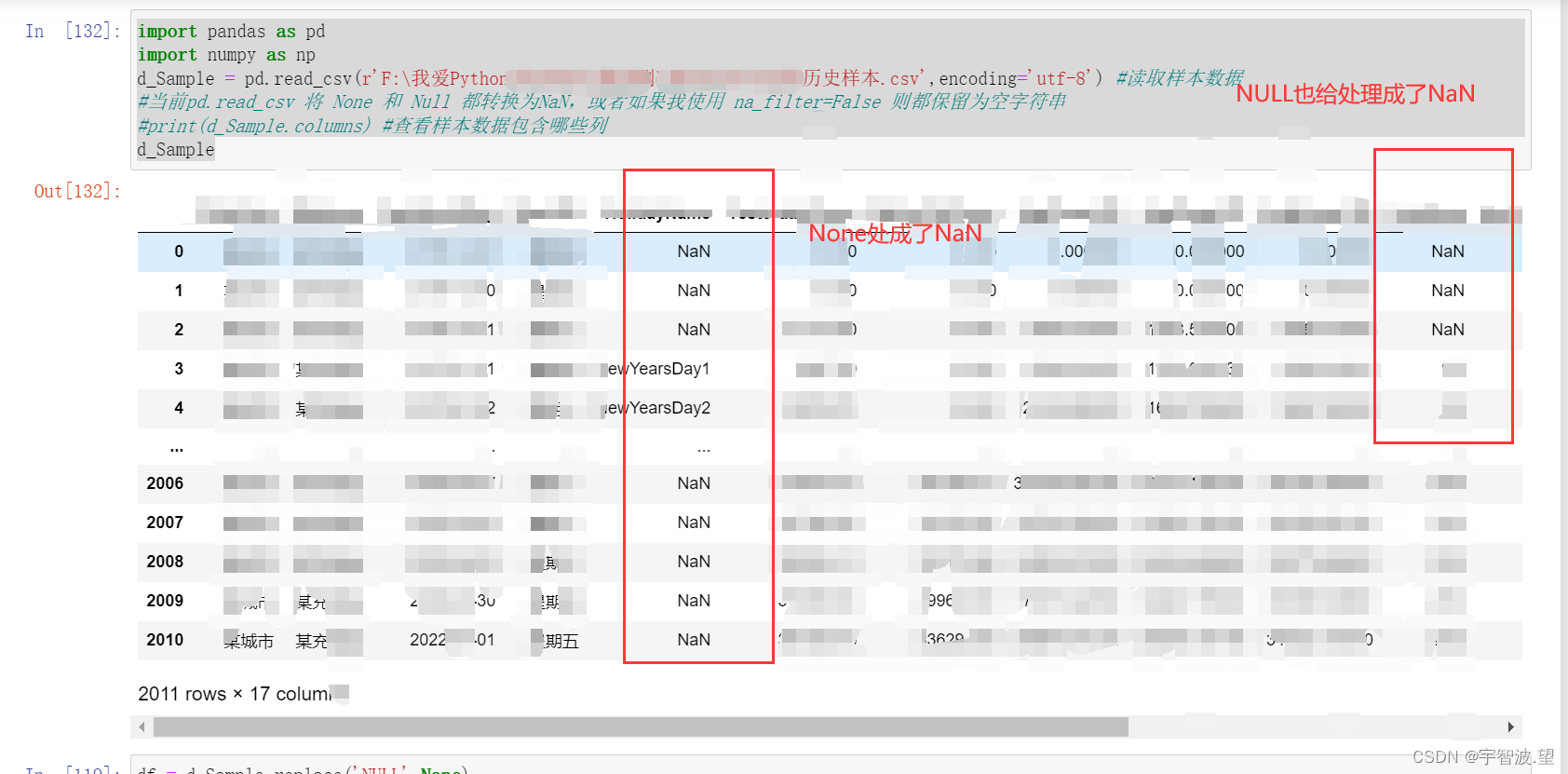
近期,使用read_csv的时候,遇到一个问题,就是本地读取的csv文件中的数据有None和NaN 两种,如:

直接使用
pd.read_csv(r'F:\我爱Python\预测\历史样本.csv',encoding='utf-8')
发现读取的数据是将None 和 NULL 直接处理成 NaN 了,也就是被识别成空了。
然后使用 dropna(),发现会将Excel中包含None、NaN的行都给删除了,但这不是我想要的结果,我只想删除含有Null的!!
ata = df.dropna(axis=0,how='any')#把包含为空的行数据删除
#axis=0 表示删除包含空值的行,即沿着行的方向删除; how='any' 表示只要有一个空值就要删除包含该空值的行。
print(len(data))
data
于是找到了两种处理方法:
方法一:
对None的列进行处理,将空值转化成字符’',或是其他不影响的字符,再使用 dropna(),即可。
df = d_Sample
df[‘HolidayName’] = df[‘HolidayName’].fillna(‘None’)
df
方法二:
在使用read_csv(),的时候,将参数 na_filter=False 加上,即:
import pandas as pd
import numpy as np
#读取样本数据
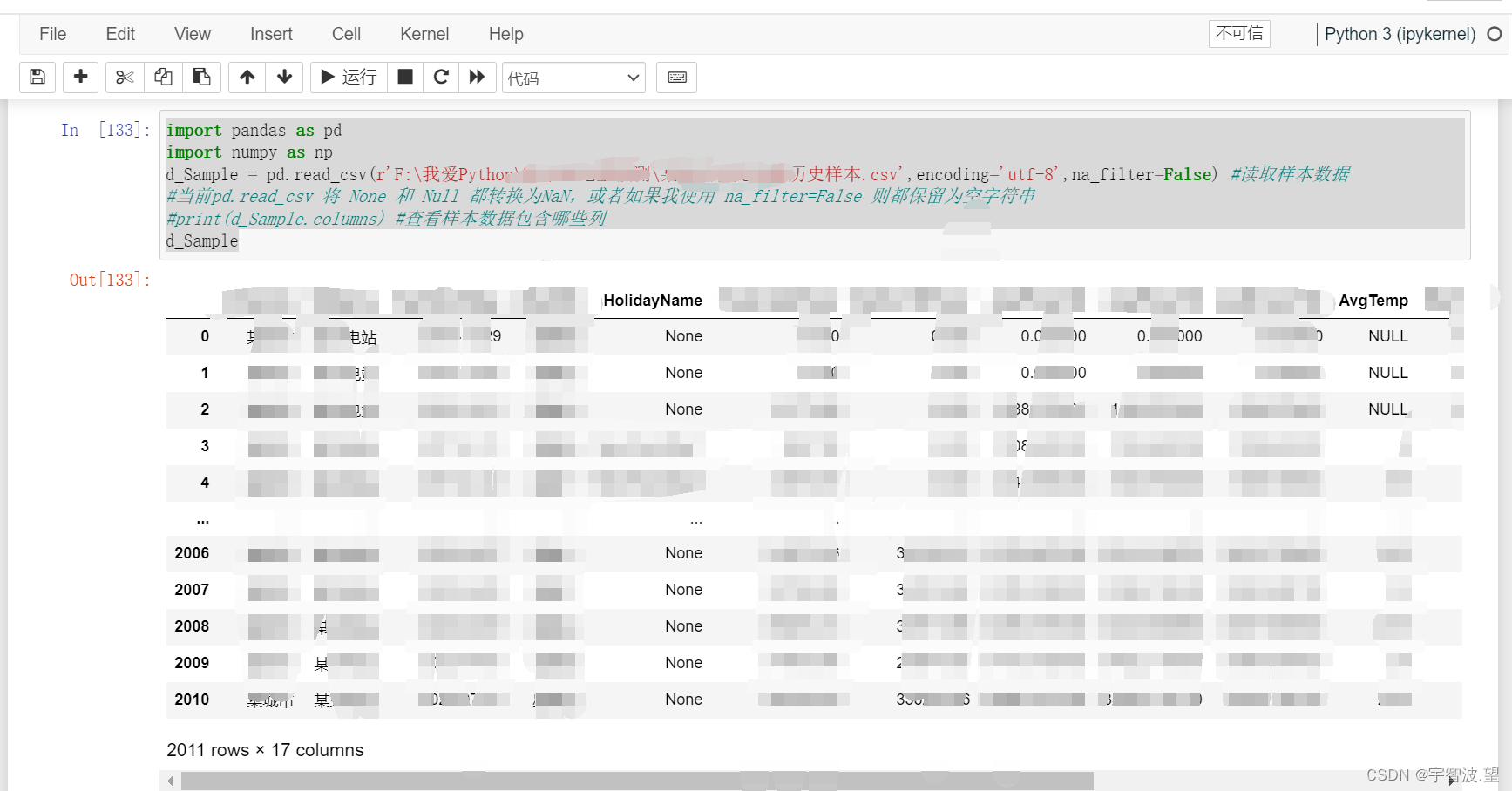
d_Sample = pd.read_csv(r'F:\我爱Python\预测\某历史样本.csv',encoding='utf-8',na_filter=False)
#使用 na_filter=False 则都保留为空字符串
#print(d_Sample.columns) #查看样本数据包含哪些列
d_Sample
这样结果就会是和Excel一致的,不会将None,NULL,给处理成NaN,即:
之后再将NULL处理成空,将None处理成"小可爱"即可,再使用 dropna(),即可:
df = d_Sample.replace('NULL',None)
df = df.replace('None','小可爱')
#df['HolidayName'] = df['HolidayName'].replace('NULL',None)
df
data = df.dropna(axis=0,how='any')#把全部为空的行数据删除
#axis=0 表示删除包含空值的行,即沿着行的方向删除; how='any' 表示只要有一个空值就要删除包含该空值的行。
print(len(data))
data






![浅谈小程序开发 [2018年]](https://img-blog.csdnimg.cn/85d0dfb005134061919658beb0786db7.png)