神经网络中输入多少数据就输出多少数据的情况如何实现
- 导读
- 数据集长什么样?
- 怎么分割数据集?
- 时间窗口分析模板
- 我知道你很急,但你先别急
- 换个思路
导读
在实习的过程中遇到了这样一种需求:给定一条序列,并另外给定一条期望序列,要求做出拟合。同时,给定序列的时候并不是只给一条,而是给了几万条,要寻找出普遍共性。在实现的过程中,中间也是踩了很多坑,所以最后写出这个经验总结帖,以免忘记。
数据集长什么样?
出于公司数据保密的原则,这里就采用模拟数据:
给定一条 f ( x ) = sin ( x ) f(x)=\sin(x) f(x)=sin(x),再给定一条 g ( x ) = cos ( 2 x ) + 0.3 g(x)=\cos(2x)+0.3 g(x)=cos(2x)+0.3。当然,为了让数据看起来不那么规则,我们在 g ( x ) g(x) g(x)中加入高斯噪声 N ( 0 , 1 ) N(0,1) N(0,1)。最后,数据集中一共 1 1 1万组数据,每组有 2 2 2条序列,每条序列 50 50 50个浮点数。
这就是基本情况了。
为了更直观的感受数据集,这里就直接画图画出来。
在绘图之前,有一个问题需要格外强调一下:这里样本是 f ( x ) f(x) f(x)与 g ( x ) g(x) g(x),我们只需要找出 f ( x ) f(x) f(x)与 g ( x ) g(x) g(x)之间的关系。所以在某种意义上来说,样本是与 x x x无关的,无论 x x x怎么样都不会影响到后续神经网络的迭代学习过程。这也解释了为什么接下来绘图都将从 x = 0 x=0 x=0开始,而不是从 x = k π 2 ( k = 0 , 1 , 2 , … ) x=\frac{k\pi}{2}(k=0,1,2,\ldots) x=2kπ(k=0,1,2,…)开始。
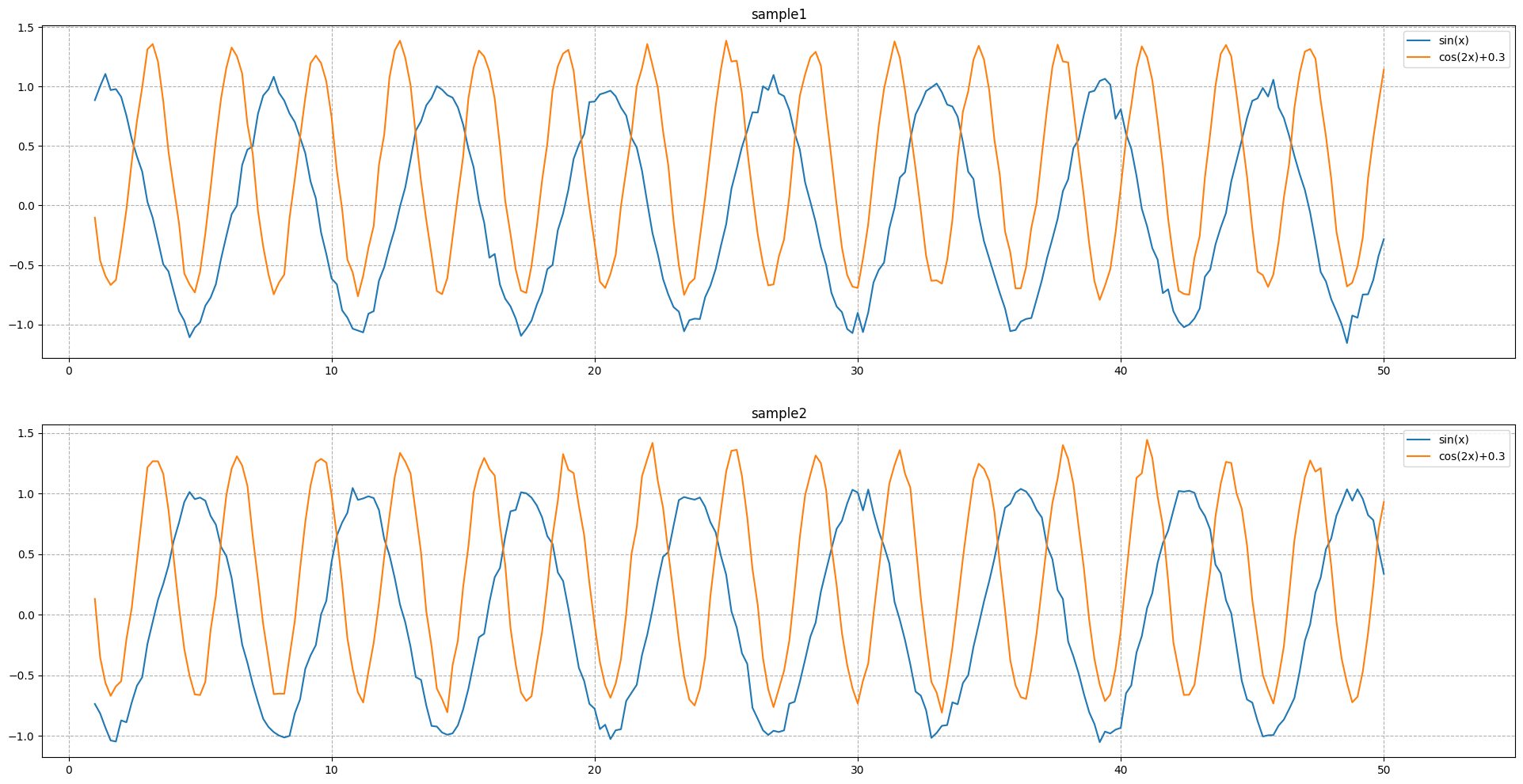
不太好看的样子
怎么分割数据集?
按照正常标准而言,需要按照 6 : 2 : 2 6:2:2 6:2:2的比例分割为训练集、验证集以及测试集。
当然你也可以为了方便,只按照 7 : 3 7:3 7:3的比例分割为训练集与测试集。因为验证集在验证的过程中并不会对模型产生直接的修改,而是给你一个大概的参考。
那么具体又应该如何划分呢?这里可是有 1 × 1 0 4 × 2 × 50 = 1 0 6 1\times10^4\times2\times50=10^6 1×104×2×50=106个浮点数,并且自变量与因变量在数目上是 1 : 1 1:1 1:1的比例,各 5 × 1 0 5 5\times10^5 5×105个。
P.S.:我属于比较笨的类型,解决问题先套模板。所以在接下来的分析过程中,也是采用逐个尝试的方式进行讲解。
时间窗口分析模板
考虑到是序列的话,那有没有可能是时间序列分析?也就是经典的股票预测模板?
当然是有可能的。
于是,就开始了一系列的操作:
- 首先将
1
1
1万组数据合并为
1
1
1组数据,然后按照固定的步长顺序分割,形成一个个一维数组,在
Python中存储为list类型; - 然后将这一个个一维数组拼起来,形成一个庞大的二维数组,并使用
pandas中的DataFrame存储为二维表; - 最后,考虑样本数据本身就具有一定的随机性,所以不考虑随机打乱顺序的过程,直接按顺序取一定比例,最后将数据集划分为 6 : 2 : 2 6:2:2 6:2:2。
这样思考当然是正确的,也必然是能够在一定程度上拟合的。
如何写代码呢?在这里我主要借鉴了这个教程:49.52实战(一)RNN股价预测
import pandas as pd
"获取数据集"
data:pd.DataFrame = pd.read_json('my.data.json')
TRAIN_SIZE:int = int(len(data) * 0.6)
VALID_SIZE:int = int(len(data) * 0.2)
train_data:pd.DataFrame = data.loc[:TRAIN_SIZE, :]
valid_data:pd.DataFrame = data.loc[TRAIN_SIZE + 1 : TRAIN_SIZE + VALID_SIZE, :]
test_data:pd.DataFrame = data.loc[VALID_SIZE + 1 :, :]
"按序列步长切割数据集"
def load_data(data, x, y, n_prev = 100):
docX, docY = [], []
for i in range(len(data) - n_prev):
docX.append(data[x].iloc[i : i + n_prev].tolist())
docY.append(data[y].iloc[i + n_prev].tolist())
alsX:np.array = np.array(docX)
alsY:np.array = np.array(docY)
return alsX, alsY
length_of_sequences = 10
X_train, y_train = load_data(train_data, 'sin', 'cos', n_prev = length_of_sequences)
X_valid, y_valid = load_data(valid_data, 'sin', 'cos', n_prev = length_of_sequences)
将其中
60
%
60\%
60%的数据提取出来作为训练集,然后设置序列长度为
10
10
10,按顺序构成格式为
(
1000
,
10
)
(1000, 10)
(1000,10)的数据集。之后再通过numpy中的reshape函数转化为(1000, 10, 1)就好啦!
但,真的就是这样吗?
我知道你很急,但你先别急
看似一切都很正常,对吧?现在是不是认为把这段代码粘在你的notebook里面之后,就会迎来走向算法应用的一大步了?
当然不是。
我们的任务是什么?在 1 1 1万组数据中找出 f ( x ) f(x) f(x)与 g ( x ) g(x) g(x)的关联关系。
怎么找?输入数据,然后运行模型,最后验证模型。
关键在哪?关键在于如何验证模型。
不妨我们再回去看看上面画的图1,我们只知道 f ( x ) f(x) f(x)对应的 g ( x ) g(x) g(x)。也就是说,我们必须要保证输入 f ( x ) f(x) f(x)中的 50 50 50个浮点数,并输出 50 50 50个预测出来的浮点数,才能与 g ( x ) g(x) g(x)进行比较。如果按照上面这个方法分割数据集,即使我们通过神经网络学出来也只能输入 ( 1000 , 10 ) (1000, 10) (1000,10)的数据。这就意味着只有 50 50 50个浮点数的 g ( x ) g(x) g(x)完全不能验证结果,就算验证也只能通过自己验证,这样也就完全不能通过样本给出有说服力的答案。
答案很明显,我们只能让 f ( x ) f(x) f(x)中的每一个浮点数通过神经网络输出一个浮点数,或者说,只能输入 50 50 50个浮点数,并输出 50 50 50个浮点数,才能够获得能够验证效果的模型。其他的模型都不能够验证效果。
换个思路
那么我们又该如何做呢?如果我们去深度学习框架的官方说明文档中,会不会有提示呢?
当然有。
深度学习的框架既然能够为人所用,那么就需要点名道姓地指出自己的框架能够在什么情景下怎么使用。
P.S.:由于我使用的是
Tensorflow的 2.12 2.12 2.12版本,所以我这边就用Tensorflow的说明文档进行说明。
在这说明文档的这一栏:Keras 中的循环神经网络 (RNN),其中有段话是这么描述的:
输出和状态
默认情况下,
RNN层的输出为每个样本包含 1 1 1个向量。此向量是与最后一个时间步骤相对应的RNN单元输出,包含关于整个输入序列的信息。此输出的形状为(batch_size, units),其中units对应于传递给层构造函数的 units 参数。如果您设置了
return_sequences=True,RNN层还能返回每个样本的整个输出序列(每个样本的每个时间步骤一个向量)。此输出的形状为(batch_size, timesteps, units)。
然后紧接着给了一个案例:
from tensorflow import keras
# 构建一个模型容器
model = keras.Sequential()
# 第一层加入一个`Embedding`,确定输入是匹配的
model.add(keras.layers.Embedding(input_dim=1000, output_dim=64))
# `GRU`接收64的输入后,将输出`(batch_size, timesteps, 256)`
model.add(keras.layers.GRU(256, return_sequences=True))
# `SimpleRNN`在文档中有提到,是全连接`RNN`,接收GRU的输出后输出`(batch_size, 128)`
model.add(keras.layers.SimpleRNN(128))
# 全连接层,决定整个网络的最终输出
model.add(keras.layers.Dense(10))
# 简单总结一下网络结构
model.summary()
那么,接下来就是按照这个网络设置数据集了。
如何设置呢?
当然,我们有一种极其粗暴的方法:用循环,把每组数据的两条序列全部扔进去,循环 1 1 1万次。我们的模型会随着循环的累计而不断拟合,最终达到我们想要的精度。
简单用代码整理一下思路就是:
"""
取消`tensorflow`本身一大串不明所以的输出
替换为轻便的`tqdm`进度条
其中`verbose`取值有0,1,2
分别代表【不输出】、【输出每个epoch的进度】、【完整输出】
最后用一个变量保存`model.complie`方法中指定的输出值
方便训练结束之后的可视化
"""
from tqdm import trange
for i in trange(int(1e4)):
record = model.fit(x_train[i, 'sin'], y_train[i, 'cos'], verbose = 0)
这种简单粗暴的方式往往在快速出成果的demo中有奇效,但也只适用于时间不够的情况了。
实际上,稍微有点不管什么编程语言的经验的话,都知道一个常识:循环一定是CPU做。这也就意味着你的训练速度将会是龟速。就算GPU参与了,那也只是参与了相当有限的矩阵运算,然后就回到CPU那边处理循环了。执行效率不如隔壁数学系大学生算的更快更便宜。
那么为了提高效率,我们应该怎么办呢?
我们不妨发挥联想:图像处理方面又该如何做呢?
对于一张大图,往往都是分割为好几张子图,每个子图代表一个矩阵;然后每个子图都有一个标签,这样对应起来就是由若干矩阵构成的数组,与同样数目的标签构成的数组。
在这个任务中呢,对照着这个例子,我们大概也能够有一个基本的概念:
首先是已经帮我们分好了 1 1 1万组样本,就不需要分割子图;其次就是每组样本有自变量有因变量,对应起来虽然不是矩阵对标签,但数字对数字也算一种样本与标签,而且数量一致。
这样的话,应该就完美了。
简单用代码整理一下思路就是:
import numpy as np
import pandas as pd
data:pd.DataFrame = pd.read_json('my.data.json')
TRAIN_SIZE:int = int(len(data) * 0.6)
VALID_SIZE:int = int(len(data) * 0.2)
COL_SIZE:int = 75
ROW_SIZE:int = 1
X_train:np.array = np.array(data.loc[:TRAIN_SIZE, 'sin'].values.tolist()).reshape(TRAIN_SIZE, COL_SIZE, ROW_SIZE)
y_train:np.array = np.array(data.loc[:TRAIN_SIZE, 'cos'].values.tolist()).reshape(TRAIN_SIZE, COL_SIZE, ROW_SIZE)
这里写的比较简短,把几个步骤压缩到一起去了,所以我解释一下流程:
- 首先,这里提取出所有的训练样本中的自变量,也就是
f
(
x
)
=
sin
(
x
)
f(x)=\sin(x)
f(x)=sin(x),获得
DataFrame类型的data.loc[:TRAIN_SIZE, 'sin'] - 其次,我们可以看到读取的是
json数据。在json数据中,如果给了一个序列的话,在read_json读取后则会以list形式出现,即使我们使用np.array方法强行转化后,也保持原来的list类型,在后续迭代的过程中会报错:list类型不支持转化为Tensor类型。所以,我们需要强行把所有的数据拉出来:- 先用
values方法,获得类型为:array(list[],list[],...) - 再用
tolist方法,获得类型为list[[],[],...] - 最后用
np.array方法初始化,获得np.array类型
- 先用
- 完成这个过程后,为了使得这个数据集能够进一步转化为
Tensor,需要转化为 ( x , y , 1 ) (x,y,1) (x,y,1)的3D形式,也就是reshape方法
同理也可以获得因变量。
到这里,正确又高效的划分才彻底结束。
接下来就能愉快地训练了。