一、参数训练
GPT模型参数的训练过程宏观上有两个大环节,先从上往下进行推理,再从下往上进行训练,具体过程为:
1、模型初始化参数随机取得;
2、计算模型输出与真实数据的差距(损失值和梯度)
3、根据损失值,反向逐层调整权重参数;
如下图:

参数的生命周期分为三个阶段:
一、参数的产生-训练。初始通过随机产生,之后多次迭代训练,最终逼近准确值。这个过程在稍后的代码实践会有所体现。
二、参数的使用--推理。这个过程主要就是大量的矩阵计算。
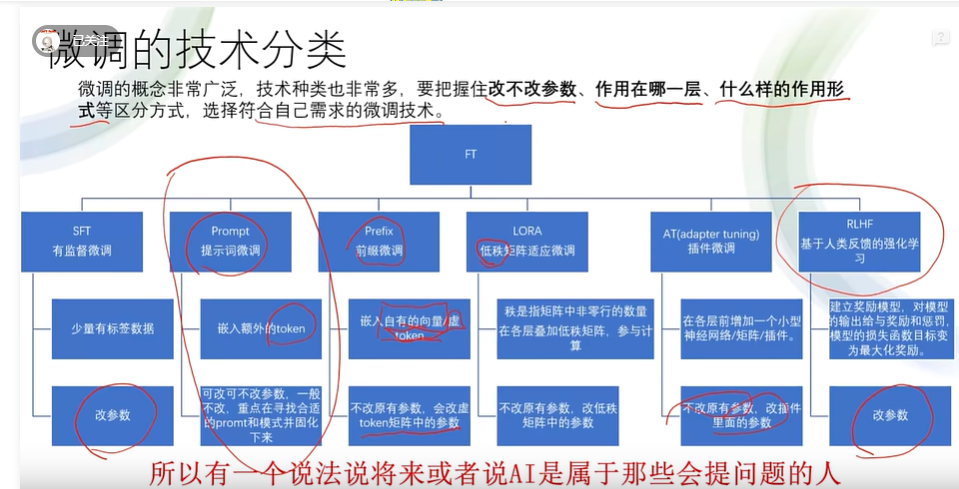
三、参数微调。微调就好比给毛坯房做装修的过程,根据不同的需求采用不同的微调方法,主要的微调方法如下所示:
二、GPT模型训练实践
接下来通过代码片段展示使用 PyTorch 库和Transformer架构从头开始构建 GPT模型的步骤。该代码分为几个部分,依次执行以下任务:
- 数据预处理:代码的第一部分对输入文本数据进行预处理,将其标记为单词列表,将每个单词编码为唯一的整数,并使用滑动窗口方法生成固定长度的序列。
- 模型配置:这部分代码定义了GPT模型的配置参数,包括转换器层数、注意力头数量、隐藏层大小和词汇表大小。
- 模型架构:这部分代码使用 PyTorch 模块定义了 GPT 模型的架构。该模型由一个嵌入层、后面的一堆转换器层和一个线性层组成,该线性层输出序列中下一个单词的词汇表的概率分布。
- 训练循环:这部分代码定义了 GPT 模型的训练循环。它使用 Adam 优化器来最小化序列的预测和实际下一个单词之间的交叉熵损失。该模型根据预处理文本数据生成的批量数据进行训练。
- 文本生成:代码的最后一部分演示了如何使用经过训练的 GPT 模型生成新文本。它使用给定的种子序列初始化上下文,并通过从模型输出的概率分布中采样来迭代生成新单词,以获取序列中的下一个单词。生成的文本被解码回单词并打印到控制台。
本次演示代码主要参考HOW TO BUILD A GPT MODEL?。 笔者直接将部分代码注释合入到代码之中,方便理解,当然,要想真正去感受,建议直接利用google Colaboratory运行调试。
以下为笔者调试的过程,可以尝试去改变里面的超参数,感受训练的过程。
max_iters设为5000,本次迭代到4999:va loss由 4.4022 调节到 1.8239。
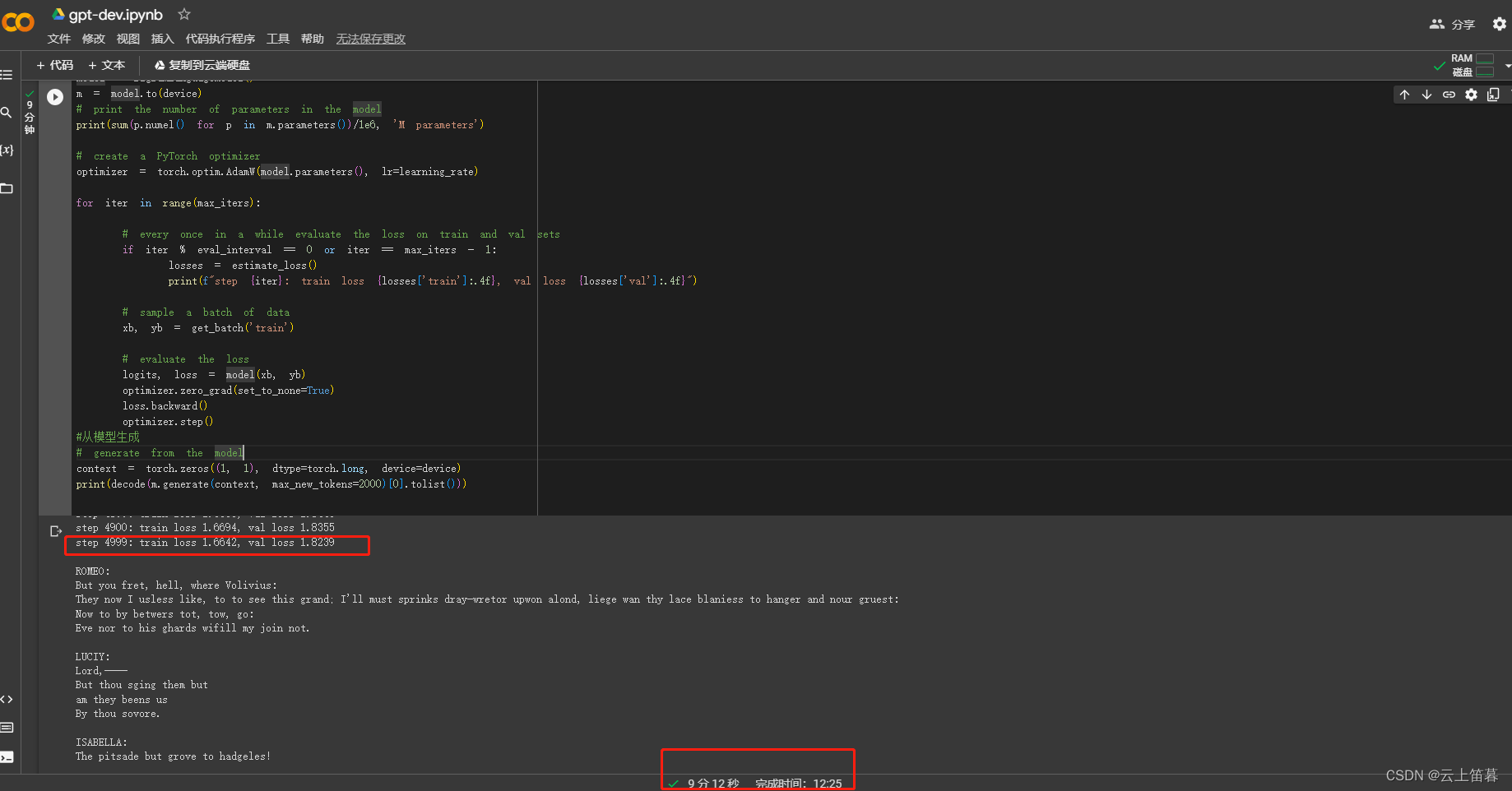
运行代码:
# 第一步是导入使用 PyTorch 构建神经网络所需的库,其中包括导入必要的模块和函数。
#在此代码片段中,开发人员正在导入 PyTorch 库,这是一种用于构建神经网络的流行深度学习框架。然后,开发人员从 torch 库中导入 nn 模块,其中包含用于定义和训练神经网络的类和函数。
import torch
import torch.nn as nn
from torch.nn import functional as F
# hyperparameters定义超参数,这些参数对训练和调微非常重要
# 这些参数决定模型的性能、速度和容量,可以通过变更参数来调节,比如把下面的最大迭代数max_iters = 5000 改为 max_iters = 1000,训练时间将变短
# 这些超参数的意义:
# batch_size:该参数确定训练期间将并行处理的独立序列的数量。较大的批量大小可以加快训练速度,但需要更多内存。
# block_size:此参数设置预测的最大上下文长度。GPT 模型根据作为输入接收的上下文生成预测,并且此参数设置该上下文的最大长度。
# max_iters:该参数设置GPT模型的最大训练迭代次数。
# eval_interval:该参数设置训练迭代次数,之后将评估模型的性能。
# Learning_rate:此参数确定优化器在训练期间的学习率。
# device:此参数设置将在其上训练 GPT 模型的设备(CPU 或 GPU)。
# eval_iters:该参数设置训练迭代次数,之后将评估并保存模型的性能。
# n_embd:该参数设置GPT模型的嵌入维度数。嵌入层将输入序列映射到高维空间,该参数决定该空间的大小。
# n_head:该参数设置GPT模型的多头注意力层中注意力头的数量。注意力机制允许模型关注输入序列的特定部分。
# n_layer:该参数设置GPT模型中的层数。
# dropout:该参数设置 GPT 模型的 dropout 概率。Dropout是一种正则化技术,在训练过程中随机丢弃一些神经网络的节点,以防止过度拟合。
batch_size = 16 # how many independent sequences will we process in parallel?
block_size = 32 # what is the maximum context length for predictions?
max_iters = 5000
eval_interval = 100
learning_rate = 1e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
eval_iters = 200
n_embd = 64
n_head = 4
n_layer = 4
dropout = 0.0
# ------------
# 读取输入文件,使用 torch.manual_seed() 为 PyTorch 的随机数生成器设置手动种子。
# 这样做是为了确保 GPT 模型的结果是可重复的。传递给 torch.manual_seed() 的参数是一个任意数字(在本例中为 1337),
# 用作随机数生成器的种子。通过设置固定种子,开发人员可以确保每次运行代码时生成相同的随机数序列,从而确保 GPT 模型在相同的数据上进行训练和测试。
torch.manual_seed(1337)
#使用 Python 的内置 open() 函数读取文本文件,并使用 read() 方法读取其内容。该文本文件包含将用于训练 GPT 模型的输入文本。
# wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
# here are all the unique characters that occur in this text,识别文本中出现的独特字符
# 此段代码为GPT模型创建词汇表
# 首先,我们使用 set() 函数和 list() 构造函数创建文本数据中存在的唯一字符的排序列表。set() 函数返回文本中唯一元素的集合,list() 构造函数将该集合转换为列表。
# Sorted() 函数按字母顺序对列表进行排序,创建文本中存在的唯一字符的排序列表。
# 接下来,我们使用 len() 函数获取字符列表的长度。这给出了文本中唯一字符的数量,并用作 GPT 模型的词汇量大小。
# 词汇量大小是决定GPT模型容量的重要超参数。词汇量越大,模型的表达能力就越强,但也会增加模型的复杂性和训练时间。
# 词汇量的大小通常是根据输入文本的大小和要解决的问题的性质来选择的。
# 创建词汇表后,文本数据中的字符可以映射为整数值,并通过 GPT 模型生成预测。
chars = sorted(list(set(text)))
vocab_size = len(chars)
# create a mapping from characters to integers,创建映射
#第一步是创建字符和整数之间的映射,这对于构建 GPT 等语言模型是必需的。
#为了使模型能够处理文本数据,它需要能够将每个字符表示为数值,这就是以下代码所完成的任务
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
# Train and test splits 对输入数据进行编码
data = torch.tensor(encode(text), dtype=torch.long)
n = int(0.9*len(data)) # first 90% will be train, rest val,90%用来训练,10%用来验证
train_data = data[:n]
val_data = data[n:]
#生成批量输入和目标数据以训练 GPT
# data loading
def get_batch(split):
# generate a small batch of data of inputs x and targets y
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
x, y = x.to(device), y.to(device)
return x, y
#使用预训练模型计算训练和验证数据集的平均损失
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
#在 Transformer 模型中定义自注意力机制的一个头
class Head(nn.Module):
""" one head of self-attention """
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B,T,C = x.shape
k = self.key(x) # (B,T,C)
q = self.query(x) # (B,T,C)
# compute attention scores ("affinities")
wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# perform the weighted aggregation of the values
v = self.value(x) # (B,T,C)
out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)
return out
# 实现多头注意力机制
class MultiHeadAttention(nn.Module):
""" multiple heads of self-attention in parallel """
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embd, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
class FeedFoward(nn.Module):
""" a simple linear layer followed by a non-linearity """
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
class Block(nn.Module):
""" Transformer block: communication followed by computation """
def __init__(self, n_embd, n_head):
# n_embd: embedding dimension, n_head: the number of heads we'd like
super().__init__()
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
# 模型训练和文本生成
# super simple bigram model
class BigramLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd) # final layer norm
self.lm_head = nn.Linear(n_embd, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
# idx and targets are both (B,T) tensor of integers
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb # (B,T,C)
x = self.blocks(x) # (B,T,C)
x = self.ln_f(x) # (B,T,C)
logits = self.lm_head(x) # (B,T,vocab_size)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# crop idx to the last block_size tokens
idx_cond = idx[:, -block_size:]
# get the predictions
logits, loss = self(idx_cond)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
model = BigramLanguageModel()
m = model.to(device)
# print the number of parameters in the model
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
for iter in range(max_iters):
# every once in a while evaluate the loss on train and val sets
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
#从模型生成
# generate from the model
context = torch.zeros((1, 1), dtype=torch.long, device=device)
print(decode(m.generate(context, max_new_tokens=2000)[0].tolist()))本文参考:
1、合集·GPT模型详细解释
2、HOW TO BUILD A GPT MODEL?
3、What Is a Transformer Model?
4、代码:https://colab.research.google.com/drive/1JMLa53HDuA-i7ZBmqV7ZnA3c_fvtXnx-?usp=sharing#scrollTo=hoelkOrFY8bN 5、封面:ChatGPT, GPT-3, & GPT-4: What is Really the Difference?
尤其感谢B站UP主三明2046,其作品《合集GPT模型详细解释》生动精彩,本系列文章充分吸收学习了该课程,并且在文章图片素材多有引用;
本文代码部分主要引用;
如有侵权,请联系笔者删除,感谢,致敬!