数据集划分方法
train_test_split
train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
参数包括:
- test_size:可选参数,表示测试集的大小。可以是一个表示比例的浮点数(例如0.2表示20%的数据作为测试集),或者是一个表示样本数量的整数。默认为None。
- train_size:可选参数,表示训练集的大小。可以是一个表示比例的浮点数(例如0.8表示80%的数据作为训练集),或者是一个表示样本数量的整数。默认为None,表示训练集的大小由测试集大小决定。
- random_state:可选参数,表示随机数生成器的种子,用于随机划分数据集。设置一个整数值可以保证每次划分的结果一致。
- shuffle:可选参数,表示是否在划分数据集之前对数据进行随机打乱。默认为True,即进行随机打乱。
- stratify:可选参数,表示根据指定的标签数组进行分层划分。标签数组的长度必须与输入数据集的第一个维度相同。适用于分类问题中的类别不平衡情况。
from sklearn.model_selection import train_test_split
X, y = load_data() # 加载特征数据 X 和标签数据 y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
交叉验证方法
K折交叉验证
K折交叉验证将数据集划分为K个互不重叠的子集,称为折(Fold)。模型会进行K次训练和验证,每次使用K-1个折作为训练集,剩下的1个折作为验证集。K次训练和验证的结果会进行平均,得到最终的性能评估。K折交叉验证可以通过KFold类实现,具体用法如下
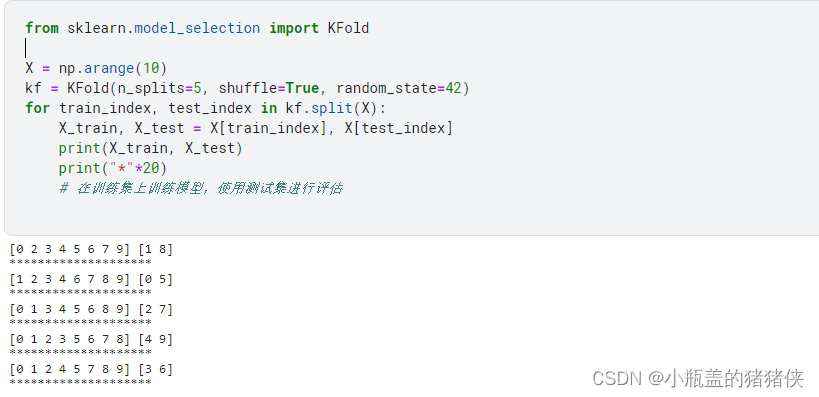
from sklearn.model_selection import KFold
X = np.arange(10)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
print(X_train, X_test)
print("*"*20)
执行结果
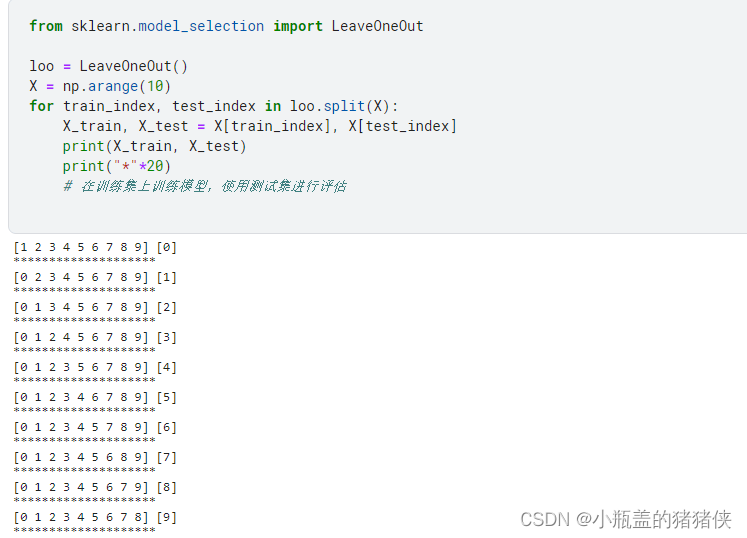
留一交叉验证LeaveOneOut
留一交叉验证是一种特殊的K折交叉验证,其中K等于数据集的样本数量。每个样本都作为单独的验证集,而其余样本作为训练集。这种方法适用于数据集较小的情况。留一交叉验证可以通过LeaveOneOut类实现,具体用法如下
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
X = np.arange(10)
for train_index, test_index in loo.split(X):
X_train, X_test = X[train_index], X[test_index]
print(X_train, X_test)
print("*"*20)
# 在训练集上训练模型,使用测试集进行评估
分组交叉验证GroupKFold
分组交叉验证是一种考虑数据集中样本之间分组关系的交叉验证方法。在某些任务中,样本可能彼此相关或存在依赖关系,例如在自然语言处理中的句子分类任务中,同一篇文章中的句子可能相互影响。为了确保模型在训练集和验证集中都包含相同分组的样本,可以使用GroupKFold类进行分组交叉验证。具体用法如下
from sklearn.model_selection import GroupKFold
gkf = GroupKFold(n_splits=3)
for train_index, test_index in gkf.split(X, y, groups):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 在训练集上训练模型,使用测试集进行评估
groups参数是一个表示样本分组的数组,长度与数据集的样本数相同。
随机重复K折交叉验证RepeatedKFold
随机重复K折交叉验证是K折交叉验证的扩展,通过多次重复执行K折交叉验证来更稳定地评估模型性能。可以使用RepeatedKFold类进行随机重复K折交叉验证。具体用法如下
from sklearn.model_selection import RepeatedKFold
rkf = RepeatedKFold(n_splits=5, n_repeats=10, random_state=42)
X = np.arange(10)
i = 0
for train_index, test_index in rkf.split(X):
X_train, X_test = X[train_index], X[test_index]
print(X_train, X_test)
print("*"*20)
i +=1
print(i)
层次化交叉验证cross_val_score
层次化交叉验证是一种嵌套的交叉验证方法,用于在模型选择和性能评估中进行双重交叉验证。外层交叉验证用于评估不同的模型或模型参数,内层交叉验证用于在每个外层验证折上进行模型训练和验证。可以通过嵌套使用cross_val_score函数来实现层次化交叉验证。具体用法如下
from sklearn.model_selection import cross_val_score
scores = cross_val_score(estimator, X, y, cv=5)
分层K折交叉验证StratifiedKFold
分层K折交叉验证是K折交叉验证的一种变体,它在划分数据集时保持了每个类别的样本比例。这对于类别不平衡的分类问题非常重要。分层K折交叉验证可以通过StratifiedKFold类实现,具体用法与K折交叉验证类似。
StratifiedKFold的作用是确保每个折中的样本比例与原始数据集中的样本比例相同。这对于处理类别不平衡的分类问题非常重要,因为如果样本比例不平衡,模型在某些折上可能无法学习到少数类别的有效模式
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 在训练集上训练模型,使用测试集进行评估
参数搜索和模型选择方法
网格搜索
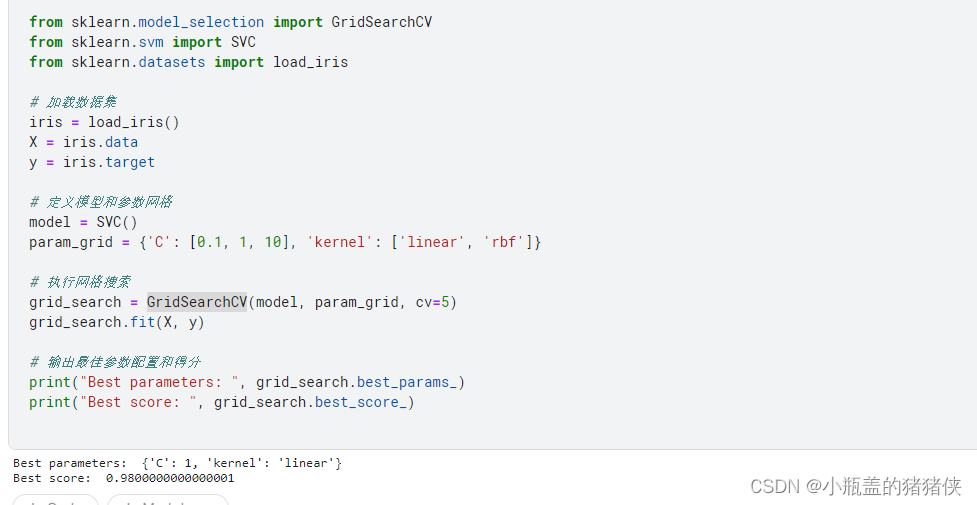
网格搜索通过遍历指定的参数组合来寻找最佳的模型参数配置。它通过穷举搜索所有参数组合,并在交叉验证中评估每个组合的性能。GridSearchCV类实现了网格搜索的功能。我们需要指定要搜索的参数和其取值范围,并指定评估指标和交叉验证的折数。示例代码如下
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 定义模型和参数网格
model = SVC()
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
# 执行网格搜索
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X, y)
# 输出最佳参数配置和得分
print("Best parameters: ", grid_search.best_params_)
print("Best score: ", grid_search.best_score_)
执行结果
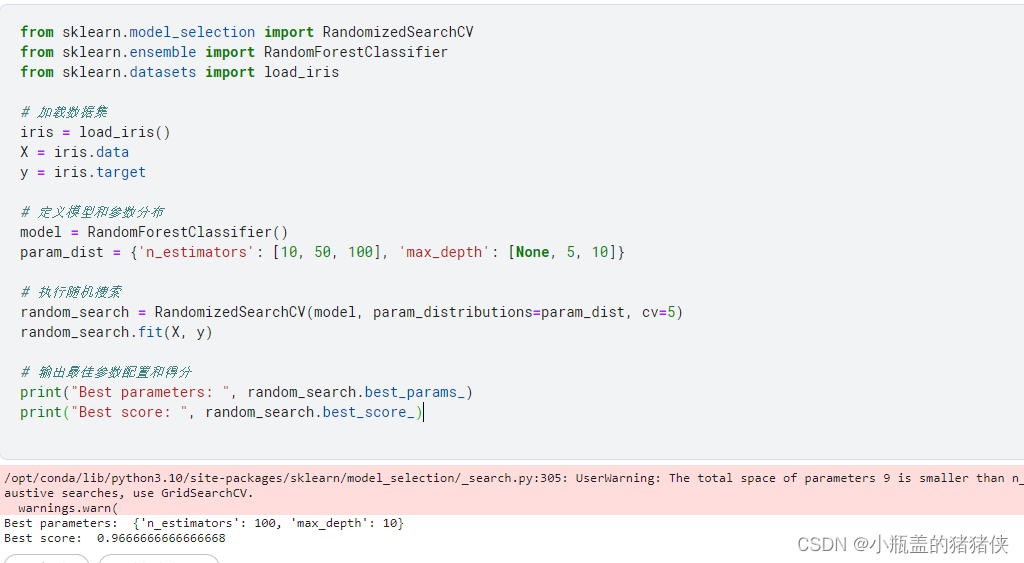
随机搜索
随机搜索通过随机抽样一组参数组合来寻找最佳的模型参数配置。与网格搜索不同,随机搜索不遍历所有参数组合,而是在指定的参数空间中进行随机抽样,并在交叉验证中评估每个参数组合的性能。RandomizedSearchCV类实现了随机搜索的功能。示例代码如下:
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 定义模型和参数分布
model = RandomForestClassifier()
param_dist = {'n_estimators': [10, 50, 100], 'max_depth': [None, 5, 10]}
# 执行随机搜索
random_search = RandomizedSearchCV(model, param_distributions=param_dist, cv=5)
random_search.fit(X, y)
# 输出最佳参数配置和得分
print("Best parameters: ", random_search.best_params_)
print("Best score: ", random_search.best_score_)
执行结果
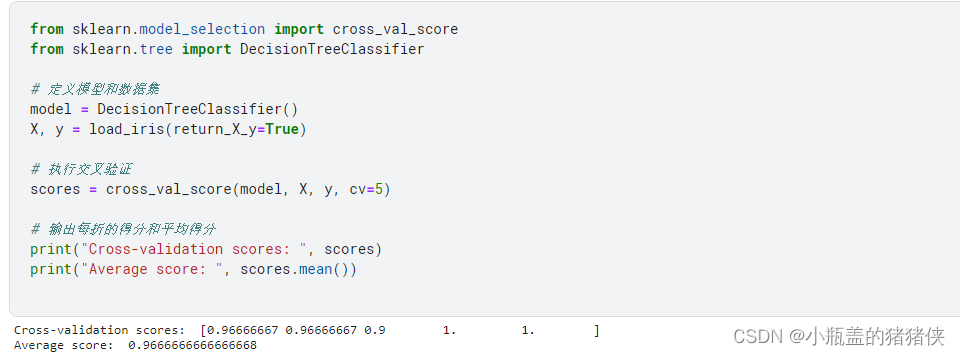
交叉验证(Cross-Validation)
将数据集分成多个折(Fold),每次使用其中一部分作为验证集,剩余部分作为训练集进行模型训练和评估。使用cross_val_score函数进行交叉验证,并指定模型和评估指标。示例代码:
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
# 定义模型和数据集
model = DecisionTreeClassifier()
X, y = load_iris(return_X_y=True)
# 执行交叉验证
scores = cross_val_score(model, X, y, cv=5)
# 输出每折的得分和平均得分
print("Cross-validation scores: ", scores)
print("Average score: ", scores.mean())
执行结果
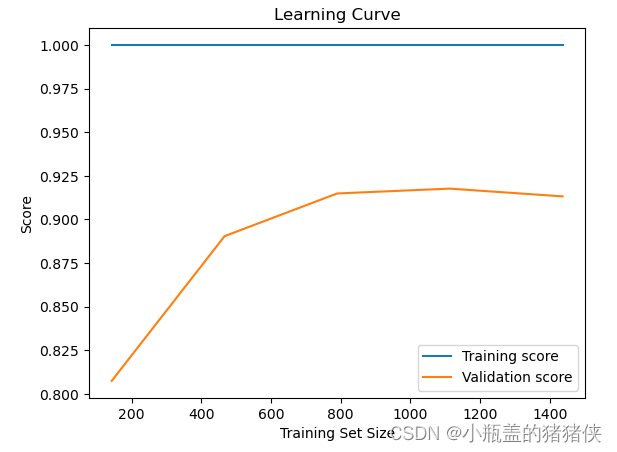
学习曲线
通过绘制不同训练集大小下模型的训练和验证得分曲线,评估模型的拟合能力和泛化能力。使用learning_curve函数生成学习曲线数据,并绘制曲线图。示例代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
from sklearn.linear_model import LogisticRegression
# 加载数据集
X, y = load_digits(return_X_y=True)
# 定义模型
model = LogisticRegression()
# 生成学习曲线数据
train_sizes, train_scores, test_scores = learning_curve(model, X, y, cv=5)
# 绘制学习曲线图
plt.plot(train_sizes, np.mean(train_scores, axis=1), label='Training score')
plt.plot(train_sizes, np.mean(test_scores, axis=1), label='Validation score')
plt.xlabel('Training Set Size')
plt.ylabel('Score')
plt.title('Learning Curve')
plt.legend(loc='best')
plt.show()
执行结果