目标检测算法之YOLOv6 (1)全流程指南:环境安装、模型配置、训练及推理
- 本文向将介绍 YOLOv6 的整体框架,并提供详细的教程链接。
- 官方论文 ☞ YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
- v3.0版本论文更新 ☞ YOLOv6 v3.0: A Full-Scale Reloading 🔥
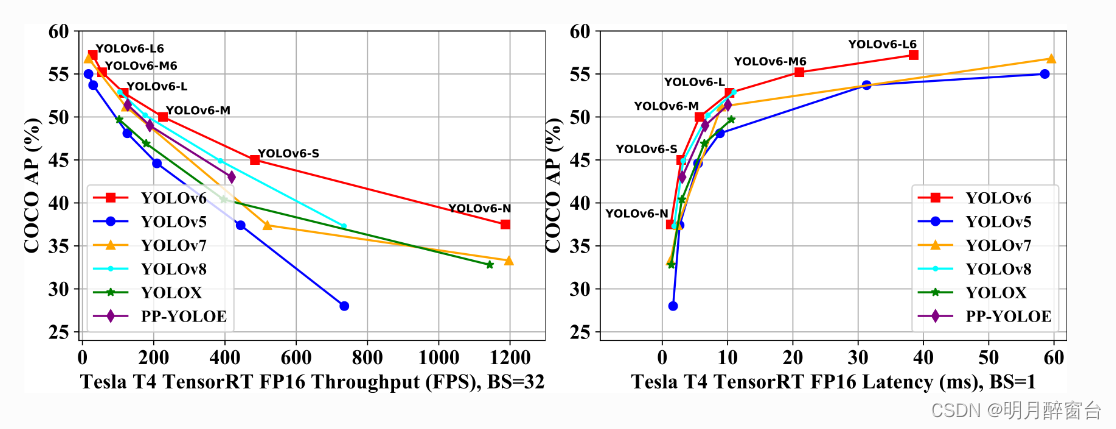
- 其2023年4月优化的最新性能如下图:
- YOLOv6 是一款面向工业应用研发的目标检测框架,致力于提供极致的检测精度和推理效率。其包括丰富的目标检测算法以及相关的组件模块,下面是整体代码框架的介绍:
├── configs #配置文件目录,用于指定网络结构,优化器,数据增强等超参
│ ├── experiment #存放非发版模型的实验配置
│ ├── repopt #存放repopt训练相关的配置
│ ├── base #存放基础版模型的配置(PTQ量化友好)
│ ├── *.py #常规模型的配置(RepVGG进阶版)
├── data #数据集路径配置文件
├── tools #启动训练、评估、推理、量化等任务
│ ├── train.py #训练启动脚本
│ ├── eval.py #评估启动脚本
│ └── infer.py #推理启动脚本
│ ├── qat #qat量化相关脚本
│ ├── partial_quantization #ptq量化相关脚本
|── yolov6 #检测算法核心部分,包含运行组件、网络定义、数据处理、标签分配及损失计算等核心模块
| ├── assigners #标签分配算法,包括ATSS和TAL分配算法及相关工具脚本
| ├── core #模型训练、评估和推理等组件的核心运行逻辑
| ├── data #数据预处理,包括数据加载,各种数据增强变换和数据格式转换等脚本
| ├── layers #定义卷积,RepVGG block,SPPF 等基础算子和模块
| ├── models #网络结构定义(包括 Backbone, Neck, Head)以及loss计算等脚本
| ├── solver #优化器构建组件
| └── utils #模型保存加载、指标计算,NMS后处理等工具脚本
├── deploy #模型部署目录
│ ├── ONNX #导出 ONNX 模型
│ ├── OpenVINO #导出 OpenVINO 模型
│ └── TensorRT #转换 TRT 模型以及验证可视化
├── docs #相关教程文档
│ ├── Test_speed.md #复现测速指标的相关命令教程
│ ├── Train_coco_data.md #复现 COCO 精度指标的命令
│ ├── Train_custom_data.md #训练自定义数据集的教程指引
│ ├── Tutorial of Quantization.md #量化相关的教程和指引
│ └── tutorial_voc.ipynb #训练 VOC 数据集的教程指引
1.环境安装
- YOLOv6 支持在 Linux,Windows 和 macOS 上运行。它需要 Python 3.8 以上 和 PyTorch 1.8 以上。
1.1 安装Pytorch
OSX系统:
pip install torch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0
-------------------------------------------------------------------------------------
Linux and Windows系统:
# CUDA 11.1
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
# CUDA 10.2
pip install torch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0
# CPU only
pip install torch==1.8.0+cpu torchvision==0.9.0+cpu torchaudio==0.8.0 -f https://download.pytorch.org/whl/torc
1.2 安装 YOLOv6
- git下载
git clone https://github.com/meituan/YOLOv6
cd YOLOv6
pip install -r requirements.txt
-
为了验证 YOLOv6 是否安装正确,我们提供了一些示例代码来执行模型推理。
-
步骤 1. 下载模型权重文件。
方式一:从官方 YOLOv6 Github 仓库中下载最新的模型权重;
方式二:使用 wget
下载(注意下载链接需要更新到最新的版本号,确认是最近发布的模型)
pip install wget
# 注意确认以下链接中的版本号是否为最新
wget https://github.com/meituan/YOLOv6/releases/download/0.3.0/yolov6n.pt
mkdir weights
mv yolov6n.pt weights/yolov6n.pt
- 步骤 2. 推理验证
python tools/infer.py --weights weights/yolov6n.pt --source data/images/
# 可选参数
# --device 0 *使用的计算资源,包括cuda, cpu等,默认为0
# --name exp *用于指定source图像推理结果可视化的保存文件夹
# --view-img *使用该参数表示在屏幕上显示检测结果,默认为False
# --conf_thres 0.4 *置信度阈值,默认为0.4
- 运行结束后,在 runs/inference/exp 文件夹中可以看到检测结果图像,图像中包含有网络预测的检测框。
支持输入类型包括:
- 单张图片, 支持 bmp, jpg, jpeg, png, tif, tiff, dng, webp, mpo。
- 文件目录,会遍历文件目录下所有图片文件,并输出对应结果。
- 单个视频,支持mp4, mov, avi, mkv。
2.配置文件学习
YOLOv6 采用模块化设计,用户可以通过配置文件的参数配置进行功能模块的切换和实验。 以 yolov6s_finetune.py 为例,我们将根据不同的功能模块分别介绍配置文件中的各个字段的定义及使用指南。
2.1 模型配置
- 我们使用model的相关字段来完成检测网络的模型结构定义,包括
backbone,neck,head,loss等类型的配置。
model = dict(
type='YOLOv6s', #网络类型
pretrained='./weights/yolov6s.pt', #指定COCO预训练模型权重的路径
depth_multiple=0.33, #控制网络结构深度的缩放因子
width_multiple=0.50, #控制网络结构宽度的缩放因子
backbone=dict(
type='EfficientRep', #主干网络的类别,目前可支持'EfficientRep', 'CSPBepBackbone','EfficientRep6','CSPBepBackbone_P6' 4种
num_repeats=[1, 6, 12, 18, 6], #主干网络每个stage中基础模块的重复个数
out_channels=[64, 128, 256, 512, 1024], #主干网络每个stage中输出的通道数
fuse_P2=True, #是否融合骨干网络P2层特征
cspsppf=True, #是否使用CSPSPPF模块以替换SPPF模块
),
neck=dict(
type='RepPANNeck', #检测器 Neck 的类别,目前可选用'RepPANNeck', 'CSPRepPANNeck','RepBiFPANNeck','CSPRepBiFPANNeck','RepBiFPANNeck6','CSPRepBiFPANNeck_P6' 6种
num_repeats=[12, 12, 12, 12], # Neck网络连接每个特征层基础模块的重复个数
out_channels=[256, 128, 128, 256, 256, 512],# Neck网络连接每个特征层的上采样/下采样模块通道数
),
head=dict(
type='EffiDeHead', #检测头类型,目前暂时仅支持此类型
in_channels=[128, 256, 512], #检测头每个特征层的输入通道数
num_layers=3, #检测头的特征层数量, P6模型此值为4
begin_indices=24, #检测头的起始层数
anchors=1, #每个预测特征图单位网格对应的anchor数
out_indices=[17, 20, 23], #检测头的输出索引号
anchors=3, #fuse_ab模式下,每个特征点设置3个anchors
anchors_init=[[10,13, 19,19, 33,23],
[30,61, 59,59, 59,119],
[116,90, 185,185, 373,326]],#fuse_ab模式下,anchors初始值
strides=[8, 16, 32], #检测头每个特征层的下采样步长
atss_warmup_epoch=0, #标签分配策略使用ATSS热身轮数,fuse_ab模式下设为0
iou_type='giou', #iou损失的类型,目前可支持 'giou','diou','ciou','siou' 4种
use_dfl=False, #是否使用distributed focal loss,若后续想继续蒸馏,需要设为True以保留DFL分支
reg_max=0, #若 use_dfl 为 False, 则 reg_max 设为 0;若 use_dfl 为 True, 则reg_max 设为 16
distill_weight={
'class': 1.0, #蒸馏训练分类loss的初始权重
'dfl': 1.0, #蒸馏训练回归loss的初始权重
},
)
)
2.2 优化相关配置
- 这里可以通过修改相关字段的值来完成训练时优化相关的配置。
solver = dict(
optim='SGD', #优化器类型,目前支持'SGD','Adam' 2种
lr_scheduler='Cosine', #学习率衰减策略,目前支持'Cosine','Constant' 2种
lr0=0.0032, #初始学习率
lrf=0.12, #最终学习率
momentum=0.843, #动量
weight_decay=0.00036, #权重衰减
warmup_epochs=2.0, #warmup轮数
warmup_momentum=0.5, #warmup动量
warmup_bias_lr=0.05 #warmup时偏置的初始学习率
)
数据增强超参配置
这里可以通过修改相关字段的值来修改训练时数据增强的策略。
data_aug = dict(
hsv_h=0.0138, #hsv中h通道随机增强
hsv_s=0.664, #hsv中s通道随机增强
hsv_v=0.464, #hsv中v通道随机增强
degrees=0.373, # 最大旋转角度
translate=0.245, #最大平移比例(0.5+translate)
scale=0.898, #随机尺度缩放(1+scale)
shear=0.602, #最大错切角度
flipud=0.00856, #上下翻转概率
fliplr=0.5, #左右翻转概率
mosaic=1.0, # Mosaic 数据增强概率
mixup=0.243, # Mixup 数据增强概率
)
2.3 评估参数配置
-
除了在运行评估脚本时通过命令参数指定评估方式之外,我们还支持通过配置文件对相关参数进行配置。 其中,img_size,pading and scale coord 和 metric 相关的字段可支持 string 类型或 list 类型。
-
如果是 string 类型(示例一),表示指定模型评估时的配置(包括训练时评估和训练完成后单独评估);如果是 list 类型(示例二),需要包含两个值,前者表示训练过程中模型评估的参数配置,后者表示训练完成后单独进行模型评估时的配置。
示例一:
eval_params = dict(
img_size=640, #评估时图像尺寸大小
conf_thres=0.03, #评估时置信度阈值
iou_thres=0.65, #评估时IoU阈值
#pading and scale coord #灰边填充以及坐标转换相关处理,能提升模型精度指标
test_load_size=634, #评估时加载图片后对图片进行resize到此像素大小
letterbox_return_int=True, #letterbox填充时偏移量返回int值
force_no_pad=True, #矩形推理时不对图像进行额外填充(以32像素为步长进行灰边填充)
not_infer_on_rect=True, #评估时是否使用矩形推理还是方形推理,True表示方形推理(如640*640),False表示矩形推理(如640*384)可加速推理过程
scale_exact=True, #letterbox图片坐标转换原图时长宽缩放分开处理,坐标更精确
#metric
verbose=False, #是否需要输出每个类别的指标
do_coco_metric=True, #是否采用 Pycocotool 进行指标评估
do_pr_metric=True, #是否需要输出 Precision/ Recall/ F1等指标
plot_curve=False, #是否需要画 PR曲线,若为True,可以在评估保存目录`runs/val/xxx`下找到对应的曲线,需要在 do_pr_metric=True 前提下使用
plot_confusion_matrix=False #是否需要输出混淆矩阵,若为True,可以在评估保存目录`runs/val/xxx`下找到对应的混淆矩阵可视化结果,需要在 do_pr_metric=True 前提下使用
)
示例二:
- list类型参数说明:前者表示训练过程中模型评估的参数配置,后者表示单独进行模型评估时的配置。
- 每个字段的参数含义及使用请参考示例一的说明。
eval_params = dict(
img_size=[None, 640], #前者 None表示采用默认值,默认为640.
conf_thres=0.03,
iou_thres=0.65,
#pading and scale coord
test_load_size=[None, 638], #前者 None 表示采用默认值,默认为640.
letterbox_return_int=[False, True],
force_no_pad=[False, True],
not_infer_on_rect=[False, True],
scale_exact=[False, True],
#metric
verbose=False,
do_coco_metric=[True, True],
do_pr_metric=[False, True],
plot_curve=[False, False],
plot_confusion_matrix=[False, False]
)
3.模型训练、评估和推理流程
-
开始模型训练之前,请确认已经正确安装并配置环境,如果没有,请参考环境安装里面的指引安装必要的库。
-
根据您的数据及应用场景,参考选型指导选择合适的模型。
3.1 准备数据集
- 下载数据
如需要训练 COCO 数据集, 您可以在 COCO官方网站 下载图片数据, 然后在这里下载转换成 YOLO 格式的标签文件;
如需要训练 VOC 数据集,同样需要先下载对应的图片数据和标签文件,可从下面的链接下载。
| dataset | url | size | images |
|---|---|---|---|
| VOC2007 trainval | download zip | 446MB | 5012 |
| VOC2007 test | download zip | 438MB | 4953 |
| VOC2012 trainval | download zip | 1.95GB | 17126 |
3.2 YOLO 格式转换
-
如果标签文件不是 YOLO 格式,需要先转换成 YOLO 格式;
-
YOLO 格式定义:
一张图片对应一个标签文件,且标注信息的格式如下所示:
# 类别id 中心点x坐标 中心点y坐标 目标框宽度 目标框高度
0 0.300926 0.617063 0.601852 0.765873
1 0.575 0.319531 0.4 0.551562
-
每一行代表一个目标框信息;类别 id 从 0 开始;
-
目标框的坐标需要进行归一化,如果标注信息为原始像素值,中心点x坐标 和 目标框宽度 需要除以 图像宽度 做归一化,中心点y坐标 和 目标框高度 需要除以 图像高度 做归一化。
-
对于如 VOC 的 xml 格式标注文件,我们提供了转换成 YOLO 格式的脚本。
python yolov6/data/voc2yolo.py --voc_path your_path/to/VOCdevkit
此外,我们还提供了可视化脚本,可用于检查数据集的标注信息是否正确。
python yolov6/data/vis_dataset.py --img_dir your_path/to/VOCdevkit/images/train --label_dir your_path/to/VOCde
3.3 组织文件夹
- 确保您的数据集按照下面这种格式来组织:
# COCO 数据集
├── coco
│ ├── annotations
│ │ ├── instances_train2017.json
│ │ └── instances_val2017.json
│ ├── images
│ │ ├── train2017
│ │ └── val2017
│ ├── labels
│ │ ├── train2017
│ │ ├── val2017
# VOC 数据集
# 训练集组成:VOC2007 和 VOC2012 train+val(16551)
# 验证集组成:VOC2007 test(4952)
VOCdevkit
├── images
├── labels
├── voc_07_12 #转换成YOLO格式的数据集文件夹
│ ├── images
│ │ ├── train
│ │ └── val
│ └── labels
│ ├── train
│ └── val
├── VOC2007
│ ├── Annotations
│ ├── ImageSets
│ ├── JPEGImages
│ ├── SegmentationClass
│ └── SegmentationObject
└── VOC2012
├── Annotations
├── ImageSets
├── JPEGImages
├── SegmentationClass
└── SegmentationObject
3.4 准备配置文件
- 我们提供了一些针对 COCO 数据集、VOC数据集及自定义数据集示例配置文件。 (当前仅支持该格式的数据集读取,后续会继续支持更多的数据集组织方式。)
1) 需要将数据集路径调整为您机器上所在的路径,建议用绝对路径;train/val 路径必填,test 路径选填。
2) 如果是 非COCO 数据集,需要将 is_coco 设置为 False,代码中会根据此标志参数判断是否需要将数据集标签格式转换为COCO格式,以便于模型评估采用 pycocotools 时调用。
- 选择网络配置文件
1) 如果是训练 COCO 数据集或与 COCO 差异较大的数据集,建议选用 yolov6n(/s/m/l).py 配置文件;
2) 如果是训练 自定义数据集,建议选用 yolov6n(/s/m/l)_finetune.py 配置文件;
关于配置文件的参数定义及解析,请参考[配置文件学习](配置文件学习.md)
3.5 模型训练
-
这里以训练 YOLOv6-S 模型为例:
-
单卡训练
# P5 models
python tools/train.py --batch 32 --conf configs/yolov6s_finetune.py --data data/dataset.yaml --fuse_ab --device 0
# P6 models
python tools/train.py --batch 32 --conf configs/yolov6s6_finetune.py --data data/dataset.yaml --img 1280 --device 0
- 多卡训练(推荐使用 DDP 模式)
# P5 models
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --batch 256 --conf configs/yolov6s_finetune.py --data data/dataset.yaml --fuse_ab --device 0,1,2,3,4,5,6,7
# P6 models
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --batch 128 --conf configs/yolov6s6_finetune.py --data data/dataset.yaml --img 1280 --device 0,1,2,3,4,5,6,7
- 关键参数说明:(可在train.py里查看所有参数定义)
- fuse_ab: 增加anchor-based预测分支并开启锚点辅助训练模式 (P6模型暂不支持此功能)
- conf: 定义网络和超参的配置文件,如果是训练自定义数据集,使用后缀带finetune的配置文件,并在配置文件pretrained参数指定预训练模型权重的路径;
- batch: 训练数据批大小,如果显卡内存不足,可适当调低该值;
- check-images 和 check-labels: 用于初始化数据集时检查图片和标签文件格式是否正确,并生成缓存文件,一般首次训练或由于数据集问题导致训练曾经中断而再次训练时需要添加这两个参数;
- write_trainbatch_tb: 用于在tensorboard可视化训练数据集的预测结果,对训练速度稍有影响,根据个人需要添加;
- distill: 开启logit蒸馏训练,搭配teacher_model_path参数共同使用,通过teacher_model_path参数指定教师网络的模型权重路径;需要先完成教师网络的训练后使用;
- distill_feat:开启feat蒸馏训练,仅在量化感知训练时与distill参数同时使用,常规自蒸馏训练默认不开启;
- resume: 用于上一次训练被中断后需要恢复训练使用;
- 如果需要在 COCO 数据集上 复现 我们的精度指标,请参考以下配置
-------------------------YOLOv6-S/M/L 🔽-------------------------------
# Step 1: Training a base model
# Be sure to open use_dfl mode in config file (use_dfl=True, reg_max=16)
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 256 \
--conf configs/yolov6s.py \ # yolov6m/yolov6l
--data data/coco.yaml \
--epoch 300 \
--fuse_ab \
--device 0,1,2,3,4,5,6,7 \
--name yolov6s_coco # yolov6m_coco/yolov6l_coco
# Step 2: Self-distillation training
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 256 \ # 128 for distillation of yolov6l
--conf configs/yolov6s.py \ # yolov6m/yolov6l
--data data/coco.yaml \
--epoch 300 \
--device 0,1,2,3,4,5,6,7 \
--distill \
--teacher_model_path runs/train/yolov6s_coco/weights/best_ckpt.pt \
--name yolov6s_coco # yolov6m_coco/yolov6l_coco
3.6 恢复训练
- 如果您的训练进程中断了,您可以这样恢复先前的训练进程。
# 单卡训练
python tools/train.py --resume
# 多卡训练
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --resume
上面的命令将自动在 YOLOv6 当前训练保存目录中找到最近保存的模型,然后恢复训练。
您也可以通过 --resume 参数指定要恢复的模型路径,这种方式会从您提供的模型路径恢复训练。
- 请将 /path/to/your/checkpoint/path 替换为您要恢复训练的模型权重路径
--resume /path/to/your/checkpoint/path
3.7 训练过程可视化
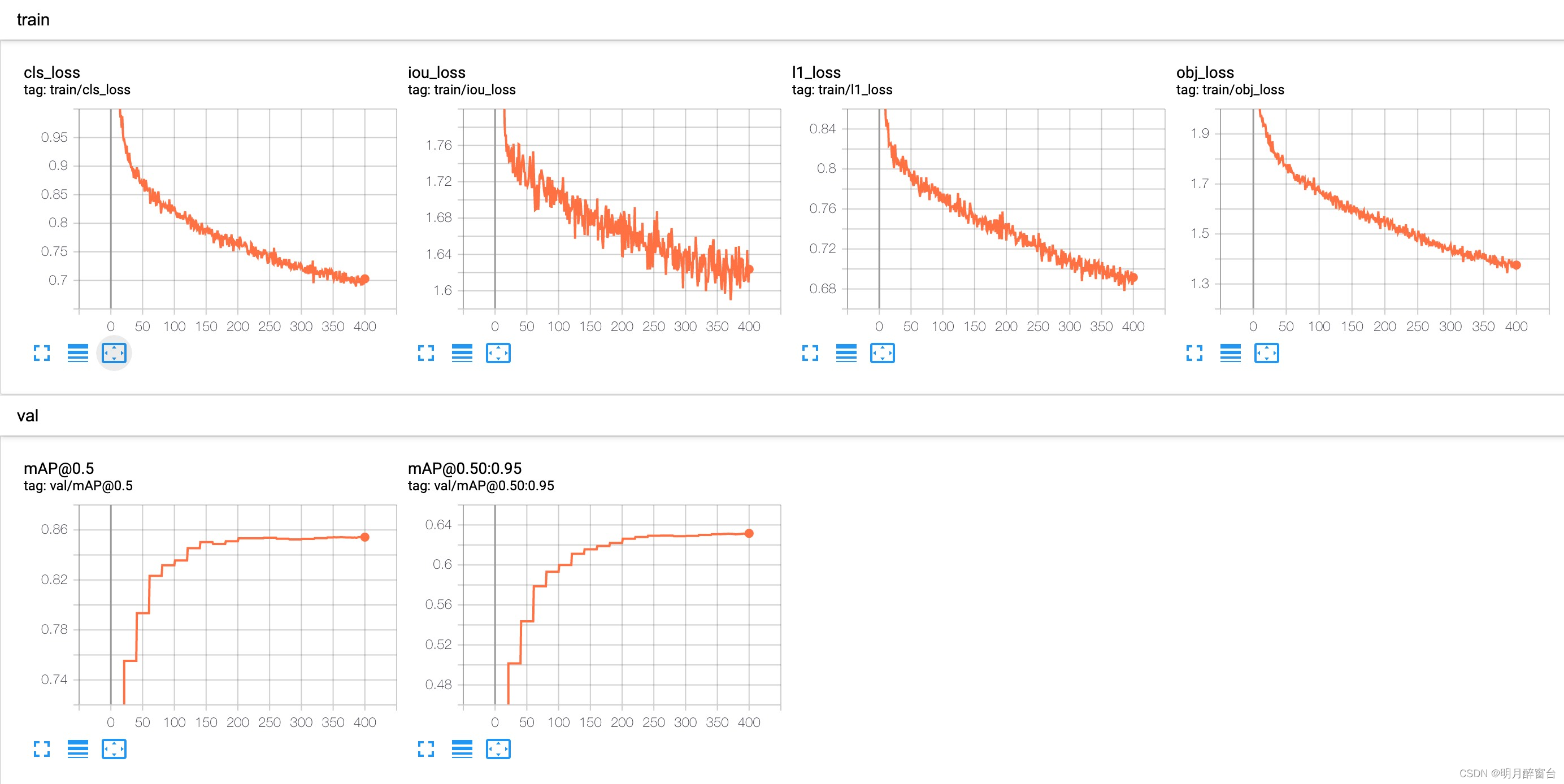
- 使用 tensorboard 可视化 训练数据/ 验证数据 的预测结果 以及 loss/mAP 曲线,命令如下:
tensorboard --logdir=your_path/to/log
打开对应的网页之后,可以看到 loss/mAP 曲线;
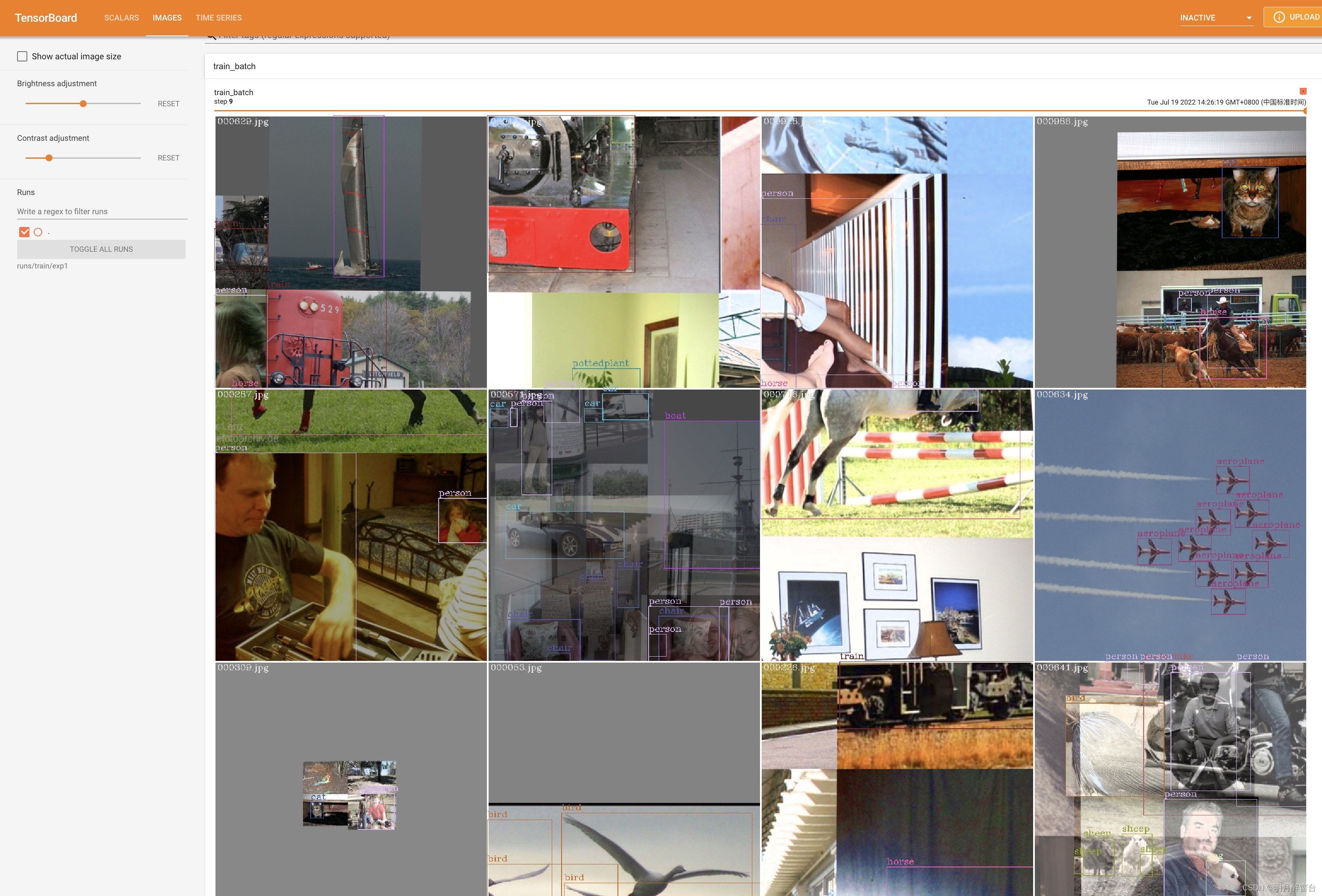
- 如果需要可视化训练数据的预测结果,需要在训练启动命令中添加参数
--write_trainbatch_tb
3.8 模型评估
- 模型在验证集/测试集上进行精度/速度评估:
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6s.pt --task val/test/speed
关键参数说明:(可在eval.py里查看所有参数定义)
- task: 通过task参数指定评估任务,val表示在验证集上评估精度,test表示在测试集上评估精度,speed表示在验证集上评估速度;
- do_coco_metric: 设置 True / False 来打开或关闭 pycocotools 的评估,一般用此方式评估的结果较准确,但速度稍慢,默认打开;
- do_pr_metric: 设置 True / False 来显示或不显示精度和召回的指标,默认关闭,可根据个人需要开启;
- reproduce_640_eval: 可复现COCO上的精度指标所使用的配置,具体可在[eval_640_repro.py](https://github.com/meituan/YOLOv6/blob/main/configs/experiment/yolov6n_with_eval_params.py)此配置文件中查看相关的参数配置;
- verbose: 如果要打印每一个类别的精度信息,可设置为 True;
- config-file: 选用参数,用于指定包含所有评估参数的配置文件,具体可见[yolov6n_with_eval_params.py](https://github.com/meituan/YOLOv6/blob/main/configs/experiment/yolov6n_with_eval_params.py) 示例文件;
在 COCO val2017 数据集上复现我们的结果(输入分辨率 640x640 或 1280x1280)
# P5 models
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6s.pt --task val --reproduce_640_eval
# P6 models
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6s6.pt --task val --reproduce_640_eval --img 12
3.9 模型推理
- 步骤 0. 从 YOLOv6官方github 下载一个训练好的模型权重文件,或选择您自己训练的模型;
步骤 1. 通过 tools/infer.py文件进行推理。
# P5 models
python tools/infer.py --weights yolov6s.pt --source img.jpg / imgdir / video.mp4
# P6 models
python tools/infer.py --weights yolov6s6.pt --img-size 1280 1280 --source img.jpg / imgdir / video.mp4
关键参数说明:(可在eval.py里查看所有参数定义)
- source: 用于指定需要推理的图片或视频,支持批量图片推理,可指定图片路径,数据集所在文件夹,视频路径等;
- img-size: 用于指定推理的图像尺寸(高,宽),如(1280,1280),默认为(640,640);
- yaml: 用于指定数据集配置文件,主要是获取配置文件中的class_names以便于可视化时加上类别信息;
- conf: 设置推理采用的分数阈值,默认为0.4;
- iou: 设置推理采用的iou阈值,默认为0.45;
- save-img: 保存检测框可视化后的图片,默认打开;
- save-txt: 保存包括检测框的信息的txt文件,默认关闭;
- view-img: 展示检测框可视化后的图片,默认关闭;
- classes: 指定可视化的类别,如无指定,默认所有类别均被可视化;
- hide-labels: 可视化目标框时隐藏类别信息,默认关闭;
- hide-conf: 可视化目标框时隐藏预测分数信息,默认关闭;
- name: 指定保存可视化结果的文件夹,会自动创建,默认为‘exp’。
运行后,在runs/inference/exp目录下能看到对应的可视化结果。