接上篇《25、urllib获取快餐网站店铺数据》
上一篇我们讲解了如何使用urllib的post请求抓取某某快餐网站店铺数据。本篇我们来讲解urllib的异常处理机制。
一、异常处理的重要性
在编程过程中,无论是与网络交互还是执行其他操作,都存在各种意外和错误可能。这些错误可能是由于网络连接问题、服务器故障、无效的URL或其他不可预见的情况引起的。为了确保代码的稳定性和可靠性,我们需要进行适当的异常处理。
异常处理是一种编程技术,用于捕获和处理在程序执行过程中出现的错误或异常情况。它允许我们优雅地处理错误,而不会导致程序崩溃或产生不可预测的行为。通过合理的异常处理,我们可以提高程序的健壮性,并提供更好的用户体验: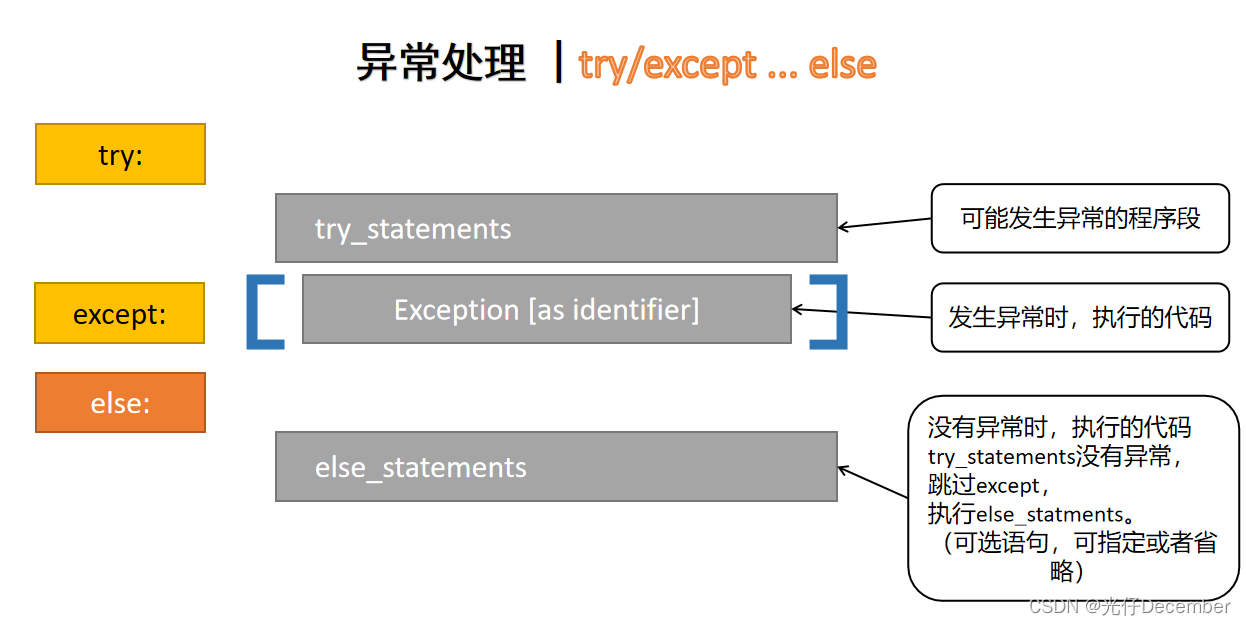
当涉及到使用urllib库进行网络请求时,异常处理显得尤为重要。这是因为在网络通信过程中,许多不可控的因素可能导致请求失败或出现错误。例如,网络连接可能超时、服务器可能返回错误的状态码或无效的响应数据等:
如果我们不进行异常处理,这些错误将会直接抛出,并可能导致程序崩溃。此外,没有适当的异常处理也会使我们难以调试和追踪错误,增加维护和排除故障的难度。
通过使用urllib库中的异常处理机制,如URLError和HTTPError类,它们包含在urllib.error中。常见的异常情况包括:网络连接问题、超时、404等错误,我们可以捕获并处理这些网络请求中可能出现的异常情况。这些异常类提供了有关错误原因、错误代码和错误信息等重要信息,帮助我们更好地理解和处理问题。使用异常模块处理时,我们需要使用try-except语句块,来捕获和处理异常情况。
因此,在使用urllib进行网络请求时,合理的异常处理是至关重要的。它不仅可以保护我们的程序免受不可预见的错误影响,还可以提高程序的稳定性和可靠性,让我们能够更好地应对各种网络环境和情况。
二、URLError类
1、URLError类的作用和定义
URLError类是urllib库中的一个异常类,用于表示在进行网络请求时发生的错误。它是所有与网络请求相关的异常类的基类,包含了多种可能导致请求失败的错误情况。
在urllib库中使用URLError类可以捕获和处理与网络连接有关的异常,例如无法建立连接、网络超时等。它提供了一种统一的方式来处理这些错误,并能够提供错误的详细信息,以便进一步调试和处理问题。
URLError类的定义包含在urllib.error模块中。当进行网络请求时,如果发生任何与网络连接相关的错误,都会抛出一个URLError异常。这个异常包含了具体的错误原因,可以通过异常对象的属性来获取。
以下是URLError类的一些常见属性:
●reason:返回一个字符串,描述了引发URLError异常的具体原因。
●errno:返回一个整数,代表与错误相关的系统错误码(如果有)。该属性的值可以与标准的errno模块中定义的常量进行比较。
●filename:返回一个字符串,对应于引起错误的资源的URL或文件名。
通过捕获和处理URLError异常,我们可以根据具体的错误情况采取相应的补救措施,例如重试请求、更换URL或提供用户友好的错误提示等。这样可以增加程序的健壮性,并提高用户体验。
2、常见URLError类异常示例
以下是一些常见的URLError类触发条件和相应的示例代码:
(1)无法解析主机名:
触发条件:当尝试连接的主机名无法解析为有效的IP地址时,会引发URLError异常。
示例代码:
import urllib.request
try:
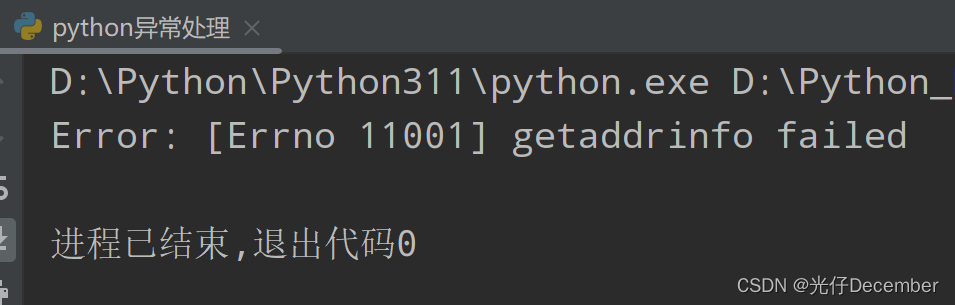
response = urllib.request.urlopen('http://invalidhostname')
# 这里的请求将失败,因为无法解析主机名
print(response.read())
except urllib.error.URLError as e:
print("Error: ", e.reason)效果:
(2)网络连接超时
触发条件:当网络连接超时时,无法建立与服务器的连接时,会引发URLError异常。
示例代码:
import urllib.request
import socket
try:
# 设置超时时间为2秒
timeout = 2
socket.setdefaulttimeout(timeout)
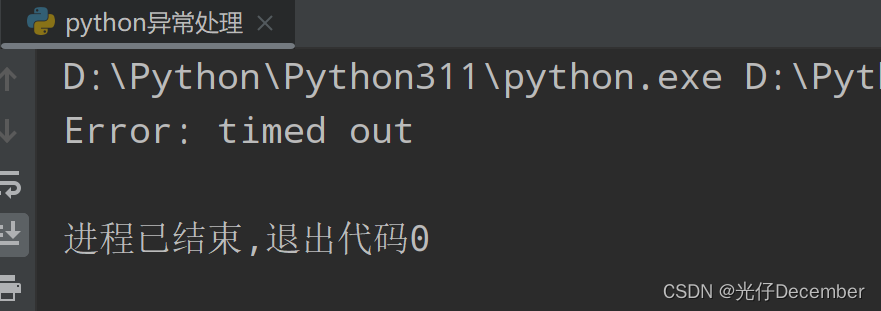
response = urllib.request.urlopen('http://www.sss.com')
# 这里的请求将失败,因为连接超时
print(response.read())
except urllib.error.URLError as e:
print("Error: ", e.reason)效果:
(3)资源未找到
触发条件:提供的URL获取的资源不存在报404错误时,会引发URLError异常。
示例代码:
import urllib.request
try:
response = urllib.request.urlopen('http://www.baidu.com/404')
# 这里的请求将失败,因为请求报404没有找到该资源
print(response.read())
except urllib.error.URLError as e:
print("Error:", e.reason)效果: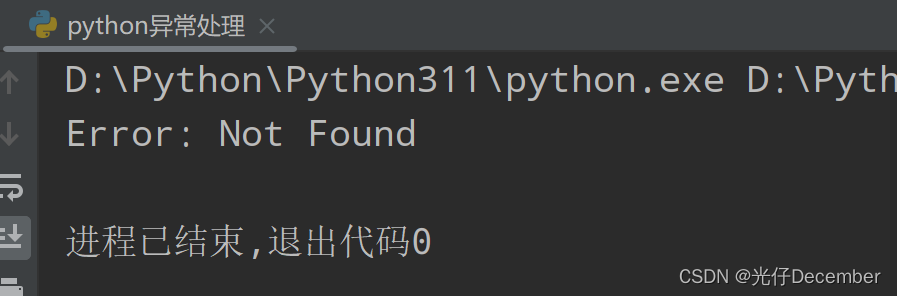
注意:以上示例代码仅用于演示URLError类的触发条件。在实际代码中,为了更好地处理异常情况,可能需要结合其他异常类和错误码进行判断和处理。另外,为了提高可读性和可维护性,还可以根据具体需求将异常处理逻辑封装成函数或类。
三、HTTPError类
1、HTTPError类的作用和定义
HTTPError类是urllib库中的一个异常类,用于表示在进行HTTP请求时发生的错误。它是URLError类的子类,专门用于处理与HTTP协议相关的异常情况。
当使用urllib库发送HTTP请求时,如果服务器返回了错误的状态码(如404 Not Found、500 Internal Server Error等),则会抛出一个HTTPError异常。该异常提供了有关错误响应的详细信息,包括状态码、错误原因和错误消息等。
HTTPError类的定义同样包含在urllib.error模块中,它扩展了URLError类,为处理HTTP请求错误提供了更详细的信息。
以下是HTTPError类的一些常见属性:
●code:返回一个整数,表示HTTP状态码。
●reason:返回一个字符串,描述了引发HTTPError异常的具体原因。
●headers:返回一个类似字典的对象,包含了服务器返回的响应头部信息。
通过捕获和处理HTTPError异常,我们可以根据具体的错误状态码和响应内容来采取相应的补救措施。例如,可以重新发送请求、解析错误响应或提供用户友好的错误提示。
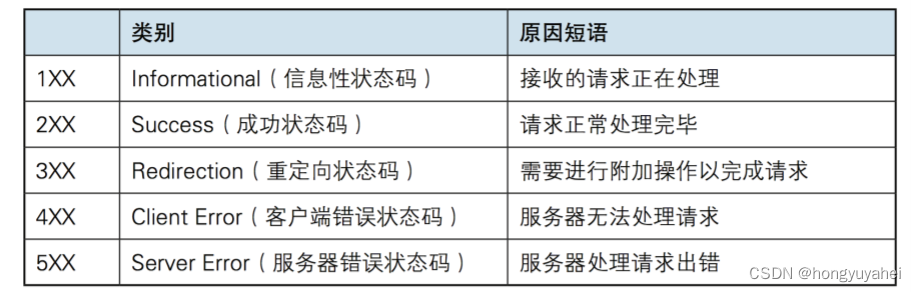
2、HTTP状态码及其对应的常见错误情况
要运用HTTPError处理异常,就需要先了解HTTP请求常见的状态码以及含义。
HTTP状态码是在进行HTTP通信时,服务器返回给客户端的一个三位数的数字代码。它提供了关于请求处理结果的信息,用于指示请求成功与否以及出现的错误类型。以下是一些常见的HTTP状态码及其对应的常见错误情况:
(1)2xx 成功:
●200 OK:表示请求成功,服务器成功处理了请求并返回了所需的内容。
●201 Created:表示请求成功,并且服务器创建了新的资源。
●204 No Content:表示请求成功,但服务器没有返回任何内容。
(2)3xx 重定向:
●301 Moved Permanently:表示请求的资源已永久移动到新位置。
●302 Found:表示请求的资源暂时移动到其他位置。
●304 Not Modified:表示资源未被修改,客户端可以使用缓存的版本。
(3)4xx 客户端错误:
●400 Bad Request:表示请求不正确或无法被服务器理解。
●401 Unauthorized:表示需要身份验证,但客户端未提供有效的身份凭证。
●403 Forbidden:表示服务器拒绝了请求,可能是因为权限不足。
●404 Not Found:请求的资源在服务器上未找到。
(4)5xx 服务器错误:
●500 Internal Server Error:表示服务器内部错误,无法完成请求。
●502 Bad Gateway:表示作为代理或网关的服务器从上游服务器收到无效响应。
●503 Service Unavailable:表示服务器当前无法处理请求,通常由过载或维护引起。
注意:以上仅是一些常见的HTTP状态码及其对应的错误情况,实际上还有许多其他状态码和错误情况。了解HTTP状态码可以帮助我们更好地理解服务器返回的响应,并根据不同的状态码采取适当的处理措施,以提高程序的鲁棒性和用户体验。
3、HTTPError类实际应用示例
下面是一个HTTPError类的实际应用示例,包括如何获取错误码和错误信息:
import urllib.error
try:
response = urllib.request.urlopen('http://www.baidu.com/nonexistent')
# 这里的请求将返回404 Not Found错误
print(response.read())
except urllib.error.HTTPError as e:
# 获取错误码
error_code = e.code
print("Error code:", error_code)
# 获取错误信息
error_message = e.reason
print("Error message:", error_message)效果: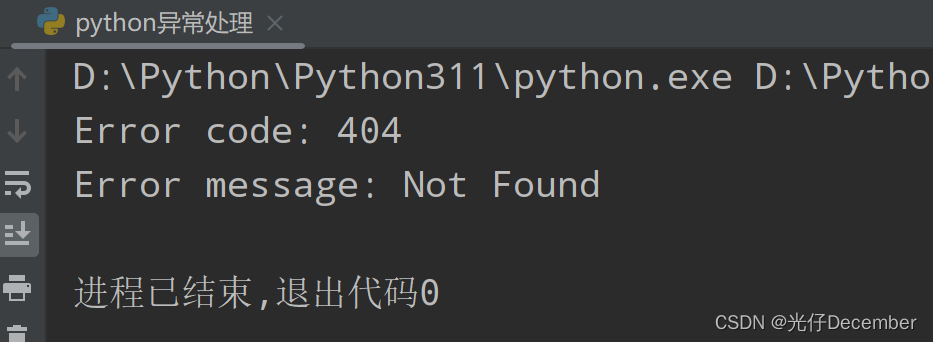
在上述示例中,我们尝试访问一个不存在的URL。由于该URL对应的资源不存在,服务器将返回404 Not Found错误。
在捕获HTTPError异常后,我们可以通过e.code属性来获取错误码,即404。然后,通过e.reason属性来获取错误信息,即Not Found。
根据具体的需求,我们可以根据错误码和错误信息来采取相应的处理措施。例如,将错误信息显示给用户、记录日志、重试请求或执行其他操作。
请注意,在实际应用中,除了HTTPError异常外,还可能遇到其他类型的异常,比如URLError。因此,为了更好地处理网络请求中可能出现的各种异常情况,建议使用适当的异常处理机制,并根据具体的错误类型进行处理。
四、URLError和HTTPError类的区别和联系
URLError和HTTPError类都是urllib库中的异常类,用于处理网络请求过程中的错误情况。它们之间有以下区别和联系:
1、区别:
●URLError类:用于表示在进行URL请求时发生的错误,包括网络连接问题、主机名无法解析等。它是HTTPError类的父类,也可以用于捕获其他非HTTP相关的错误。
●HTTPError类:是URLError类的子类,专门用于表示与HTTP协议相关的错误。它用于表示服务器返回的HTTP响应状态码错误,如404 Not Found、500 Internal Server Error等。
2、联系:
●继承关系:HTTPError类继承自URLError类,因此HTTPError对象实际上是URLError对象,并包含了HTTP相关的额外属性,如状态码、错误原因等。
●异常处理:可以使用try-except语句来捕获这两个异常类的实例,以便对其进行适当的处理和错误恢复操作。
●错误信息:无论是URLError还是HTTPError,都提供了获取错误信息的属性,如reason。这些属性可用于打印错误信息或进一步处理错误。
总结起来,URLError和HTTPError类都是urllib库中用于处理网络请求错误的异常类。URLError类用于表示URL请求相关的错误,而HTTPError类则专注于表示与HTTP协议相关的错误。通过捕获和处理这些异常,我们可以根据具体情况采取适当的措施来处理网络请求中的错误。
五、合理进行异常处理的重要性
在使用urllib进行网络请求时,合理进行异常处理是非常重要的。以下是强调合理进行异常处理的几个重要原因:
1、鲁棒性:网络请求过程中可能发生各种异常情况,如网络连接问题、服务器错误、URL拼写错误等。合理进行异常处理可以增加程序的鲁棒性,使其能够更好地应对异常情况,并避免程序崩溃或无法正常运行。
2、用户体验:当出现异常时,用户通常希望得到清晰的提示信息,而不是看到一堆错误堆栈信息。通过捕获和处理异常,可以提供友好的错误提示,告知用户出现了什么问题以及如何解决或重新尝试请求。
3、调试和日志记录:合理进行异常处理可以帮助开发者更好地调试代码和追踪错误。记录异常日志可以提供有关异常的详细信息,包括错误码、错误原因、请求参数等,从而快速定位和解决问题。
4、安全性:某些异常情况可能会涉及到安全性问题,如网络攻击、恶意链接等。通过异常处理,我们可以对此类异常进行适当的处理和防范措施,从而保护系统和用户的安全。
在实际应用中,建议使用try-except语句来捕获可能引发的异常,并根据具体情况进行适当的处理。对于不同类型的异常,可以采取不同的补救措施,如重试请求、切换备用服务器、提供错误提示等。
总之,合理进行异常处理是使用urllib进行网络请求时的关键。它能够提高程序的鲁棒性、用户体验、安全性,并帮助开发者更好地调试和追踪错误。通过良好的异常处理,我们可以构建更可靠和稳定的网络应用。
以上就是urllib异常处理技术的所有内容,下一篇博文我们将学习如何处理urllib的Handler处理器的相关知识。
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://blog.csdn.net/acmman/article/details/131498495