目录
1. 聚合模型的局限性
2.数据模型的选择建议
2.1 Aggregate数据模型选择
2.2 Unique数据模型选择
2.3 Duplicate数据模型选择
3. 列定义建议
进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容!
1. 聚合模型的局限性
以上Aggregate数据模型和Unique数据模型是聚合模型,Duplicate数据模型不是聚合模型,聚合模型存在一些局限性,这里说的局限性主要体现在select count(*) from table 操作效率和语意正确性两方面,下面我们针对 Aggregate 模型,来介绍下聚合模型的局限性。
在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,在Doris内部任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们举例说明。
假设表结构如下:
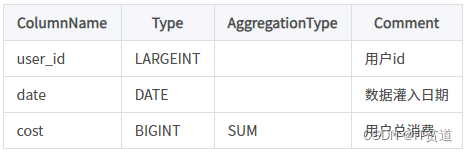
建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.test
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期",
`cost` BIGINT SUM COMMENT "用户总消费"
)
AGGREGATE KEY(`user_id`, `date`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);向表中分别插入两批次数据,第一批次SQL如下:
insert into example_db.test values
(10001,"2017-11-20",50),
(10002,"2017-11-21",39);第二批次SQL如下:
insert into example_db.test values
(10001,"2017-11-20",1),
(10001,"2017-11-21",5),
(10003,"2017-11-22",22);可以看到“10001,2017-11-20”这条数据虽然分在了两个批次中,但是由于设置了Aggregate Key 所以是相同数据,进行了聚合。两批次数据插入后,test表中数据如下:

另外,在聚合列(Value)上,执行与聚合类型不一致的聚合类查询时,要注意语意。比如我们在如上示例中执行如下查询:
mysql> select min(cost) from test;
+-------------+
| min(`cost`) |
+-------------+
| 5 |
+-------------+
1 row in set (0.03 sec)以上结果得到的是5,而不是1,归根结底就是底层数据进行了合并,是一致性保证的体现。这种一致性的保证,在某些查询中,会极大的降低查询效率。例如,在“select count(*) from table”这种操作中,这种一致性保证就会大幅降低查询效率,原因如下:
在其他数据库中,这类查询都会很快的返回结果,因为在实现上,我们可以通过如“导入时对行进行计数,保存 count 的统计信息”,或者在查询时“仅扫描某一列数据,获得 count 值”的方式,只需很小的开销,即可获得查询结果。但是在 Doris 的聚合模型中,这种查询的开销非常大。
以上案例中,我们执行“select count(*) from test;”正确结果为4,为了得到正确的结果,我们必须同时读取 user_id 和 date 这两列的数据,再加上查询时聚合,才能返回4 这个正确的结果。也就是说,在 count() 查询中,Doris 必须扫描所有的 AGGREGATE KEY 列(这里就是 user_id 和 date),并且聚合后,才能得到语意正确的结果,当聚合列非常多时,count() 查询需要扫描大量的数据,效率低下。
因此,当业务上有频繁的 count(*) 查询时,我们建议用户通过增加一个值恒为 1 的,聚合类型为 SUM 的列来模拟 count。如刚才的例子中的表结构,我们修改如下:
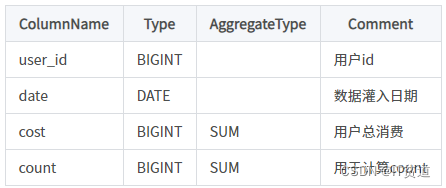
增加一个 count 列,并且导入数据中,该列值恒为 1。则 select count(*) from table; 的结果等价于 select sum(count) from table;。而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入 AGGREGATE KEY 列都相同的行。否则,select sum(count) from table; 只能表述原始导入的行数,而不是 select count(*) from table; 的语义。
建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.test1
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期",
`cost` BIGINT SUM COMMENT "用户总消费",
`count` BIGINT SUM COMMENT "用于计算count"
)
AGGREGATE KEY(`user_id`, `date`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);插入如下数据:
insert into test1 values
(10001,"2017-11-20",50,1),
(10002,"2017-11-21",39,1),
(10001,"2017-11-21",5,1),
(10003,"2017-11-22",22,1);执行sql语句对比:
# select count(*) from test1; 等价 select sum(count) from test1(效率高);
mysql> select count(*) from test1;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.04 sec)
mysql> select count(*) from test1;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.03 sec)此外,聚合模型的局限性注意以下几点:
- Unique模型的写时合并没有聚合模型的局限性(效率低下局限),因为写时合并原理是写入数据时已经将数据合并并会对过时数据进行标记删除,在数据查询时不需进行任何数据聚合,在测试环境中,count(*) 查询在Unique模型的写时合并实现上的性能,相比聚合模型有10倍以上的提升。
- Duplicate 模型没有聚合模型的这个局限性。因为该模型不涉及聚合语意,在做 count(*) 查询时,任意选择一列查询,即可得到语意正确的结果。
- Duplicate、Aggregate、Unique 模型,都会在建表指定 key 列,然而实际上是有所区别的:对于 Duplicate 模型,表的key列,可以认为只是 “排序列”,并非起到唯一标识的作用。而 Aggregate、Unique 模型这种聚合类型的表,key 列是兼顾 “排序列” 和 “唯一标识列”,是真正意义上的“ key 列”。
2.数据模型的选择建议
Doris中数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。如果在建表时没有指定数据模型,doris会根据创建列是否有聚合字段来决定使用什么模型,没有聚合字段默认是Duplicate数据存储模型,根据前缀索引长度决定选择那些列当做key列;如果有聚合key,默认为Aggregate数据存储模型,聚合列之前的列为key列。
2.1 Aggregate数据模型选择
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
2.2 Unique数据模型选择
Unique模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用ROLLUP等预聚合带来的查询优势。
对于聚合查询有较高性能需求的用户,推荐使用自1.2版本加入的写时合并实现。
Unique 模型仅支持整行更新,如果用户既需要唯一主键约束,又需要更新部分列(例如将多张源表导入到一张 doris 表的情形),则可以考虑使用 Aggregate 模型,同时将非主键列的聚合类型设置为 REPLACE_IF_NOT_NULL。具体的用法可以参考语法手册。
2.3 Duplicate数据模型选择
Duplicate 这种数据模型适用于既没有聚合需求,又没有主键唯一性约束的原始数据的存储,适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
3. 列定义建议
关于Doris表的类型,可以通过在 mysql-client 中执行 HELP CREATE TABLE; 查看。在定义Doris表中列类型时有如下建议:
- AGGREGATE KEY 数据模型Key 列必须在所有 Value 列之前。
- 尽量选择整型类型。因为整型类型的计算和查找效率远高于字符串。
- 对于不同长度的整型类型的选择原则,遵循够用即可。
- 对于 VARCHAR 和 STRING 类型的长度,遵循够用即可。
- 表中一行数据所有列总的字节数不能超过100KB。如果数据一行非常大,建议拆分数据进行多表存储。