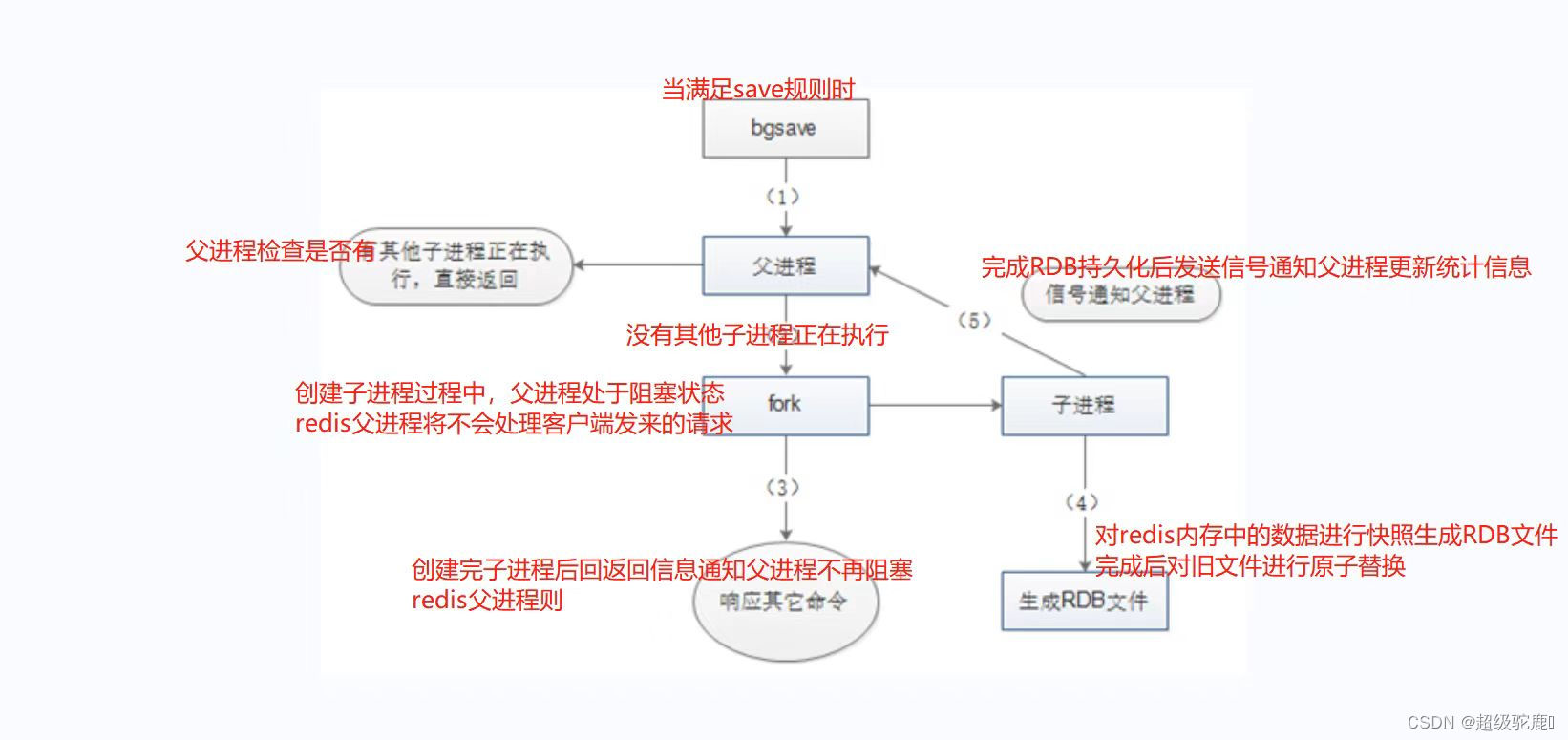
大表扫描
特殊case说明:当任务存在扫event_log表时需注意,若对event_log表进行了过滤,且过滤比很高,如下图的case,input为74T,但shuffle write仅为3.5G,那么建议提高单partition的读取数据量,将参数set spark.sql.files.maxPartitionBytes=536870912提高10倍至5368709120;

小型任务
目前测试:在不手动添加任何参数、平均时长在30min以内、单个shuffle 量在500G以下的任务可以使用该模版,但实际任务情况还需跟踪观察
开启AQE后,spark.sql.shuffle.partitio参数失效(spark默认200,任务从头到尾的所有shuffle都是这个并行度,无法自由操控)
AQE:实现原理是在每个stage完成后再启动一个子Job来计算shuffle中间结果量,依此来进行调节task个数,让作业根据每次shuffle的数据量自行调节并行度。
spark.sql.adaptive.minNumPostShufflePartitions 控制所有阶段的reduce个数,reduce个数区间最小值,为了防止分区数过小
spark.sql.adaptive.maxNumPostShufflePartitions reduce个数区间最大值,同时也是shuffle分区数的初始值
spark.sql.adaptive.shuffle.targetPostShuffleInputSize 动态调整 reduce 个数的 partition 大小依据。如设置 64MB,则 reduce 阶段每个 task 最少处理 64MB 的数据。默认值为 64MB。
--基础资源
set spark.driver.memory=15g;
set spark.driver.cores=3;
set spark.driver.memoryOverhead=4096;
set spark.executor.memory=5G;
set spark.executor.memoryOverhead=1024;
set spark.executor.cores=2;
set spark.vcore.boost.ratio=2;
--动态executor申请
set spark.dynamicAllocation.minExecutors=10;
set spark.dynamicAllocation.maxExecutors=300;
--ae,shuffle partition并行度
set spark.sql.adaptive.minNumPostShufflePartitions=10;
set spark.sql.adaptive.maxNumPostShufflePartitions=1000;
--268435456;
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize=536870912;
--开启parquet切分
set spark.sql.parquet.adaptiveFileSplit=true;
--初始task调节,合并小文件
set spark.sql.files.maxPartitionBytes=536870912;
中型任务
目前测试:在不手动添加任何参数、平均时长在90min以内、单个shuffle 量在2T以下的任务可以使用该模版,但实际任务情况还需跟踪观察。
spark.executor.memoryOverhead 每个executor的堆外内存大小,堆外内存主要用于数据IO,对于报堆外OOM的任务要适当调大,单位Mb,与之配合要调大executor JVM参数,例如:set spark.executor.memoryOverhead=3072
set spark.executor.extraJavaOptions=-XX:MaxDirectMemorySize=2560m
--基础资源
set spark.driver.memory=25g;
set spark.driver.cores=4;
set spark.driver.memoryOverhead=5120;
set spark.executor.memory=10G;
set spark.executor.memoryOverhead=4096;
set spark.executor.cores=3;
set spark.vcore.boost.ratio=1;
--动态executor申请
set spark.dynamicAllocation.minExecutors=10;
set spark.dynamicAllocation.maxExecutors=600;
--AQE
set spark.sql.adaptive.minNumPostShufflePartitions=10;
set spark.sql.adaptive.maxNumPostShufflePartitions=1000;
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize= 536870912;
--开启parquet切分,初始task调节,合并小文件
set spark.sql.parquet.adaptiveFileSplit=true;
set spark.sql.files.maxPartitionBytes=536870912;
--推测
set spark.speculation.multiplier=2.5;
set spark.speculation.quantile=0.8;
--shuffle 落地hdfs
set spark.shuffle.hdfs.enabled=true;
set spark.shuffle.io.maxRetries=1;
set spark.shuffle.io.retryWait=0s;
大型任务
目前测试:在不手动添加任何参数、平均时长在120min以内、单个shuffle 量在10T以下的任务可以使用该模版,但实际任务情况还需跟踪观察。
--基础资源
set spark.driver.memory=25g;
set spark.driver.cores=4;
set spark.driver.memoryOverhead=5120;
set spark.executor.memory=15G;
set spark.executor.memoryOverhead=3072;
set spark.executor.cores=3;
set spark.vcore.boost.ratio=1;
--动态executor申请
set spark.dynamicAllocation.minExecutors=10;
set spark.dynamicAllocation.maxExecutors=900;
--ae
set spark.sql.adaptive.minNumPostShufflePartitions=10;
set spark.sql.adaptive.maxNumPostShufflePartitions=3000;
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize= 536870912;
--shuffle 落地hdfs
set spark.shuffle.hdfs.enabled=true;
set spark.shuffle.io.maxRetries=1;
set spark.shuffle.io.retryWait=0s;
--开启parquet切分,合并小文件
set spark.sql.parquet.adaptiveFileSplit=true;
set spark.sql.files.maxPartitionBytes=536870912;
--推测
set spark.speculation.multiplier=2.5;
set spark.speculation.quantile=0.9;
超大型任务
目前测试:在不手动添加任何参数、平均时长大于120min、单个shuffle 量在10T以上的任务可以使用该模版,但实际任务情况还需跟踪观察。
--基础资源
set spark.driver.memory=30g;
set spark.driver.cores=4;
set spark.driver.memoryOverhead=5120;
set spark.executor.memory=20G;
set spark.executor.memoryOverhead= 5120;
set spark.executor.cores=5;
set spark.vcore.boost.ratio=1;
--动态executor申请
set spark.dynamicAllocation.minExecutors=10;
set spark.dynamicAllocation.maxExecutors=1500;
--ae
set spark.sql.adaptive.minNumPostShufflePartitions=10;
set spark.sql.adaptive.maxNumPostShufflePartitions=7000;
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize= 536870912;
--开启parquet切分,合并小文件
set spark.sql.parquet.adaptiveFileSplit=true;
set spark.sql.files.maxPartitionBytes=536870912;
-- shuffle 落地 hdfs,shuffle文件上传hdfs
set spark.shuffle.hdfs.enabled=true;
set spark.shuffle.io.maxRetries=1;
set spark.shuffle.io.retryWait=0s;
--推测
set spark.speculation.multiplier=2.5;
set spark.speculation.quantile=0.9;
其他常用参数
--ae hash join
set spark.sql.adaptive.hashJoin.enabled=true;
set spark.sql.adaptiveHashJoinThreshold=52428800;
--输出文件合并 byBytes,该功能会生成两个stage,
--第一个stage shuffle的数据量来预估最后生成到hdfs上的文件数据量大小,
--并通过预估的文件数据量大小计算第二个stage的并行度,即最后生成的文件个数。
--该功能只能控制生成的文件大小尽量接近spark.merge.files.byBytes.fileBytes,且有一定的性能损耗,需根据实测情况选择使用。
-- 最终文件数量:(totalBytes / fileBytes / compressionRatio).toInt + 1
set spark.merge.files.byBytes.enabled=true;
set spark.merge.files.byBytes.repartitionNumber=100; --第一个stage的并行读
set spark.merge.files.byBytes.fileBytes=134217728; -- 预期的文件大小
set spark.merge.files.byBytes.compressionRatio=3; -- 压缩比,shuffle文件和最后生成的文件格式和压缩格式都不相同,因此通过该参数调节
--输出文件合并 该功能会在原来job的最后一个stage后面增加1个stage来控制最后生成的文件数量,
--对于动态分区,每个分区生成spark.merge.files.number个文件。
spark.merge.files.enabled=true
spark.merge.files.number=512
--skew_join 解析绕过tqs
set tqs.analysis.skip.hint=true;
--初始task上限
set spark.sql.files.openCostInBytes=4194304;
set spark.datasource.splits.max=20000;
--broadcast时间
set spark.sql.broadcastTimeout = 3600;
--(防止get json报错)
set spark.sql.mergeGetMapValue.enabled=true;
--ae 倾斜处理 HandlingSkewedJoin OptimizeSkewedJoin
set spark.sql.adaptive.allowBroadcastExchange.enabled=true;
set spark.sql.adaptive.hashJoin.enabled=false;
set spark.sql.adaptive.skewedPartitionFactor=3;
set spark.sql.adaptive.skewedPartitionMaxSplits=20;
set spark.sql.adaptive.skewedJoin.enabled=true;
set spark.sql.adaptive.skewedJoinWithAgg.enabled=true;
set spark.sql.adaptive.multipleSkewedJoin.enabled=true;
set spark.shuffle.highlyCompressedMapStatusThreshold=20000;
--并发读文件
set spark.sql.concurrentFileScan.enabled=true;
--filter按比例读取文件
set spark.sql.files.tableSizeFactor={table_name}:{filter 比例};
set spark.sql.files.tableSizeFactor=dm_content.tcs_task_dict:10;
--AM failed 时长
set spark.yarn.am.waitTime=200s;
--shuffle service 超时设置
set spark.shuffle.registration.timeout=12000;
set spark.shuffle.registration.maxAttempts=5;
--parquet index 特性生效,in 条件的个数
set spark.sql.parquet.pushdown.inFilterThreshold=30;
--设置engine
set tqs.query.engine.type=sparkcli;
--hive metastore 超时
spark.hadoop.hive.metastore.client.socket.timeout=600
--manta备用
spark.sql.adaptive.maxNumPostShufflePartitions 5000
spark.executor.memoryOverhead 8000
spark.sql.adaptive.shuffle.targetPostShuffleInputSize 536870912