文章目录
- 一. 字典的创建
- 二. 字典的操作
- 1. 查找 key
- 2. 新增键值对
- 3. 删除键值对
- 4. 遍历字典
- 4.1 使用 for 循环遍历字典
- 4.2 通过方法遍历字典
- keys() 获取到字典中所有 key
- values() 获取到字典中的所以 value
- items 获取到字典中的所有键值对
- 三. 理解字典操作的效率
一. 字典的创建
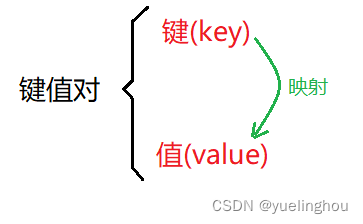
键值对是计算机中一个非常重要的概念,它由两部分组成:键(key)、值(value)
注意事项:
- 在 Python 的字典中,可以同时包含很多个键值对,但要求每一个键值对的键不能重复,值可以重复。
- 一个字典中的 key 的类型不一定都一样
- 一个字典中的 value 的类型也不必都一样
- 字典对于 key 是什么类型,有约束
- 字典对于 value 是什么类型,没有约束
可以有两种方法创建字典:
a = {}
print(type(a))
b = dict()
print(type(b))
-------运行结果-------
<class 'dict'>
<class 'dict'>
当然我们也可以在创建字典对象的同时设定初始值:

二. 字典的操作
字典的各种操作,都是针对 key 来进行的。
1. 查找 key
1)使用in、not in来判定某个 key 是否在字典中存在
a = {
'id': 1,
'name': 'zhangsan',
}
print('id' in a)
print('classId' in a)
-------运行结果-------
True
False
2)使用 [] 来根据 key 获取到 value
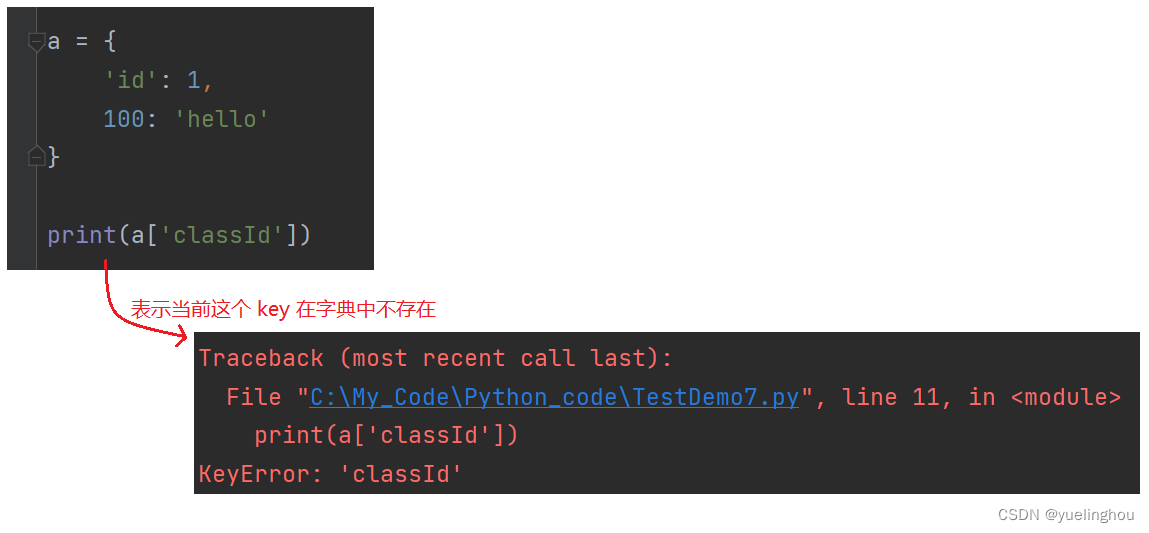
a = {
'id': 1,
100: 'hello'
}
print(a['id'])
print(a[100])
# 查找到之后可以修改 value
a['id'] = 3
print(a['id'])
-------运行结果-------
1
hello
3
如果括号内的 key 不存在于字典对象中,那么在查找时就会抛异常:
对比字典和列表的查找操作
对于字典来说,使用 in 或者 [ ] 来获取 vlaue,都是非常高效的,因为字典背后使用了哈希表这个数据结构
对于列表来说,使用 in 是比较低效的,因为它需要把整个列表遍历一遍;而使用 [ ] 是比较高效的,它类似于数组或顺序表取下标的操作。
2. 新增键值对
直接使用使用[]插入键值对
a = {
'id': 1,
'name':'zhangsan'
}
# 这个操作就是往字典中插入新的键值对
a['score'] = 100
注意区分不同情况下 [ ] 的意义:

这里就和前面说的,变量的创建类似:
- a = 10,a当前不存在,这里就是对于变量(创建新变量)
- a = 10,a当前已经存在,这里就是修改变量
3. 删除键值对
使用pop(key)方法,根据 key 来删除键值对
a = {
'id': 1,
'name':'zhangsan'
}
a.pop('name')
-------运行结果-------
{'id': 1}
4. 遍历字典
遍历指的就是把一个可迭代对象,里面包含的元素依次取出来,并进行一些操作。
4.1 使用 for 循环遍历字典
a = {
'id': 1,
'name': 'zhangsan',
'score': 90
}
# 注意取出来的是 key
for key in a:
print(key, a[key])
-------运行结果-------
id 1
name zhangsan
score 90
补充说明:在 C++ 或 Java 中,哈希表里键值对的存储是无序的(相对于 Python),但在 Python 中不一样,Python 做了特殊的处理,能保证遍历出来的顺序和插入的顺序一致。
4.2 通过方法遍历字典
keys() 获取到字典中所有 key
a = {
'id': 1,
'name': 'zhangsan',
'score': 90
}
print(a.keys())
-------运行结果-------
dict_keys(['id', 'name', 'score'])
values() 获取到字典中的所以 value
a = {
'id': 1,
'name': 'zhangsan',
'score': 90
}
print(a.values())
-------运行结果-------
dict_values([1, 'zhangsan', 90])
items 获取到字典中的所有键值对
a = {
'id': 1,
'name': 'zhangsan',
'score': 90
}
print(a.items())
-------运行结果-------
dict_items([('id', 1), ('name', 'zhangsan'), ('score', 90)])
三. 理解字典操作的效率
字典被设计出来的初衷,不是为了实现遍历,而是为了增删查改。字典是哈希表结果,所以它的增删查改操作效率是非常高的(常数级),而遍历的效率则要差一点。
不论字典中有多少元素,增删查改操作都是固定时间的,不会因为元素多了,操作就慢了。
那它是如何做到常数级效率的呢?在 Python 在专门提供一个hash()函数,通过这个函数,可以给每一个不可变对象(通常用来做 key)生成一个唯一的数字:
不可变对象,一般是可哈希的:
print(hash(0))
print(hash(3.14))
print(hash('hello'))
print(hash(True))
print(hash((1, 2, 3, 4)))
-------运行结果-------
0
322818021289917443
3403014585841488972
1
590899387183067792
可变的对象,一般是不可哈希的:
# 列表是不可哈希的
print(hash([1, 2, 3, 4]))
# 字典也是不可哈希的
print(hash(dict()))
-------运行结果-------
TypeError: unhashable type: 'list'
TypeError: unhashable type: 'dict'
这样每一个不可变对象(key)都有唯一的常数(哈希值)。我们可以把这个常数理解成数组的下标,这样就能 O(1) 的效率定位到 key,从而拿到 value。