深入理解计算机系统系列文章目录
第一章 计算机的基本组成
1. 内容概述
2. 计算机基本组成
第二章 计算机的指令和运算
第三章 处理器设计
第四章 存储器和IO系统
文章目录
- 深入理解计算机系统系列文章目录
- 前言
- 参考资料
- 一、组成架构(冯/图)
- 1. 组成架构
- 2. 冯诺依曼
- 3. 图灵
- 二、性能
- 1. 衡量指标
- 2.计时单位:CPU时钟
- 三、功耗
- 1. 功耗
- 2. 并行优化,理解阿姆达尔定律
- 3. 性能提升方法
- 总结
前言
参考资料
《深入理解计算机系统》
《深入浅出计算机组成原理》
一、组成架构(冯/图)
1. 组成架构
-
CPU 的全称是 Central Processing Unit,简称处理器,是解释(或执行)存储在主存中指令的引擎。
处理器的核心是一个大小为一个字的存储设备(或寄存器),称为程序计数器(PC)。
在任何时刻,PC都指向主存中的某条机器语言指令(即含有该条指令的地址)。
从系统通电开始,直到系统断电,处理器一直在不断地执行程序计数器指向的指令,再更新程序计数器,使其指向下一条指令。
这样的简单操作并不多,它们围绕着主存、寄存器文件(registerfile)和算术/逻辑单元(ALU)进行。
寄存器文件是一个小的存储设备,由一些单个字长的寄存器组成,每个寄存器都有唯一的名字。
ALU计算新的数据和地址值。
CPU在指令的要求下可能会执行这些操作:加载 / 存储 / 操作 / 跳转
我们将处理器的指令集架构和处理器的微体系结构区分开来:指令集架构描述的是每条机器代码指令的效果;而微体系结构描述的是处理器实际上是如何实现的。 -
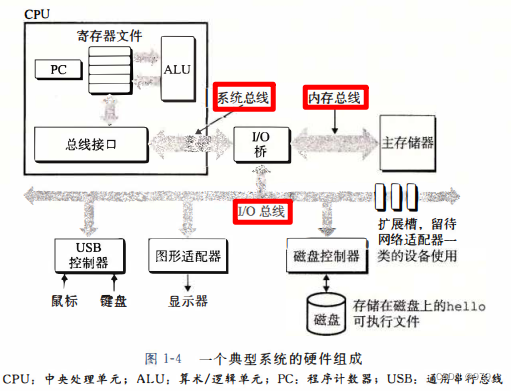
总线
贯穿整个系统的是一组电子管道,称作总线,它携带信息字节并负责在各个部件间传递。
通常总线被设计成传送定长的字节块,也就是字(word)。
字中的字节数(即字长)是一个基本的系统参数,各个系统中都不尽相同。
-
主存
主存是一个临时存储设备,在处理器执行程序时,用来存放程序和程序处理的数据。
从物理上来说,主存是由一组动态随机存取存储器(DRAM)芯片组成的。
从逻辑上来说,存储器是一个线性的字节数组,每个字节都有其唯一的地址(数组索引),这些地址是从零开始的。
一般来说,组成程序的每条机器指令都由不同数量的字节构成。 -
主板的芯片组(Chipset)和总线(Bus)解决了 CPU 和内存之间如何通信的问题。
芯片组控制了数据传输的流转,也就是数据从哪里到哪里的问题。
总线则是实际数据传输的高速公路。因此,总线速度(Bus Speed)决定了数据能传输得多快。 -
GPU(Graphics Processing Unit,图形处理器),GPU 一样可以做各种“计算”的工作
作为外部 I/O 设备,它们是通过主板上的南桥(SouthBridge)芯片组,来控制和 CPU 之间的通信的。
北桥芯片,用来作为“桥”,连接 CPU 和内存、显卡之间的通信。 -
手机制造商们选择把 CPU、内存、网络通信,乃至摄像头芯片,都封装到一个芯片,然后再嵌入到手机主板上。这种方式叫 SoC,也就是 System on a Chip(系统芯片)
2. 冯诺依曼
冯·诺依曼体系结构(Von Neumann architecture),也叫存储程序计算机。一个是“可编程”计算机,一个是“存储”计算机。
计算机是由各种门电路组合而成的,然后通过组装出一个固定的电路板,来完成一个特定的计算程序。一旦需要修改功能,就要重新组装电路。这样计算机就是“不可编程”的
-
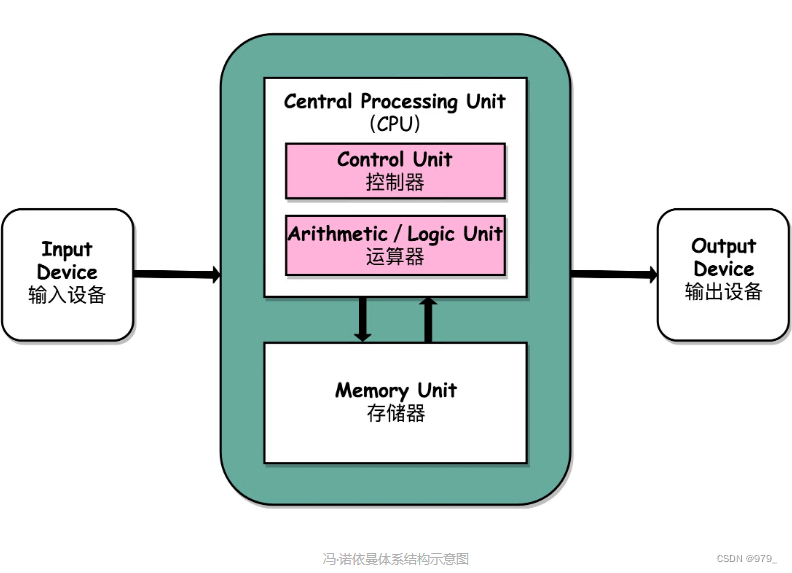
运算器
包含算术逻辑单元(Arithmetic Logic Unit,ALU)和处理器寄存器(Processor Register)的处理器单元(Processing Unit)
用来完成各种算术和逻辑运算。
因为它能够完成各种数据的处理或者计算工作,因此也有人把这个叫作数据通路(Datapath)或者运算器。 -
控制器
包含指令寄存器(Instruction Register)和程序计数器(Program Counter)的控制器单元(Control Unit/CU)
用来控制程序的流程,通常就是不同条件下的分支和跳转。
在现在的计算机里,上面的算术逻辑单元和这里的控制器单元,共同组成了我们说的 CPU。 -
存储器
用来存储数据(Data)和指令(Instruction)的内存。
以及更大容量的外部存储,在过去,可能是磁带、磁鼓这样的设备,现在通常就是硬盘。 -
各种输入和输出设备,以及对应的输入和输出机制。
我们现在无论是使用什么样的计算机,其实都是和输入输出设备在打交道。
个人电脑的鼠标键盘是输入设备,显示器是输出设备。我们用的智能手机,触摸屏既是输入设备,又是输出设备。
而跑在各种云上的服务器,则是通过网络来进行输入和输出。这个时候,网卡既是输入设备又是输出设备。
任何一台计算机的任何一个部件都可以归到运算器、控制器、存储器、输入设备和输出设备中,而所有的现代计算机也都是基于这个基础架构来设计开发的。
而所有的计算机程序,也都可以抽象为从输入设备读取输入信息,通过运算器和控制器来执行存储在存储器里的程序,最终把结果输出到输出设备中。
而我们所有撰写的无论高级还是低级语言的程序,也都是基于这样一个抽象框架来进行运作的。
3. 图灵
图灵机是一种 思想模型 (计算机的基本理论基础),是一种有穷的、构造性的问题的问题求解思路,图灵认为凡是能用算法解决的问题也一定能用图灵机解决;
冯诺依曼提出了“存储程序”的计算机设计思想,并“参照”图灵模型设计了历史上第一台电子计算机,即冯诺依曼机。
图零机是一个抽象的”思维实验“,而冯诺依曼机就是对应着这个”思维实验“的”物理实现“。
相互之间颇有理论物理学家和实验物理学家的合作关系的意思,可谓是一个问题的一体两面。
冯诺依曼给出了计算机最优化的结构,而图灵给计算机能做的事情在数学上画出了一个边界:
- 世界上有很多问题,其中只有一小部分是数学问题;
- 在数学问题中,只有一小部分是有解的;
- 在有解的问题中,只有一部分是理想状态的图灵机可以解决的;
- 在后一类的问题中,又只有一部分是今天实际的计算机可以解决的。
二、性能
1. 衡量指标
第一个是响应时间(Response time)或者叫执行时间(Execution time)。想要提升响应时间这个性能指标,你可以理解为让计算机“跑得更快”。
第二个是吞吐率(Throughput)或者带宽(Bandwidth),想要提升这个指标,你可以理解为让计算机“搬得更多”。
性能 = 1/ 响应时间
2.计时单位:CPU时钟
Wall Clock Time / Elapsed Time: 记录程序运行结束的时间减去程序开始运行的时间。就是在运行程序期间,挂在墙上的钟走掉的时间。
- time 命令

它会返回三个值,
第一个是 real time,也就是我们说的 Wall Clock Time,也就是运行程序整个过程中流逝掉的时间;
第二个是 user time,也就是 CPU 在运行你的程序,在用户态运行指令的时间;
第三个是 sys time,是 CPU 在运行你的程序,在操作系统内核里运行指令的时间。
而程序实际花费的 CPU 执行时间(CPU Time),就是 user time 加上 sys time。
其次,即使我们已经拿到了 CPU 时间,我们也不一定可以直接“比较”出两个程序的性能差异。
除了 CPU 之外,时间这个性能指标还会受到主板、内存这些其他相关硬件的影响。
所以,我们需要对“时间”这个我们可以感知的指标进行拆解,把程序的 CPU 执行时间变成 CPU 时钟周期数(CPU Cycles)和 时钟周期时间(Clock Cycle)的乘积。
程序的 CPU 执行时间 = CPU 时钟周期数 × 时钟周期时间
- 时钟周期时间
CPU 内部,和我们平时戴的电子石英表类似,有一个叫晶体振荡器(Oscillator Crystal)的东西,简称为晶振。
我们把晶振当成 CPU 内部的电子表来使用。晶振带来的每一次“滴答”,就是时钟周期时间。
2.8GHz 就代表,我们 CPU 的一个“钟表”能够识别出来的最小的时间间隔。在我这个 2.8GHz 的 CPU 上,这个时钟周期时间,就是 1/2.8G。
“超频”这个概念,这说的其实就相当于把买回来的 CPU 内部的钟给调快了,于是 CPU 的计算跟着这个时钟的节奏,也就自然变快了。
当然这个快不是没有代价的,CPU 跑得越快,散热的压力也就越大。就和人一样,超过生理极限,CPU 就会崩溃了。
最简单的提升性能方案,自然缩短时钟周期时间,也就是提升主频。
如果能够减少程序需要的 CPU 时钟周期数量,一样能够提升程序性能。
对于 CPU 时钟周期数,我们可以再做一个分解,把它变成“指令数×每条指令的平均时钟周期数(Cycles Per Instruction,简称 CPI)”。
程序的 CPU 执行时间 = 指令数 × CPI × Clock Cycle Time
时钟周期时间
--> 打字速度
每条指令的平均时钟周期数 CPI(一条指令到底需要多少 CPU Cycle)
--> 敲击键盘次数
指令数
--> 代码行数
三、功耗
1. 功耗
我们的 CPU,一般都被叫作超大规模集成电路(Very-Large-Scale Integration,VLSI)。这些电路,实际上都是一个个晶体管组合而成的。
CPU 在计算,其实就是让晶体管里面的“开关”不断地去“打开”和“关闭”,来组合完成各种运算和功能。
想要计算得快,一方面,我们要在 CPU 里,同样的面积里面,多放一些晶体管,也就是增加密度;另一方面,我们要让晶体管“打开”和“关闭”得更快一点,也就是提升主频。
而这两者,都会增加功耗,带来耗电和散热的问题。
如果 CPU 的面积大,晶体管之间的距离变大,电信号传输的时间就会变长,运算速度自然就慢了。
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
同样的面积下,我们想要多放一点晶体管,就要把晶体管造得小一点。
这个就是平时我们所说的提升“制程”。从 28nm 到 7nm,相当于晶体管本身变成了原来的 1/4 大小。
这个就相当于我们在工厂里,同样的活儿,我们要找瘦小一点的工人,这样一个工厂里面就可以多一些人。
提升主频,让开关的频率变快,也就是要找手脚更快的工人。
在整个功耗的公式里面,功耗和电压的平方是成正比的。这意味着电压下降到原来的 1/5,整个的功耗会变成原来的 1/25。
2. 并行优化,理解阿姆达尔定律
虽然从上海到北京的时间没有变,但是一次飞 8 架飞机能够运的东西自然就变多了,也就是所谓的“吞吐率”变大了。
所以,不管你有没有需要,现在 CPU 的性能就是提升了 2 倍乃至 8 倍、16 倍。这也是一个最常见的提升性能的方式,通过并行提高性能。
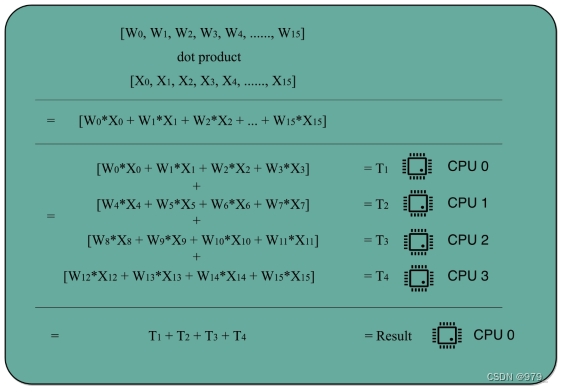
如果想要使用这种思想,需要满足这样几个条件。
1. 需要进行的计算,本身可以分解成几个可以并行的任务。好比上面的乘法和加法计算,几个人可以同时进行,不会影响最后的结果。
2. 需要能够分解好问题,并确保几个人的结果能够汇总到一起。
3. 在“汇总”这个阶段,是没有办法并行进行的,还是得顺序执行,一步一步来。
- 阿姆达尔定律
对于一个程序进行优化之后,处理器并行运算之后效率提升的情况。
优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间
在刚刚的向量点积例子里,4 个人同时计算向量的一小段点积,就是通过并行提高了这部分的计算性能。
但是,这 4 个人的计算结果,最终还是要在一个人那里进行汇总相加。
这部分汇总相加的时间,是不能通过并行来优化的,也就是上面的公式里面不受影响的执行时间这一部分。
3. 性能提升方法
在“摩尔定律”和“并行计算”之外,在整个计算机组成层面,还有这样几个原则性的性能提升方法。
-
加速大概率事件。
最典型的就是,过去几年流行的深度学习,整个计算过程中,99% 都是向量和矩阵计算,于是,工程师们通过用 GPU 替代 CPU,大幅度提升了深度学习的模型训练过程。
本来一个 CPU 需要跑几小时甚至几天的程序,GPU 只需要几分钟就好了。Google 更是不满足于 GPU 的性能,进一步地推出了 TPU。 -
通过流水线提高性能。
现代的工厂里的生产线叫“流水线”。我们可以把装配 iPhone 这样的任务拆分成一个个细分的任务,让每个人都只需要处理一道工序,最大化整个工厂的生产效率。
类似的,我们的 CPU 其实就是一个“运算工厂”。
我们把 CPU 指令执行的过程进行拆分,细化运行,也是现代 CPU 在主频没有办法提升那么多的情况下,性能仍然可以得到提升的重要原因之一。 -
通过预测提高性能。
通过预先猜测下一步该干什么,而不是等上一步运行的结果,提前进行运算,也是让程序跑得更快一点的办法。
典型的例子就是在一个循环访问数组的时候,凭经验,你也会猜到下一步我们会访问数组的下一项。