分类目录:《自然语言处理从入门到应用》总目录
相关文章:
· 预训练模型总览:从宏观视角了解预训练模型
· 预训练模型总览:词嵌入的两大范式
· 预训练模型总览:两大任务类型
· 预训练模型总览:预训练模型的拓展
· 预训练模型总览:迁移学习与微调
· 预训练模型总览:预训练模型存在的问题
从大量无标注数据中进行预训练使许多自然语言处理任务获得显著的性能提升。总的来看,预训练模型的优势包括:
- 在庞大的无标注数据上进行预训练可以获取更通用的语言表示,并有利于下游任务
- 为模型提供了一个更好的初始化参数,在目标任务上具备更好的泛化性能、并加速收敛
- 是一种有效的正则化手段,避免在小数据集上过拟合,而一个随机初始化的深层模型容易对小数据集过拟合
下图就是各种预训练模型的思维导图,其分别按照词嵌入(Word Embedding)方式分为静态词向量(Static Word Embedding)和动态词向量(Dynamic Word Embedding)方式分类、按照监督学习和自监督学习方式进行分类、按照拓展能力等分类方式展现:
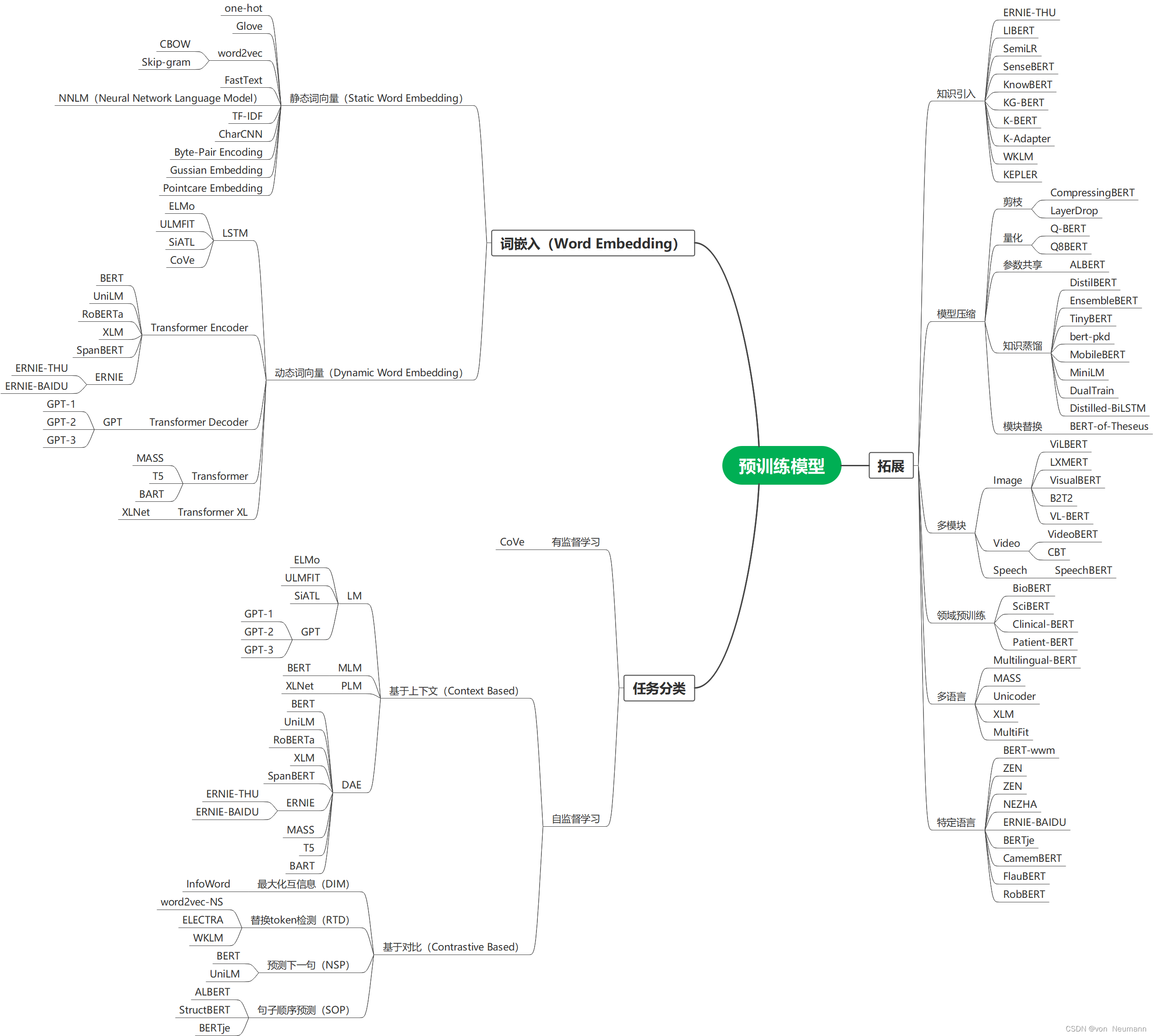
思维导图可编辑源文件下载地址:https://download.csdn.net/download/hy592070616/87954682
预训练模型从大型语料库中获取通用语言知识,如何有效地将其知识适应下游任务是一个关键问题。迁移学习的方式主要有归纳迁移(顺序迁移学习、多任务学习)、领域自适应(转导迁移)、跨语言学习等。自然语言处理中预训练模型的迁移方式是顺序迁移学习。
- 选择合适的预训练任务:语言模型是预训练模型是最为流行的预训练任务,但不同预训练任务有其自身的偏置,并且对不同的任务会产生不同的效果。例如,NSP任务可以使诸如问答(QA)和自然语言推论(NLI)之类的下游任务受益。
- 选择合适的模型架构:例如BERT采用的MLM策略和Transformer-Encoder结构,导致其不适合直接处理生成任务。
- 选择合适的数据:下游任务的数据应该近似于预训练模型的预训练任务,现在已有有很多现成的预训练模型可以方便地用于各种特定领域或特定语言的下游任务。
- 选择合适的Layers进行迁移:主要包括Embedding迁移、Top Layer迁移和All Layer迁移。如word2vec和Glove可采用Embedding迁移,BERT可采用Top Layer迁移,Elmo可采用All Layer迁移。
- 特征集成与微调:对于特征集成预训练参数是冻结的,而对于微调不是冻结的。特征集成方式却需要特定任务的体系结构,微调方法通常比特征提取方法更为通用和方便。
通过更好的微调策略进一步激发预训练模型性能:
- 两阶段微调策略:如第一阶段对中间任务或语料进行微调,第二阶段再对目标任务微调。第一阶段通常可根据特定任务的数据继续进行微调预训练。
- 多任务微调:MTDNN在多任务学习框架下对BERT进行了微调,这表明多任务学习和预训练是互补的技术。
- 采取额外的适配器:微调的主要缺点是其参数效率低,每个下游任务都有自己的微调参数。因此,更好的解决方案是在固定原始参数的同时,将一些可微调的适配器注入预训练模型。
- 逐层阶段:逐渐冻结而不是同时对所有层进行微调,也是一种有效的微调策略。
参考文献:
[1] QIU XIPENG, SUN TIANXIANG, XU YIGE, et al. Pre-trained models for natural language processing: A survey[J]. 中国科学:技术科学(英文版),2020.