导读
在智源大会的生成模型论坛上,斯坦福大学助理教授吴佳俊带来了精彩的演讲 “通过自然监督编码理解视觉世界”(Understanding the Visual World Through Naturally Supervised Code)。此次演讲从二维图像拓展到三维世界,从人类和自然的先验知识中汲取灵感并应用至生成神经网络。

吴佳俊
斯坦福大学计算机科学系助理教授,隶属于斯坦福人工智能实验室(SAIL)和斯坦福视觉与学习实验室(SVL)。他的研究方向是机器感知、推理和与物理世界的交互,从人类认知中汲取灵感。在加入斯坦福之前,吴佳俊曾在Google Research纽约分部担任访问教职研究员,与Noah Snavely合作。他在MIT获得博士学位,导师为Bill Freeman和Josh Tenenbaum,并在清华大学获得学士学位,师从Zhuowen Tu教授。
我们利用自然界中存在的丰富的结构、符号和程序,是为了在视觉世界中更好地感知,更好地理解。因此,有很多丰富的视觉效果,或者场景,你会意识到这不仅仅是像素,尽管这些模型总是以像素为基础,但它们实际上是比像素更丰富的结构。我们是否有可能利用像素之外的某种结构信息,用于智能场景理解和编辑。

这是一个视频,我们首先可以在给定建筑的情况下进行交互式分割,可以在3D中计算一个消失点。但用户希望通过另一个互动,如果想让它更高,建筑会是什么样子?用户可以通过拖动操作,使建筑更宽并使建筑更高。

但在实践中并没有那么简单,因为操作者必须真正了解多个抽象级别的场景。在最底层,必须理解场景有纹理。这些建筑是三维的,每个立面都有其表面法线,它面向一个特定的方向。因此,如果想让建筑更高,那么建筑的面应该仍然面向同一个方向。另一个重要方面就是重复,地板也在重复,窗户也应该不断重复。
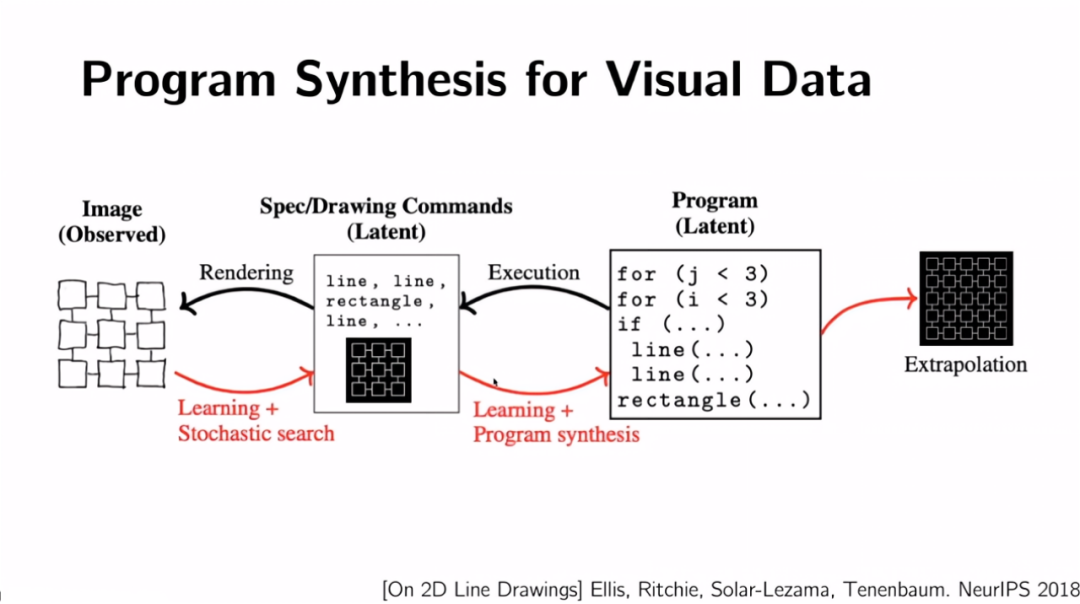
我们受到了早期工作的启发。从一个非常简单的图像开始,首先使用学习和随机搜索的组合来识别场景中的基本元素,在这些情况下,基本元素只有线条和矩形。现在让我们矢量化它,把高维空间变成一个低维空间。可以使用基于学习的方法在低维空间中寻找解释这些结构的编码。一旦有了这个编码,就可以完成一些小任务,比如图像外推。
如果在这种模式上继续推断,你可能已经注意到了一个明显的限制:世界不是完全由线条和矩形组成的。如果我们想扩展到自然图像,比如假如你有一碗牛奶加一些麦片,我们会意识到这个场景显然有一些结构。排列起来的麦片是同一类型的物体,就像同一个物种,同一个类别,它们只是同一物体类别的不同实例。
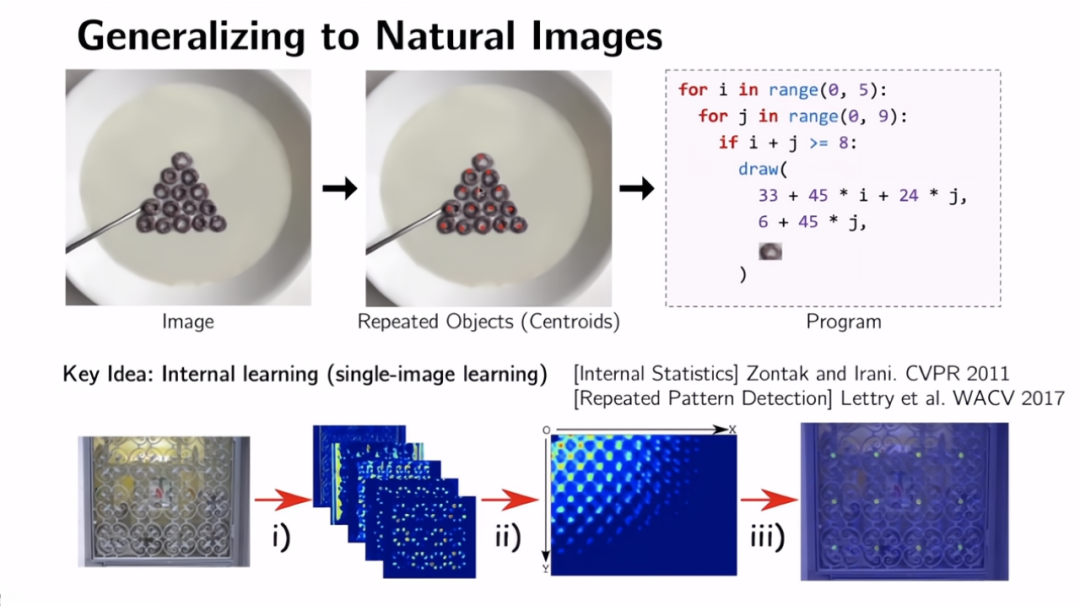
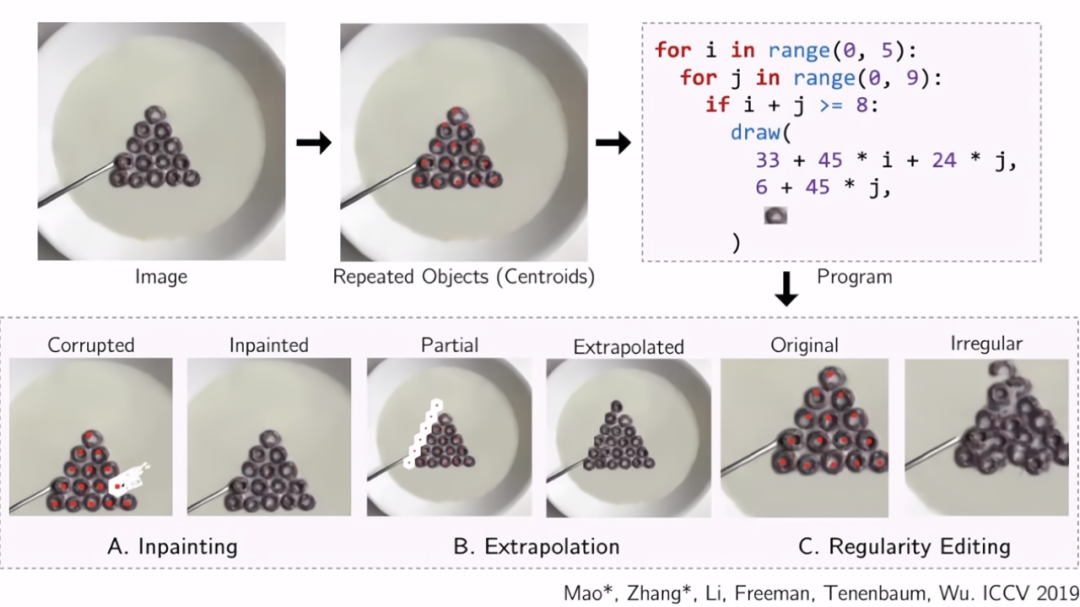
我们的算法基于这种想法,这使得它可以在没有事先训练的情况下进行训练。然后从单张测试图片上,就能识别出这些重复物体的中心。
我们可以把这看作是把一张自然图像矢量化了。当试图在一个低维的空间中表示了这幅图像。那在这里,如何参数化表示图像中的基本元素呢?实际上可以用一个新的网络来参数化表示它,这就用到了生成神经网络。例如在图像补全的过程中,结构化的编码告诉了我们如何找到图像中相关部分作为参考。而具体如何使用这些参考补丁来填补这个缺失的区域,就可以使用生成神经网络。神经网络将所有这些参考补丁巧妙地混合在一起,输出的图像看起来逼真,也直观,确实符合我们的直觉。此外,自然界中没有完美的图像,我们的编码表示会告诉你图像中基本元素和它们应该在的位置之间的轻微偏差。你可以放大这些不规则性,这对工业生产中的缺陷检测可能非常有用。
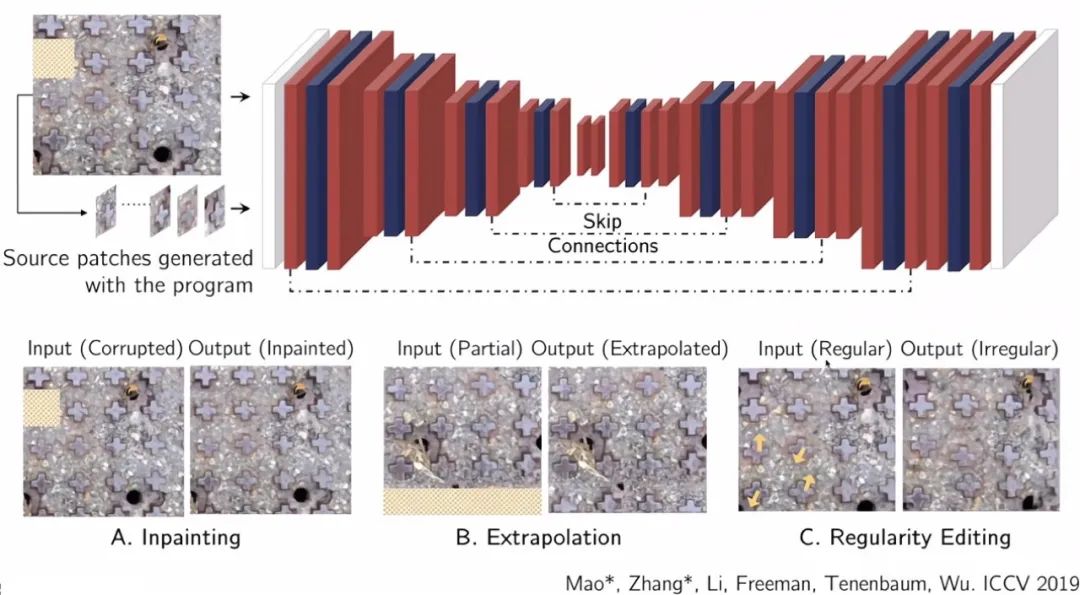
回到这个牛奶和麦片的例子。可以找到这些物体的中心,可以做图像补全,把丢失的麦片放回去。可以做图像外推,添加另一列麦片,可以做有规律的重复,也可以放大不规则的部分。
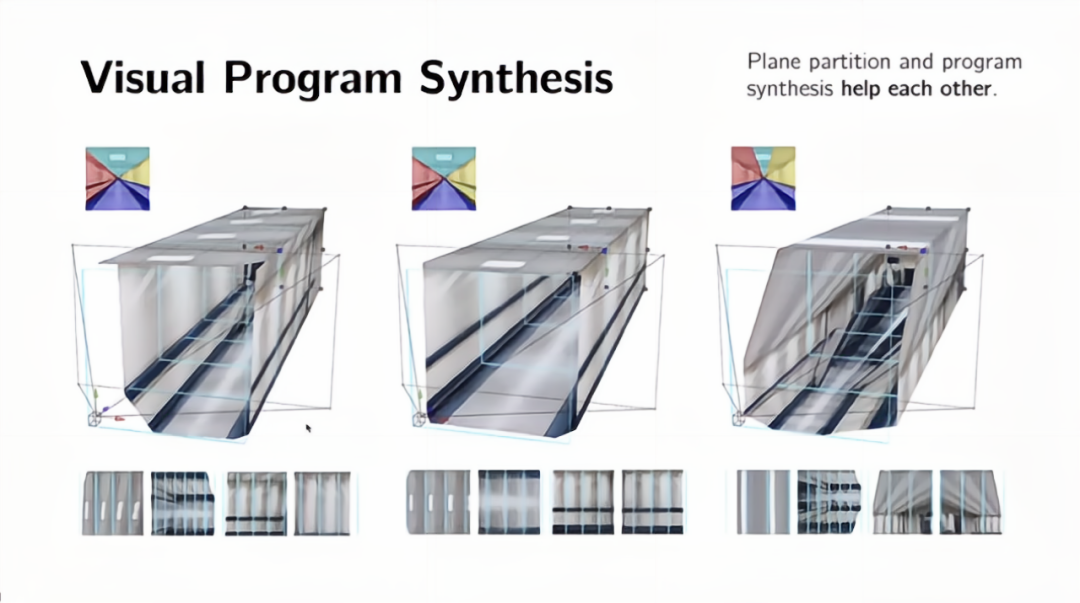
我们目前考虑的自然图片都只包含一个平面。显然,自然图片并非全部如此,例如,走廊并不是所有东西都在一个平面上:有天花板,有地板,有两面墙。现在的问题是,我们是否有可能将这种结构表示从单个平面推广到多个平面?

迄今为止,我们试图以这种自底向上的方式,从原始像素开始,试图识别某种自底向上的低层次视觉元素,然后一直到高层次的结构化程序编码。但这样的方式有其局限性。例如,在这张图像中,对低层次的视觉元素(包含消失点和二维线框)的估计很困难,这样会让我们对平面的可能划分产生很多不同的解释。特别是它们都满足视觉元素(消失点和线框)的约束。作为人类,我们有很多先验知识,但机器的情况并非如此,尤其是如果机器只从单张图像中进行推断的话。
所以可以看到,当我们从越来越复杂的画面中观察,这些线索变得越来越有限。由于存在更多的不确定性,假设空间更大。那么我们该如何解决这个问题呢?我们必须再次思考,为什么结构会首先存在,为什么这些物体或平面是规则的,为什么会存在这种对称性?为什么会出现这种重复?从根本上说,这是因为我们有这种人类偏好,作为人类,我们明确但有时非常隐式地引入了我们的偏好。

如上图所示,对于这个特定的走廊,可能是因为我们喜欢这种规律性,所以喜欢建造这种结构。我们具备这种先验知识,整个构造必须对称,行必须以固定的间隔重复。正是由于这种基本的人类偏好,结构才得以存在。这意味着,如果能够很好地识别或解决这个低层次的问题,那么高层次的问题也会变得更容易解决。所以这不仅仅是一个自底向上的视觉感知问题。自顶向下的程序编码的推断问题和自底向上的感知问题之间存在着互相作用。
我们已经讨论了视觉数据的结构化编码,从草图到自然图像,然后从一个平面到多个平面。我们可以把目前的结果看作是在2.5维图象上的。那下一步我们想转向三维物体。三维物体的形状通常具有抽象和程序化的结构。这又是因为,当人类试图制造这些物品时,只是希望它们是规律的,重复的,务实的,稳定的,想让它们便宜、高效。
这些想法,暗示了所有这些形状,它们必须具有这种结构。从某种意义上说,我们试图使用学习方法来从形状中推断出它们的程序化表示。在计算机图形学中,有很多使用过程式模型来处理形状的工作。受它们的启发,我们正在使用神经网络进行推理。我们同时使用神经网络作为程序执行器,这样就可以进行大部分自我监督的训练。
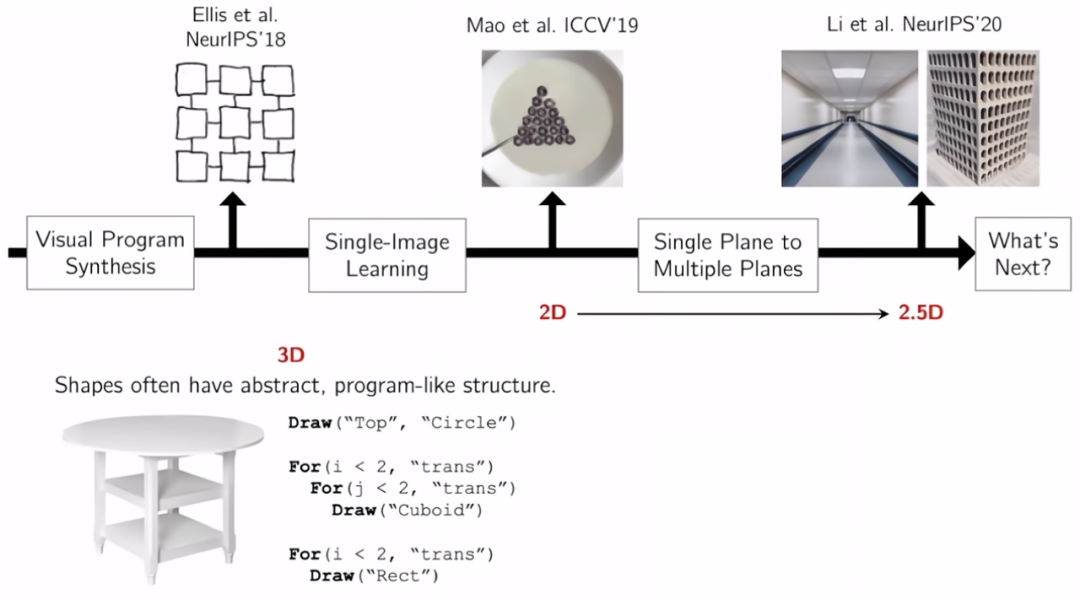
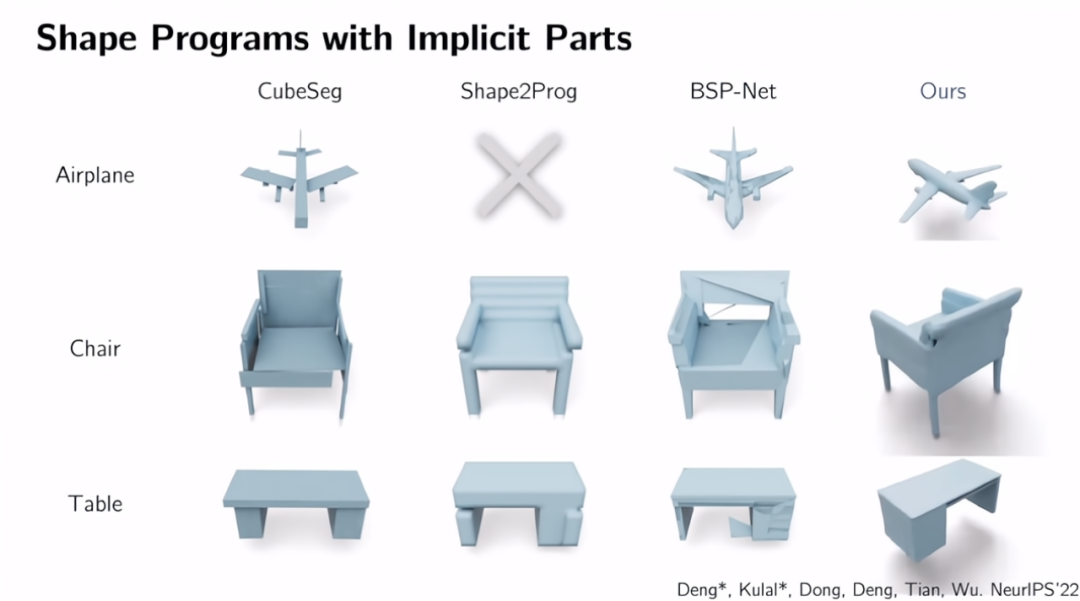
我们早期的工作假设了三维形状的基本元素是简单的几何形状,如圆柱体和长方体。然而,就像二维图像一样,三维世界也不仅仅是由圆柱体和长方体组成的。而复杂的几何结构不是简单的几何图元所能捕捉到的。最近在去年的NeurIPS会议上,我们发表了一篇新工作。它将这些高度结构化的、符号化的形状程序表示与神经基元相结合,用隐式表示来描述三维形状的基本元素。
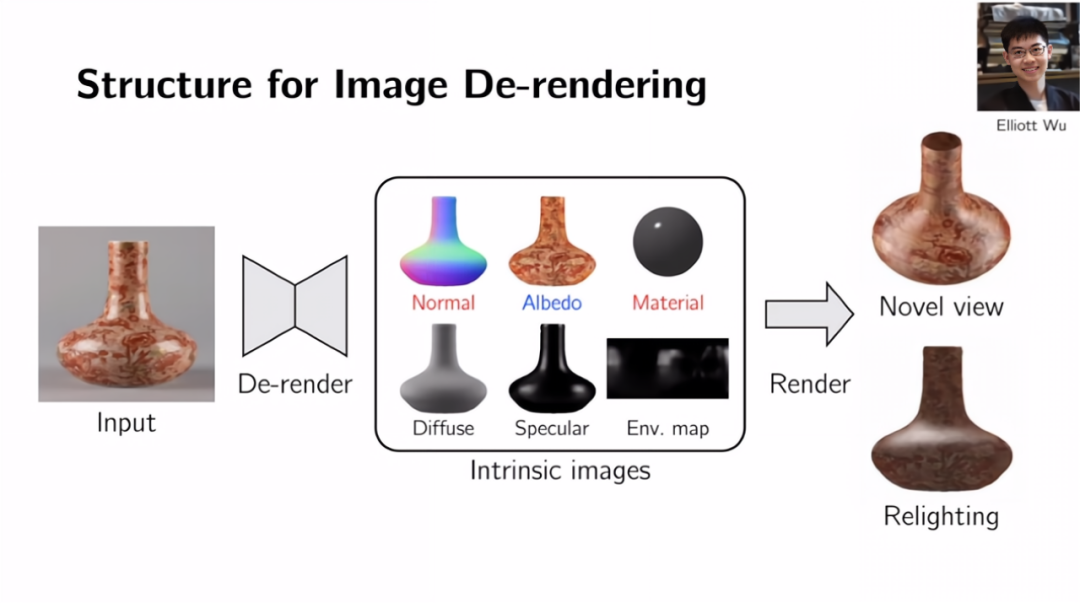
我们一直在讨论如何获得这些视觉程序编码。但更根本的问题是,为什么这个结构会首先存在?它们可能源于制造过程中的人类偏好。例如,这个美丽的花瓶,这张图像是由一些潜在的本征图像共同作用所产生的。它们包括图像的几何形状,物体表面的纹理、材质、和它们反射光线的方式。这些是组合在一起并产生彩色RGB图像的本征图像。在计算机图形学中,这个过程叫做渲染。这就是为什么计算机视觉的很大一部分是人们说的逆图形学,逆渲染,试着颠倒这个过程,得到图像中的本征图像。

这些程序般的结构或人类的偏好存在于这些本征图像中。在这个特定的花瓶的情况下,它的表面法线有很强的规律性,因为当我们制作它时,想要达到旋转对称的效果。所以我们有一种强烈的偏好,那就是让形状变得有规律。材料也是如此,物体是同质的,到处都是由相同的材料制成的。因此,法线的表征和物体的材料应该具有显式的规律性。这个物体到处都有类似的纹理。
虽然我不知道如何显式描述这种规律,但有这种隐式的规律性。而光照成分和环境光基本没有规律性。在这样的情况下,我们的问题就是如何利用不对称性或我们已经知道的结构,利用在这些本征图像中存在不同程度的归纳偏差,来从输入图像中推断它们。一旦有了这些,就可以进行各种各样的应用了。例如,将花瓶从一张图片变成3D视图,对材质建模,对其反射光的方式建模,重新点亮这些物体。
让我们讨论如何能够实施这些不同的约束。在几何学中有这些形状的明确的规律。我们知道它是旋转对称的,所以可以用高度参数化的形式来表示形状,高度是标量,半径是包含不同高度的半径的向量。这就是我们如何利用几何形状上的显式规律性的方法。
一旦有了形状,我们可以将对象平铺,这样就可以得到表面的法线和纹理。进行标准的本征图像分解,可以再将其重新渲染,计算光照、重建纹理,然后将其放置回原位,重建原始图像。
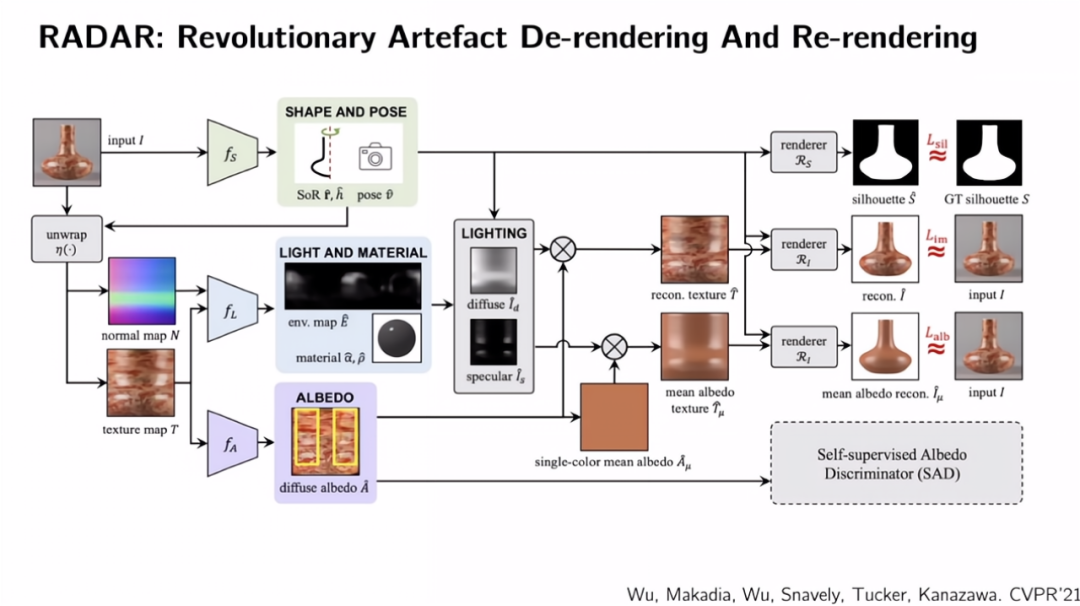
在这里,我们可以使用相同的参数对物体材质进行参数化。假设该物体上的每个点都具有相同的材质参数,它们以同样的方式反射光线。这就是如何利用物体材质的显式规律性。
对于物体纹理的隐式规律性,我们可以用一个辨别器来进行约束。我们希望推断的纹理处处类似,使得辨别器无法分辨纹理图像中的区域是否来自输入的图像中包含高光的区域。

我们的方法可以从单张图像中虚拟化物体,可以从不同的视图看到它。这里有来自不同数据集的更多结果,有点复杂,背景更多;但可以看到,我们也可以做得同样好。即使是绘画,也可以把图片变成3D,从不同的视角和合成中看到它。

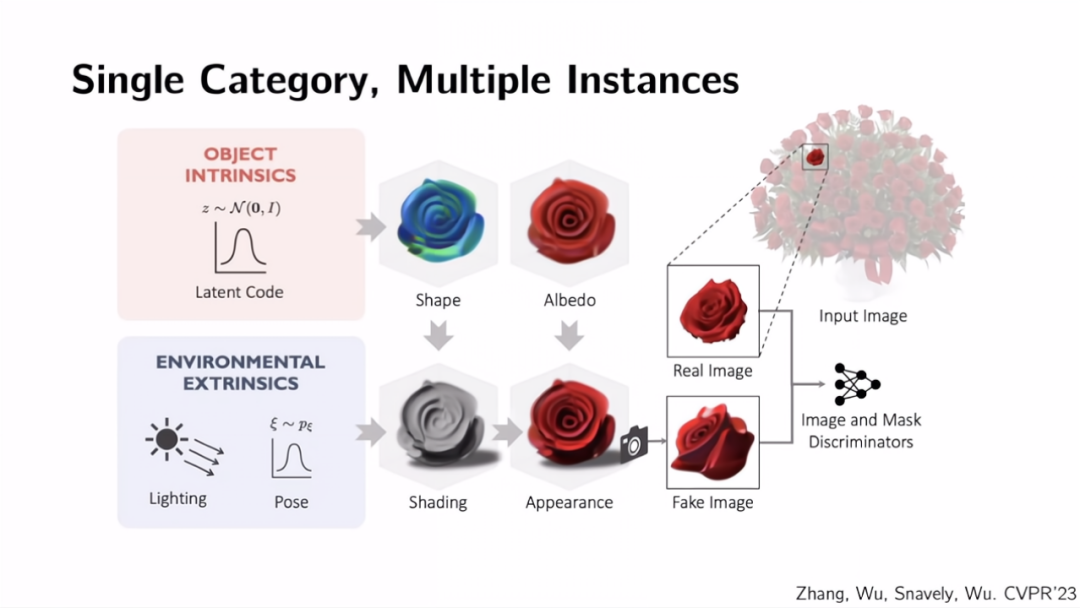
最后,让我们来考虑如何推广这个方法,让它不仅可以应用于花瓶这样的旋转对称的物体,也可以应用于更一般的物体,如下图花束中的玫瑰。同样,我们必须首先思考为什么玫瑰花里存在这些结构。之前说到,人类有一种强烈的偏好,那就是让事物变得有规律而重复。而这里的玫瑰不是由人类制造的,而是由大自然制造的。自然界也有这种非常令人震惊的归纳偏置,即同一物种的所有示例看起来都很相似,因为它们是同一物种。所有这些玫瑰看起来有点相似,有规律,因为它们属于同一个物种,只是同一物种的不同实例。我们给它们起了同一个名字,即玫瑰,也是有原因的。它们真正共享的不是花瓶那样的旋转对称的形状,真正共享的是属于它们的物体的本征特征。
每个物体(类别)都共享自己的本征特征的分布。这里的本征特征包括几何形状,包括纹理,包括构成的材料,如何反射光线,还包括它们的物理特性。如果我们能真正学到了物体本征特征的生成分布,就摆脱了一切都必须是旋转对称的假设。自然监督的编码来自哪里?因为这些对象都有相同的内在本征特征的分布,自然将它们提供给我们,然后通过三维至二维的投影产生了图片。我们的目标是,通过我们的算法学习到的本征特征的分布产生的照片,应该看起来像真实世界中的自然照片。通过执行这种更通用的约束或编码,可以再次从单个图像中学习。我们所需要的只是一束玫瑰花的照片,也许有二十、三十朵玫瑰,但仅仅从一张图像中就可以了解到它们内在本征特征的分布,其中包括几何形状、纹理和材料。
从根本上说,这个编码只有两个过程或两个原因。一个是人类有这些强烈的偏好,当我们在设计制造时,设定了自己的喜好。第一种编码规则来自人类。
第二种编码来自自然。基于进化论,一个物种的不同示例共享这些基本相似的内在特性、几何形状、反射率。这些是我们会考虑纳入的基本的自然监督代码。
这两种原因是普遍的,适用于所有场景。未来,我们可以考虑如何将其扩展到具有复杂背景的更复杂场景,考虑光照、物体和背景之间的复杂交互。

其他未来的方向包括我们如何从被动感知到与场景互动,以及与认知科学结合。还有就是和自然语言联系起来,因为语言或我们谈论事物的方式是另一个重要的自然监督来源。
- 点击“查看原文” ,观看完整大会视频回放 -