目录
- 聚类模型的评价方法
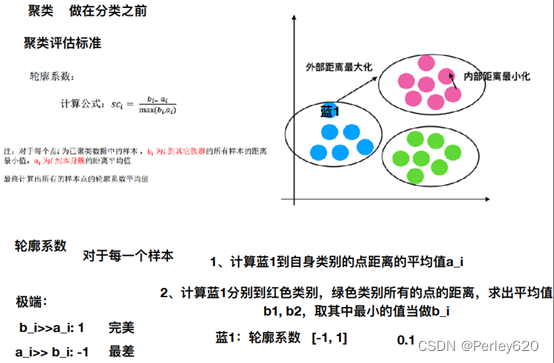
- (1)轮廓系数:
- (2)评价分类模型
- 【聚类】K-Means聚类模型
- (1)聚类步骤:
- (2)sklearn参数解析
- (3)k-means算法特点
- 神经网络模型基础
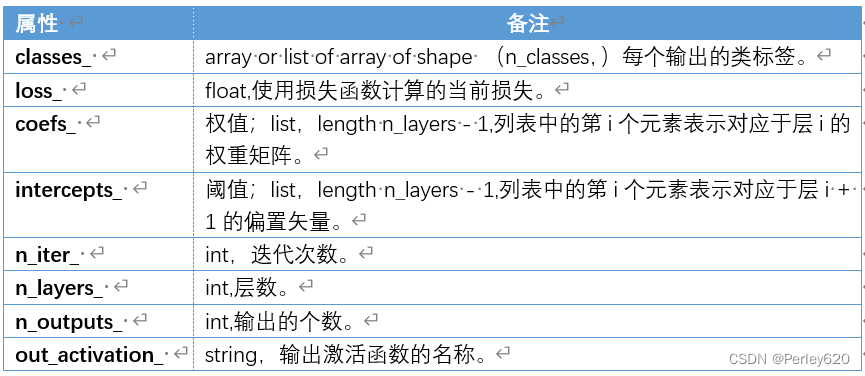
- (1)sklearn的参数
- (2)几种模型评估方法
- (3)简单的案例
聚类模型的评价方法
(1)轮廓系数:



sklearn.metrics.silhouette_score
sklearn.metrics.silhouette_score(X, labels)
计算所有样本的平均轮廓系数
X:特征值
labels:被聚类标记的目标值
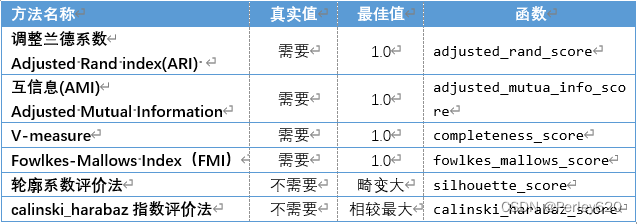
(2)评价分类模型
#接上页,评价分类模型
#FMI评价法
from sklearn.metrics import fowlkes_mallows_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = fowlkes_mallows_score(iris_target,kmeans.labels_)
print('iris数据聚%d类FMI评价分值为:%f' %(i,score))
#calinski_harabaz指数评价法
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = calinski_harabaz_score(iris_data,kmeans.labels_)
print('iris数据聚%d类calinski_harabaz指数为:%f'%(i,score))
#轮廓系数评价法
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouettteScore = []
for i in range(2,15):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = silhouette_score(iris_data,kmeans.labels_)
silhouettteScore.append(score)
plt.figure(figsize=(10,6))
plt.plot(range(2,15),silhouettteScore,linewidth=1.5, linestyle="-")
plt.show()
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
seeds = pd.read_csv('F:\python\seeds_dataset.txt',sep = '\t')
print('数据集形状为:', seeds.shape)
## 处理数据
seeds_data = seeds.iloc[:,:7].values
seeds_target = seeds.iloc[:,7].values
sees_names = seeds.columns[:7]
stdScale = StandardScaler().fit(seeds_data)
seeds_dataScale = stdScale.transform(seeds_data)
##构建并训练模型
kmeans = KMeans(n_clusters = 3,random_state=42).fit(seeds_dataScale)
print('构建的KM-eans模型为:\n',kmeans)
# FMI评价法
from sklearn.metrics import fowlkes_mallows_score
for i in range(2, 7):
##构建并训练模型
kmeans = KMeans(n_clusters=i, random_state=123).fit(seeds_dataScale)
score = fowlkes_mallows_score(seeds_target, kmeans.labels_)
print('iris数据聚%d类FMI评价分值为:%f' % (i, score))
# calinski_harabaz指数评价法
from sklearn.metrics import calinski_harabaz_score
for i in range(2, 7):
##构建并训练模型
kmeans = KMeans(n_clusters=i, random_state=123).fit(seeds_dataScale)
score = calinski_harabaz_score(seeds_dataScale, kmeans.labels_)
print('iris数据聚%d类calinski_harabaz指数为:%f' % (i, score))
# 轮廓系数评价法
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouettteScore = []
for i in range(2, 15):
##构建并训练模型
kmeans = KMeans(n_clusters=i, random_state=123).fit(seeds_dataScale)
score = silhouette_score(seeds_dataScale, kmeans.labels_)
silhouettteScore.append(score)
plt.figure(figsize=(10, 6))
plt.plot(range(2, 15), silhouettteScore, linewidth=1.5, linestyle="-")
plt.show()
【聚类】K-Means聚类模型

(1)聚类步骤:
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
1、降维之后的数据
2、k-means聚类
3、聚类结果显示
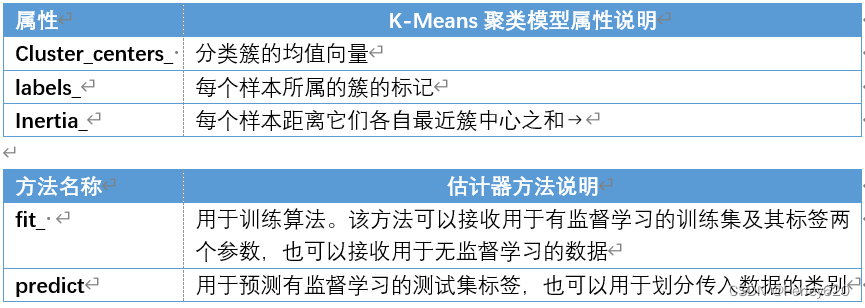
(2)sklearn参数解析


sklearn.cluster.Kmeans
sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
k-means聚类
n_clusters:开始的聚类中心数量
init:初始化方法,默认为'k-means ++’
labels_:默认标记的类型,可以和真实值比较(不是值比较)

(3)k-means算法特点
特点分析:
采用迭代式算法,直观易懂并且非常实用
缺点:容易收敛到局部最优解(多次聚类)
需要预先设定簇的数量(k-means++解决)

from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
iris = load_iris()
iris_data = iris['data'] ##提取数据集中的特征
iris_target = iris['target'] ## 提取数据集中的标签
iris_names = iris['feature_names'] ### 提取特征名
scale = MinMaxScaler().fit(iris_data)## 训练规则
iris_dataScale = scale.transform(iris_data) ## 应用规则
kmeans = KMeans(n_clusters = 3,random_state=123).fit(iris_dataScale) ##构建并训练模型
print('构建的K-Means模型为:\n',kmeans)
#用于预测
result = kmeans.predict([[1.5,1.5,1.5,1.5]])
print('花瓣花萼长度宽度全为1.5的鸢尾花预测类别为:', result[0])
#多维数据的可视化处理
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
##使用TSNE进行数据降维,降成两维
tsne = TSNE(n_components=2,init='random',
random_state=177).fit(iris_data)
df=pd.DataFrame(tsne.embedding_) ##将原始数据转换为DataFrame
df['labels'] = kmeans.labels_ ##将聚类结果存储进df数据表
##提取不同标签的数据
df1 = df[df['labels']==0]
df2 = df[df['labels']==1]
df3 = df[df['labels']==2]
## 绘制图形
fig = plt.figure(figsize=(9,6)) ##设定空白画布,并制定大小
##用不同的颜色表示不同数据
plt.plot(df1[0],df1[1],'bo',df2[0],df2[1],'r*',
df3[0],df3[1],'gD')
#plt.savefig('../tmp/聚类结果.png')
#plt.show() ##显示图片
神经网络模型基础
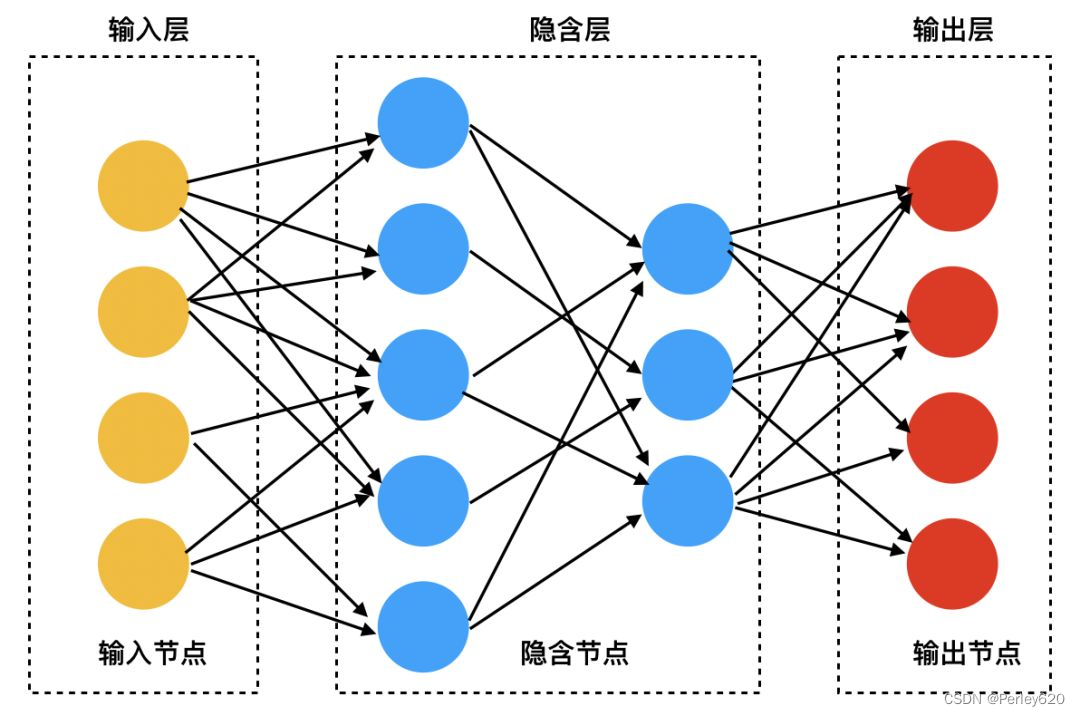
(1)sklearn的参数



import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
cancer = load_breast_cancer()
cancer_data = cancer['data']
cancer_target = cancer['target']
cancer_names = cancer['feature_names']
## 将数据划分为训练集测试集
cancer_data_train,cancer_data_test, \
cancer_target_train,cancer_target_test = \
train_test_split(cancer_data,cancer_target,
test_size = 0.2,random_state = 22)
## 数据标准化
stdScaler = StandardScaler().fit(cancer_data_train)
cancer_trainStd = stdScaler.transform(cancer_data_train)
cancer_testStd = stdScaler.transform(cancer_data_test)
## 建立SVM模型
bpnn = MLPClassifier(hidden_layer_sizes = (17,10),
max_iter = 200, solver = 'lbfgs',random_state=45)
bpnn.fit(cancer_trainStd, cancer_target_train)
## 保存模型
#from sklearn.externals import joblib
#joblib.dump(bpnn,'water_heater_nnet.m')
print('建立的神经网络模型为:\n',bpnn)
## 预测训练集结果
cancer_target_pred = bpnn.predict(cancer_testStd)
print('预测前20个结果为:\n',cancer_target_pred[:20])
## 求出预测和真实一样的数目
true = np.sum(cancer_target_pred == cancer_target_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', cancer_target_test.shape[0]-true)
print('预测结果准确率为:', true/cancer_target_test.shape[0])
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
## 求出ROC曲线的x轴和y轴
fpr, tpr, thresholds = \
roc_curve(cancer_target_test,cancer_target_pred)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False ## 设置正常显示符号
plt.figure(figsize=(10,6))
plt.xlim(0,1) ##设定x轴的范围
plt.ylim(0.0,1.1) ## 设定y轴的范围
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('乳腺癌预测ROC曲线')
plt.plot(fpr,tpr,linewidth=2, linestyle="-",color='red')
plt.show()
(2)几种模型评估方法

(3)简单的案例
import pandas as pd
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score,precision_score, \
recall_score,f1_score,cohen_kappa_score
abalone = pd.read_csv('F:\\python\\abalone.data',sep=',')
## 将数据和标签拆开
abalone_data = abalone.iloc[:,:8]
abalone_target = abalone.iloc[:,8]
## 连续型特征离散化
sex = pd.get_dummies(abalone_data['sex'])
abalone_data = pd.concat([abalone_data,sex],axis = 1 )
abalone_data.drop('sex',axis = 1,inplace = True)
## 划分训练集,测试集
abalone_train,abalone_test, \
abalone_target_train,abalone_target_test = \
train_test_split(abalone_data,abalone_target,
train_size = 0.8,random_state = 42)
## 标准化
stdScaler = StandardScaler().fit(abalone_train)
abalone_std_train = stdScaler.transform(abalone_train)
abalone_std_test = stdScaler.transform(abalone_test)
## 建模
bpnn = MLPClassifier(hidden_layer_sizes = (17,10),
max_iter = 200, solver = 'lbfgs',random_state=45)
bpnn.fit(abalone_std_train, abalone_target_train)
## 保存模型
print('构建的模型为:\n',bpnn)
# 代码 6-23
abalone_target_pred = bpnn.predict(abalone_std_test)
print('abalone数据集的BP分类报告为:\n',
classification_report(abalone_target_test,abalone_target_pred))