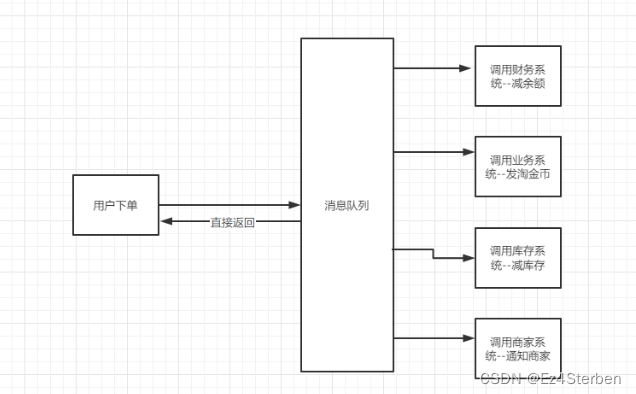
- 削峰填谷:提高系统稳定性。比如说我平时服务就只能支撑几万的qps,像淘宝京东那种秒杀,那时候服务突然打进来那服务就会直接被压死了。但是如果采用消息队列,这秒杀进来的所有的请求都不会直接打到具体服务上,都会先打到消息队列里,然后我后面的服务再慢慢消费。
劣势:
- 系统可用性降低:如何保证高可用?
- 系统复杂性提高:如何保证消息没有被重复消费?怎么处理消息丢失?怎么保证消息传递的顺序性?
- 一致性问题:如何保证消息数据的一致性?
MQ常见的问题
-
mq如何避免消息堆积问题。
消息堆积:生产者的生产速率远远大于消费者的消费速率,使消息大批量的堆积在消息队列。
解决方案:
- 提升消费者的消费速率(增加消费者集群)
- 消费者分批多线程去处理
- 限流,保证进入到消息队列的都是有用的消息
-
如何避免重复消费问题
**产生原因: **
- 生产者产生了两条一模一样的消息。
- 消费者一条消息消费了多遍
消息重试:消息重试一般发生于一个消费者发生了异常(网络波动或者系统假死),这个时候这个消费者就会通知生产者重新发送。就会带来重复消费的问题。
可以采用常用的幂等解决方案(分布式锁),全局id+业务场景保证唯一性。所有的重复提交问题,都可以用幂等性来解决。
为了保险起见,也可以在数据库上做好唯一索引。
-
如何保证消息不丢失
-
消息确认机制,生产者必须确认消息成功刷盘到硬盘中,才确认消息发送成功。
acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。这个参数对消息丢失的可能性有重要影响。该参数有如下选项。
-
如果 acks=0 ,生产者在成功写入消息之前不会等待任何来自服务器的响应。也就是说,如果当中出现了问题,导致服务器没有收到消息,那么生产者就无从得知,消息也就丢失了。不过,因为生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
-
如果 acks=1 ,只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应。如果消息无法到达Leader节点(比如Leader节点崩溃,新的Leader还没有被选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个没有收到消息的节点成为新Leader,消息还是会丢失。这个时候的吞吐量取决于使用的是同步发送还是异步发送。如果让发送客户端等待服务器的响应(通过调用 Future 对象的 get() 方法),显然会增加延迟(在网络上传输一个来回的延迟)。如果客户端使用回调,延迟问题就可以得到缓解,不过吞吐量还是会受发送中消息数量的限制(比如,生产者在收到服务器响应之前可以发送多少个消息)。
-
如果 acks=-1(或all),只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。这种模式是最安全的,它可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群仍然可以运行。不过,它的延迟比 acks=1 时更高,因为要等待不只一个服务器节点接收消息。
结合具体的业务场景来进行选择。
-
-
消息持久化机制,作为mq中间件,会把消息持久化到硬盘,因为内存里的数据断电就丢失了
-
消费者必须确认消息消费成功,否则进行重试,重试达到一定次数后,通知开发人员做好补偿措施。
-
关闭自动提交,当消费者消费的完成后,再手动提交,防止mq的自动提交,当消费者接收到消息后,mq以为消费者已经消费了,但这个时候消费者如果挂了,这条消息就没有被消费。
-
-
如何保证消费的顺序一致性
大多数的项目不需要保证顺序一致性,某些特殊场景必须保证顺序一致性,比如说,mq用于保证redis和mysql的数据一致性。
绑定同一个消费队列,消费的时候进行要注意如果使用了多线程处理,避免重新创建list,要在原来的list进行修改。
-
mq怎么用于保证redis和数据库的数据一致性
- 当执行update后,发送mq去通知消费者更新redis数据
优点:解耦,提高接口响应速度,有相应的补偿策略
缺点:延迟比较高
- 监听binlog日志,结合mq,去更新redis(canal实现)
优点:更加解耦
缺点:延迟更高
- 双删策略
-
消费者怎么知道mq里有消息了
两种方案:
-
mq主动通知(push)
当mq中有消息,就会通知消费者来进行消费。这种模型有一个致命伤,就是慢消费。
-
消费者轮询(pull)
消费者去轮询看看有没有自己要消费的消息。这种模型也有弊端就是消息延迟与忙等。
如果消费者的速度比发送者的速度慢很多,势必造成消息在mq的堆积。假设这些消息都是有用的无法丢弃的,消息就要一直在mq端保存。当然这还不是最致命的,最致命的是mq给消费者推送一堆无法处理的消息,消费者不是拒绝就是报错,然后来回踢皮球。
反观pull模式,消费者可以按需消费,不用担心自己处理不了的消息来骚扰自己,而mq堆积消息也会相对简单,无需记录每一个要发送消息的状态,只需要维护所有消息的队列和偏移量就可以了。所以消息量有限且到来的速度不均匀的情况,pull模式比较合适。
由于主动权在消费方,消费方无法准确地决定何时去拉取最新的消息。如果一次pull取到消息了还可以继续去pull,如果没有pull取到则需要等待一段时间重新pull。
但等待多久就很难判定了。当然也不是说延迟就没有解决方案了,业界较成熟的做法是从短时间开始(不会对mq有太大负担),然后指数级增长等待。比如开始等5ms,然后10ms,然后20ms,然后40ms……直到有消息到来,然后再回到5ms。
即使这样,依然存在延迟问题:假设40ms到80ms之间的50ms消息到来,消息就延迟了30ms,而且对于半个小时来一次的消息,这些开销就是白白浪费的。
在阿里的RocketMq里,有一种优化的做法-长轮询,来平衡推拉模型各自的缺点。基本思路是:消费者如果尝试拉取失败,不是直接返回,而是把连接挂在那里等待,服务端如果有新的消息到来,把连接复用起来,这也是不错的思路。但海量的长连接mq对系统的开销还是不容小觑的,还是要合理的评估时间间隔。
-
-
如果mq宕机后,生产者怎么处理。
生产者在向mq投递消息的时候,可以将要投递的消息记录下来(可以在数据库中插入一条数据,也可以输出相应的日志记录)后期可以编写定时任务,定期向mq发送之前发送不成功的消息。
-
mq的消费策略
**集群消费:**同一个消费者集群,只能消费一条消息,但是一条消息可以被多个消费者集群消费。
广播消费:通知集群中的所有节点都进行消费(涉及到数据分片处理的场景),对数据不敏感 的场景可以采用普通hash,对数据敏感的场景可以采用hash环。
使用MQ的条件
- 生产者不需要从消费者处获得反馈
- 容许短暂的不一致性
- MQ的解耦异步削峰大于负面影响
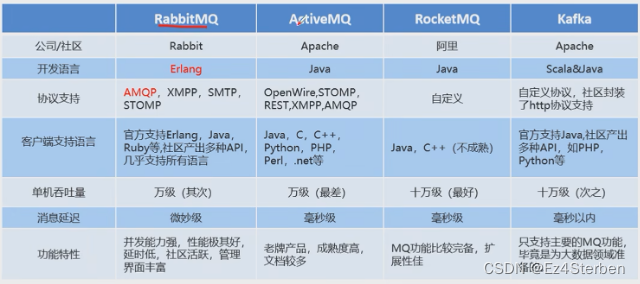
常见的MQ产品
- RabbitMQ
- RocketMQ
- ActiveMQ
- Kafka
- ZeroMQ
- MetaMQ
- Redis也可以