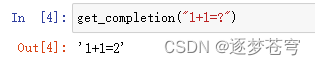
本文章介绍如何用java实现OpenAI模型训练,仅供参考
提前准备工作
- OpenAI KEY,获取方式可自行百度
- 需要自备VPN 或 使用国外服务器转发
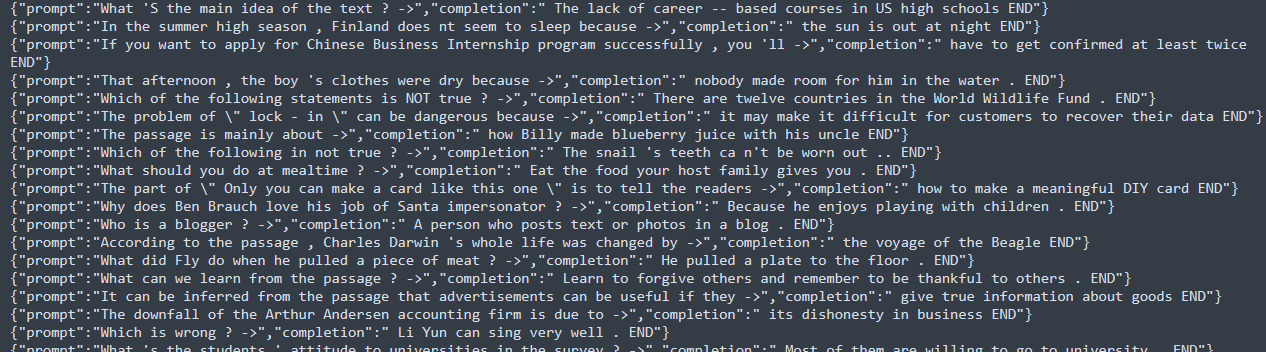
- 需要训练的数据集,文章格式要求为JSONL,格式内容详见下图(尽量不要低于500个问答)
话不多说,上代码
一、导入pom依赖
<dependency>
<groupId>cn.gjsm</groupId>
<artifactId>openai</artifactId>
<version>0.1.4</version>
</dependency>
二、初始化OpenAiClient对象
private OpenAiClient initOpenAiClient() {
return OpenAiClientFactory.createClient("OpenAI KEY");
}
三、上传数据集并创建模型
数据集可以自己解析成特定格式,务必为JSONL格式
@SneakyThrows
public String modelTraining() {
// 发送文件到ChatGPT 文件进行存储
OpenAiClient openAiClient = initOpenAiClient();
// 文件内容格式 {"prompt":"What 'S the main idea of the text ? ->","completion":" The lack of career -- based courses in US high schools END"}
RequestBody requestBody = FileUploadRequest.builder()
.file(new File("C:\\Users\\17600\\Desktop\\res2.jsonl"))
.purpose("fine-tune") // fine-tune代表训练
.build()
.toRequestBody();
Call<FileObject> fileObjectCall = openAiClient.uploadFile(requestBody);
Response<FileObject> execute = fileObjectCall.execute();
if (!execute.isSuccessful()){
log.info("code={}",execute.code());
log.info("errBody={}",execute.errorBody());
return null;
}
log.info("body={}",execute.body());
//FileObject(id=file-nHX070z0XRvokTNi84YHAYzC, object=file, bytes=181, createdAt=1680488594,filename=ajson,purpose=fine-tune)
String id = execute.body().getId();
// 创建模型
FineTunesRequest body = FineTunesRequest.builder()
.trainingFile(id)
.model("davinci") // 基于训练模型的名称
.suffix("zze-en") // 自定义训练好模型的名称
.build();
Call<FineTuneResult> fineTuneResultCall = openAiClient.callFineTunes(body);
Response<FineTuneResult> tuneExecute = fineTuneResultCall.execute();
if (tuneExecute.isSuccessful()) {
log.info("body={}",tuneExecute.body());
}else {
log.info("code={}",tuneExecute.code());
log.info("errBody={}",tuneExecute.errorBody());
}
return null;
}
注意:上传文件时可能会失败,请多次尝试
四、查询当前账号下所有已训练好名称
创建模型需要花费几分钟甚至几小时,可多次调用此方法查询训练好的模型,查询接口是免费的,可放心调用
@SneakyThrows
private void selectModel() {
OpenAiClient openAiClient = initOpenAiClient();
Response<BaseResponse<Model>> modelExecute = openAiClient.listModels().execute();
if (modelExecute.isSuccessful()) {
for (Model datum : modelExecute.body().getData()) {
log.info("id={}",datum.getId());
}
}else {
log.info("code={}",modelExecute.code());
log.info("errBody={}",modelExecute.errorBody());
}
}
五、使用模型聊天
@SneakyThrows
private void chat(String model,String msg) {
OpenAiClient openAiClient = initOpenAiClient();
CompletionRequest completionRequest = CompletionRequest.builder()
.model(model) // 指定模型名称(自己训练好的模型名称)
.stop(Arrays.asList("END")) // 指定停止标识
.prompt(Arrays.asList(String.format("%s->",msg)))
.build();
Response<CompletionResponse> completionExecute = openAiClient.callCompletion(completionRequest).execute();
if (completionExecute.isSuccessful()) {
log.info("body={}",completionExecute.body());
}else {
log.info("code={}",completionExecute.code());
log.info("errBody={}",completionExecute.errorBody());
}
}
六、注意事项
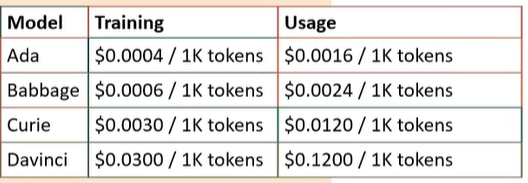
- 模型训练好之后可能达不到预想的效果,这和数据集的大小有关,所以数据集尽量保持在500条以上。数量约多,效果约好
- 选择模型时可选择 Ada、Babbage、Curie和Davinci这四种模型为基础进行训练,每个模型训练的价格也是不同,价格详见下图
OK,齐活~,文章仅供参考,不对的地方望指出,谢谢