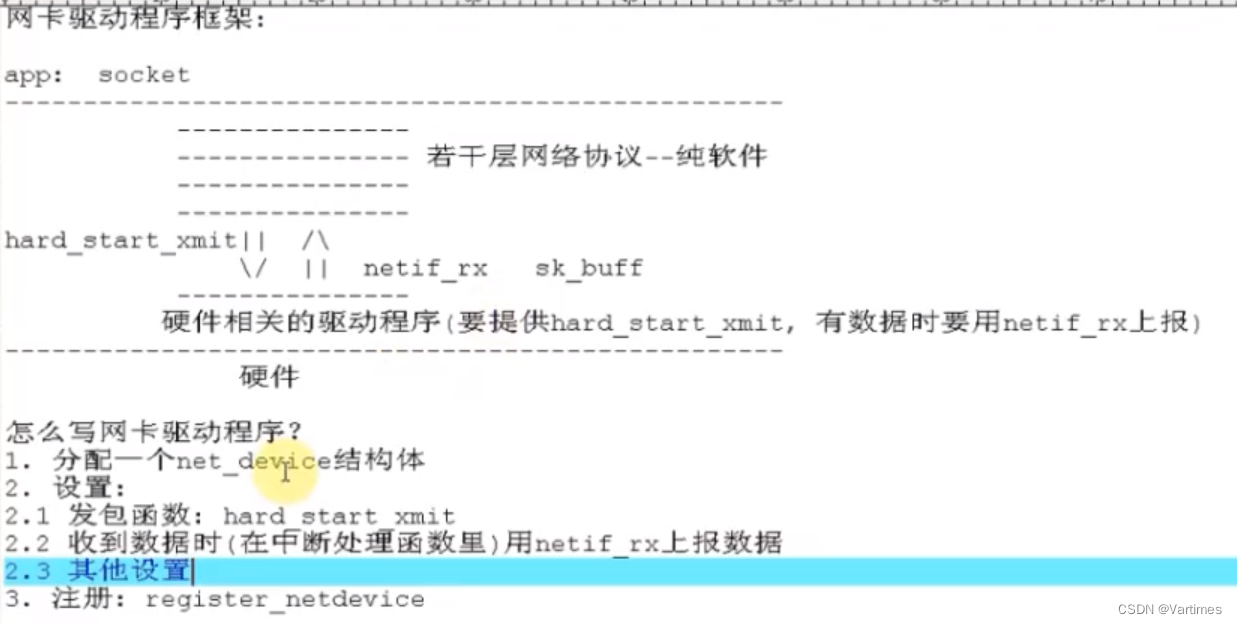
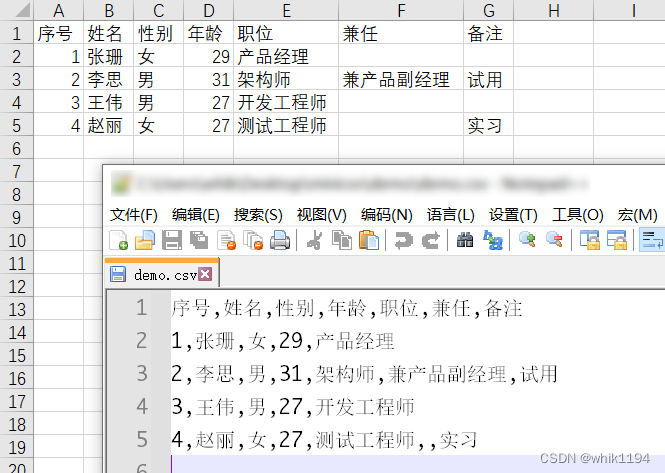
网络协议分为很多层,而驱动这层对应于实际的物理网卡部分,这也是最底层的部分,以cs89x0.c这个驱动程序为例来分析下网卡驱动程序框架。
正常开发一个驱动程序时,一般都遵循以下几个步骤:
1.分配某个结构体
2.设置该结构体
3.注册
4.硬件相关操作
首先分析cs89x0.c的入口函数
int __init init_module(void)
{
struct net_device *dev = alloc_etherdev(sizeof(struct net_local));
struct net_local *lp;
int ret = 0;
#if defined(CONFIG_ARCH_S3C2410)
unsigned int oldval_bwscon; /* 用来保存BWSCON寄存器的值 */
unsigned int oldval_bankcon3; /* 用来保存S3C2410_BANKCON3寄存器的值 */
#endif
#if DEBUGGING
net_debug = debug;
#else
debug = 0;
#endif
if (!dev)
return -ENOMEM;
#if defined(CONFIG_ARCH_S3C2410)
// 将CS8900A的物理地址转换为虚拟地址,0x300是CS8900A内部的IO空间的偏移地址
dev->base_addr = io = (unsigned int)ioremap(S3C24XX_PA_CS8900, SZ_1M) + 0x300;
dev->irq = irq = cs8900_irq_map[0]; /* 中断号 */
/* 设置默认MAC地址,
* MAC地址可以由CS8900A外接的EEPROM设定(有些单板没接EEPROM),
* 或者启动系统后使用ifconfig修改
*/
dev->dev_addr[0] = 0x08;
dev->dev_addr[1] = 0x89;
dev->dev_addr[2] = 0x89;
dev->dev_addr[3] = 0x89;
dev->dev_addr[4] = 0x89;
dev->dev_addr[5] = 0x89;
/* 设置Bank3: 总线宽度为16, 使能nWAIT, 使能UB/LB。by www.100ask.net */
oldval_bwscon = *((volatile unsigned int *)S3C2410_BWSCON);
*((volatile unsigned int *)S3C2410_BWSCON) = (oldval_bwscon & ~(3<<12)) \
| S3C2410_BWSCON_DW3_16 | S3C2410_BWSCON_WS3 | S3C2410_BWSCON_ST3;
/* 设置BANK3的时间参数, by www.100ask.net */
oldval_bankcon3 = *((volatile unsigned int *)S3C2410_BANKCON3);
*((volatile unsigned int *)S3C2410_BANKCON3) = 0x1f7c;
#else
dev->irq = irq;
dev->base_addr = io;
#endif
lp = netdev_priv(dev);
#if ALLOW_DMA
if (use_dma) {
lp->use_dma = use_dma;
lp->dma = dma;
lp->dmasize = dmasize;
}
#endif
spin_lock_init(&lp->lock);
/* boy, they'd better get these right */
if (!strcmp(media, "rj45"))
lp->adapter_cnf = A_CNF_MEDIA_10B_T | A_CNF_10B_T;
else if (!strcmp(media, "aui"))
lp->adapter_cnf = A_CNF_MEDIA_AUI | A_CNF_AUI;
else if (!strcmp(media, "bnc"))
lp->adapter_cnf = A_CNF_MEDIA_10B_2 | A_CNF_10B_2;
else
lp->adapter_cnf = A_CNF_MEDIA_10B_T | A_CNF_10B_T;
if (duplex==-1)
lp->auto_neg_cnf = AUTO_NEG_ENABLE;
if (io == 0) {
printk(KERN_ERR "cs89x0.c: Module autoprobing not allowed.\n");
printk(KERN_ERR "cs89x0.c: Append io=0xNNN\n");
ret = -EPERM;
goto out;
} else if (io <= 0x1ff) {
ret = -ENXIO;
goto out;
}
#if ALLOW_DMA
if (use_dma && dmasize != 16 && dmasize != 64) {
printk(KERN_ERR "cs89x0.c: dma size must be either 16K or 64K, not %dK\n", dmasize);
ret = -EPERM;
goto out;
}
#endif
ret = cs89x0_probe1(dev, io, 1);
if (ret)
goto out;
dev_cs89x0 = dev;
return 0;
out:
#if defined(CONFIG_ARCH_S3C2410)
iounmap(dev->base_addr);
/* 恢复寄存器原来的值 */
*((volatile unsigned int *)S3C2410_BWSCON) = oldval_bwscon;
*((volatile unsigned int *)S3C2410_BANKCON3) = oldval_bankcon3;
#endif
free_netdev(dev);
return ret;
}
入口函数里,首先分配了net_device 结构体,然后对该结构体进行进行填充,最后调用cs89x0_probe1进行下一步处理。
cs89x0_probe1(struct net_device *dev, int ioaddr, int modular)
{
......
.......
dev->open = net_open;
dev->stop = net_close;
dev->tx_timeout = net_timeout;
dev->watchdog_timeo = HZ;
**dev->hard_start_xmit = net_send_packet;**
dev->get_stats = net_get_stats;
dev->set_multicast_list = set_multicast_list;
dev->set_mac_address = set_mac_address;
.....
.....
retval = register_netdev(dev);
}
cs89x0_probe1里又进一步对net_device 进行了填充,其中hard_start_xmit 就是发送数据函数,然后通过register_netdev进行注册。
进一步查看net_send_packet
static int net_send_packet(struct sk_buff *skb, struct net_device *dev)
{
struct net_local *lp = netdev_priv(dev);
if (net_debug > 3) {
printk("%s: sent %d byte packet of type %x\n",
dev->name, skb->len,
(skb->data[ETH_ALEN+ETH_ALEN] << 8) | skb->data[ETH_ALEN+ETH_ALEN+1]);
}
/* keep the upload from being interrupted, since we
ask the chip to start transmitting before the
whole packet has been completely uploaded. */
spin_lock_irq(&lp->lock);
netif_stop_queue(dev);
/* initiate a transmit sequence */
writeword(dev->base_addr, TX_CMD_PORT, lp->send_cmd);
writeword(dev->base_addr, TX_LEN_PORT, skb->len);
/* Test to see if the chip has allocated memory for the packet */
if ((readreg(dev, PP_BusST) & READY_FOR_TX_NOW) == 0) {
/*
* Gasp! It hasn't. But that shouldn't happen since
* we're waiting for TxOk, so return 1 and requeue this packet.
*/
spin_unlock_irq(&lp->lock);
if (net_debug) printk("cs89x0: Tx buffer not free!\n");
return 1;
}
/* Write the contents of the packet */
writewords(dev->base_addr, TX_FRAME_PORT,skb->data,(skb->len+1) >>1);
spin_unlock_irq(&lp->lock);
lp->stats.tx_bytes += skb->len;
dev->trans_start = jiffies;
dev_kfree_skb (skb);
/*
* We DO NOT call netif_wake_queue() here.
* We also DO NOT call netif_start_queue().
*
* Either of these would cause another bottom half run through
* net_send_packet() before this packet has fully gone out. That causes
* us to hit the "Gasp!" above and the send is rescheduled. it runs like
* a dog. We just return and wait for the Tx completion interrupt handler
* to restart the netdevice layer
*/
return 0;
}
net_send_packet里用到了sk_buff 这个结构体,sk_buff 就是数据的载体,net_send_packet里通过sk_buff 发送了数据,那数据又是如何接受的呢,其实是通过中断接受数据的,net_interrupt处理如下:
static irqreturn_t net_interrupt(int irq, void *dev_id)
{
struct net_device *dev = dev_id;
struct net_local *lp;
int ioaddr, status;
int handled = 0;
ioaddr = dev->base_addr;
lp = netdev_priv(dev);
/* we MUST read all the events out of the ISQ, otherwise we'll never
get interrupted again. As a consequence, we can't have any limit
on the number of times we loop in the interrupt handler. The
hardware guarantees that eventually we'll run out of events. Of
course, if you're on a slow machine, and packets are arriving
faster than you can read them off, you're screwed. Hasta la
vista, baby! */
while ((status = readword(dev->base_addr, ISQ_PORT))) {
if (net_debug > 4)printk("%s: event=%04x\n", dev->name, status);
handled = 1;
switch(status & ISQ_EVENT_MASK) {
case ISQ_RECEIVER_EVENT:
/* Got a packet(s). */
net_rx(dev);
break;
case ISQ_TRANSMITTER_EVENT:
lp->stats.tx_packets++;
netif_wake_queue(dev); /* Inform upper layers. */
if ((status & ( TX_OK |
TX_LOST_CRS |
TX_SQE_ERROR |
TX_LATE_COL |
TX_16_COL)) != TX_OK) {
if ((status & TX_OK) == 0) lp->stats.tx_errors++;
if (status & TX_LOST_CRS) lp->stats.tx_carrier_errors++;
if (status & TX_SQE_ERROR) lp->stats.tx_heartbeat_errors++;
if (status & TX_LATE_COL) lp->stats.tx_window_errors++;
if (status & TX_16_COL) lp->stats.tx_aborted_errors++;
}
break;
case ISQ_BUFFER_EVENT:
if (status & READY_FOR_TX) {
/* we tried to transmit a packet earlier,
but inexplicably ran out of buffers.
That shouldn't happen since we only ever
load one packet. Shrug. Do the right
thing anyway. */
netif_wake_queue(dev); /* Inform upper layers. */
}
if (status & TX_UNDERRUN) {
if (net_debug > 0) printk("%s: transmit underrun\n", dev->name);
lp->send_underrun++;
if (lp->send_underrun == 3) lp->send_cmd = TX_AFTER_381;
else if (lp->send_underrun == 6) lp->send_cmd = TX_AFTER_ALL;
/* transmit cycle is done, although
frame wasn't transmitted - this
avoids having to wait for the upper
layers to timeout on us, in the
event of a tx underrun */
netif_wake_queue(dev); /* Inform upper layers. */
}
#if ALLOW_DMA
if (lp->use_dma && (status & RX_DMA)) {
int count = readreg(dev, PP_DmaFrameCnt);
while(count) {
if (net_debug > 5)
printk("%s: receiving %d DMA frames\n", dev->name, count);
if (net_debug > 2 && count >1)
printk("%s: receiving %d DMA frames\n", dev->name, count);
dma_rx(dev);
if (--count == 0)
count = readreg(dev, PP_DmaFrameCnt);
if (net_debug > 2 && count > 0)
printk("%s: continuing with %d DMA frames\n", dev->name, count);
}
}
#endif
break;
case ISQ_RX_MISS_EVENT:
lp->stats.rx_missed_errors += (status >>6);
break;
case ISQ_TX_COL_EVENT:
lp->stats.collisions += (status >>6);
break;
}
}
return IRQ_RETVAL(handled);
}
net_interrupt里又调用net_rx(dev);进行处理
net_rx(struct net_device *dev)
{
struct net_local *lp = netdev_priv(dev);
struct sk_buff *skb;
int status, length;
int ioaddr = dev->base_addr;
status = readword(ioaddr, RX_FRAME_PORT);
length = readword(ioaddr, RX_FRAME_PORT);
if ((status & RX_OK) == 0) {
count_rx_errors(status, lp);
return;
}
/* Malloc up new buffer. */
skb = dev_alloc_skb(length + 2);
if (skb == NULL) {
#if 0 /* Again, this seems a cruel thing to do */
printk(KERN_WARNING "%s: Memory squeeze, dropping packet.\n", dev->name);
#endif
lp->stats.rx_dropped++;
return;
}
skb_reserve(skb, 2); /* longword align L3 header */
readwords(ioaddr, RX_FRAME_PORT, skb_put(skb, length), length >> 1);
if (length & 1)
skb->data[length-1] = readword(ioaddr, RX_FRAME_PORT);
if (net_debug > 3) {
printk( "%s: received %d byte packet of type %x\n",
dev->name, length,
(skb->data[ETH_ALEN+ETH_ALEN] << 8) | skb->data[ETH_ALEN+ETH_ALEN+1]);
}
skb->protocol=eth_type_trans(skb,dev);
netif_rx(skb);
dev->last_rx = jiffies;
lp->stats.rx_packets++;
lp->stats.rx_bytes += length;
}
net_rx里也会构造一个sk_buff 结构体,然后调用netif_rx(skb);进行发包。
总结:发送数据和接受数据是通过hard_start_xmit 和netif_rx完成的,而数据的载体都是sk_buff 结构体。