交换机是否会梦见机器学习?面向网络内分类
摘要
机器学习目前正在推动技术和社会革命。虽然可编程交换机已被证明对网络内计算非常有用,但是在可编程交换机内进行机器学习迄今为止取得了很少的成功。不利用网络设备进行机器学习会付出高昂的代价,因为在网络内进行处理已知具有高能效和性能优势。在本文中,我们探讨了使用通用可编程交换机进行网络内分类的潜力,通过将经过训练的机器学习模型映射到匹配-动作流水线。我们引入了基于软件和硬件的原型IIsy,讨论了映射到不同目标的适用性。我们的解决方案可以推广到其他机器学习算法,使用本文中介绍的方法。
ACM参考文献格式: Zhaoqi Xiong和Noa Zilberman。2019。Do Switches Dream of Machine Learning? Toward In-Network Classification. 在ACM Workshop on Hot Topics in Networks (HotNets '19)中,于2019年11月13日至15日,美国新泽西州普林斯顿举行。ACM,美国纽约,9页。https://doi.org/10.1145/3365609.3365864
1. 介绍
机器学习(ML)越来越多地主导着我们日常生活的数字方面,从个性化在线购物,到社交网络、金融和交易。系统社区正在努力满足ML的需求,同时面临越来越多的障碍:从摩尔定律的终结[33, 39]和丹纳德缩放[19]到内存和成本限制[42]。这些挑战推动了ML硬件设计的创新,包括CPU优化(例如[6, 53]),GPU(例如[14])和FPGA(例如[18, 21, 51])解决方案,以及专用处理ASIC[12, 26]。所有形式的ML加速都受到了极大的关注。
网络也没有逃脱ML的趋势,ML被用于优化和决策制定(例如[13, 23, 52])。随着可编程网络设备的兴起,人们本以为网络内的ML将得到广泛应用。网络内计算不仅展示了出色的性能[24, 25],而且具有高能效[50]。然而,网络内的ML仍然未能在网络社区中得到广泛应用。的确,已经证明网络设备可用于改善分布式ML,例如通过网络内聚合[45],但这并不是在网络设备内实现ML的方式。可能对网络内推断的第一步是在N2Net[47]和BaNaNa Split[43]中,它们讨论了在可编程网络设备内实现神经网络的方式。
在本文中,我们关注以下问题:在ML训练已经进行的情况下,我们是否可以将训练好的模型部署到可编程网络设备中?通过这样做,我们专注于ML的一个具体方面,即分类。我们集中精力研究非基于神经网络的ML推理分类,并展示了经过训练的数据包分类模型无缝映射到可编程数据平面。这种映射实现了流速下的流量分类,并在有限资源、流速和分类准确性之间找到了平衡。此外,我们还展示了只要特征集是静态的,就可以通过仅通过控制平面部署对分类模型的更新,而不需要更改数据平面。
在本文中,我们的贡献如下:
• 我们展示了将四种不同的经过训练的机器学习算法映射到匹配-动作流水线的方法。
• 我们介绍了基于软件和硬件的原型框架,该框架可以自动将经过训练的模型映射到匹配-动作流水线。
• 我们展示了在硬件目标中的网络内分类,并量化了资源需求。
我们的工作范围有限。我们没有探索所有的ML算法,甚至不是最流行的算法,例如神经网络超出了本文的范围。我们不声称在ML算法方面有任何贡献。此外,我们的方法在精度和提取特征类型方面有设计上的限制。我们相信我们的分类贡献是在网络设备内实现更复杂、专用推断的第一步。我们的代码可以在[57]上获得。
1.1 动机
在网络设备内部运行机器学习(ML),即在网络设备内部运行ML,是一个令人兴奋的前景,有多个原因支持这一点。首先,交换机具有非常高的性能。通过交换机的延迟大约为每个数据包几百纳秒[3],而高端ML加速器的推理延迟在几十微秒到毫秒的范围内[26, 36]。相同的加速器实现了10-90 TOPS/秒[26],而16 Tb/秒的交换机支持大约每秒处理一百五十亿个数据包[31]。然而,OPS/秒并不能直接映射到数据包速率,例如,NVidia Tesla V100每秒可以推理10,000个图像[36],而可以通过交换机以每秒超过10,000,000个图像的速率传输相同的图像数据集。网络交换机的功率效率使其能够每瓦处理成千上万的数据包[50],比大多数加速器更好,可编程交换机[3]的绝对功耗低于当今的替代品[26]。
交换机还具有另一个优势:它们在某些ML用例中处于理想位置。分布式ML的性能受限于将数据传输到节点和从节点传输所需的时间。如果一个交换机能够以与将数据包传输到分布式系统中的节点的速率相同的速率进行分类,那么它将能够与任何单个节点相媲美甚至超越其性能。在数据中心之外,交换机具有进一步的优势。它们可以提前终止数据,减轻网络负载,并支持随时间的可扩展性。在边缘附近终止数据可以节省电力,减少对基础设施的负载,并通过减少延迟改善用户体验。最重要的是,交换机已经在网络中部署,并且不需要安装额外的硬件。只要一个交换机能够同时支持ML和网络操作,它将提供比通过ML加速器增强的系统更便宜的解决方案,并且将释放运行ML应用程序的CPU上的周期。
在这项工作中,我们仅关注分类任务。随着用户生成的数据量不断增加,网络成为我们对于庞大的数据规模的第一道防线,每年超过10个ZB [15]。预计随着物联网(IoT)的广泛应用,数据规模还将进一步膨胀,其中许多数据需要进行分类。虽然如今中间盒(middlebox)仍然可以满足边缘所需的处理量,但随着数据需求的增长,它们不太可能继续扩展。但是,如果我们能够在数据到达其处理目的地之前在网络内部运行分类,会怎么样呢?我们不仅可以减轻处理负载,还可以更早地对事件作出响应,在边缘附近终止流量。自动驾驶汽车和自动化工厂等应用是一些对延迟非常敏感的应用[46],将会从中受益。
也许最简单的网络内部分类示例是Mirai僵尸网络(Mirai Botnet),它使用嵌入式和物联网设备对选定的目标发动了拒绝服务攻击[2]。如果边缘设备基于基于ML推断的结果而不是使用“标准”访问控制列表来丢弃所有与Mirai相关的流量,是否可能在攻击初期停止攻击?我们在第6.3节和第7节进一步讨论用例。
2. 交换机作为分类机器
商品交换机自然而然地可以作为分类机器。以标准的二层以太网交换机为例,尽管任何交换机架构都适用,我们保持一个可编程数据平面的心理模型,例如P4[8]或NPL[35]所使用的模型。
当一个新的对象(数据包)到达时,第一步是从中提取相关的特征。在交换机中,这类似于解析数据包的头部。每个头部字段实际上都是一个特征,而头部解析器则是特征提取器。
分类过程的下一步是将对象的特征应用于经过训练的机器学习模型。对于二层以太网交换机,该模型采用非二进制决策树的形式,只有一层。根的分割特征是目标MAC地址。通过访问交换机中的MAC地址表,可以找到对象(数据包)的特征(目标MAC地址)对应的正确分支。一旦找到适当的分支,对象就被分配到一个类别,意味着数据包被分配到一个输出端口。我们在图1中说明了这种相似性。
一个二层以太网交换机也可以用更复杂的决策树表示。一个例子是检查源端口是否与目标端口相同,如果值相同,则丢弃该数据包。在决策树中,这将导致添加另一层和一个额外的类别(丢弃)。
交换机是否梦见机器学习?
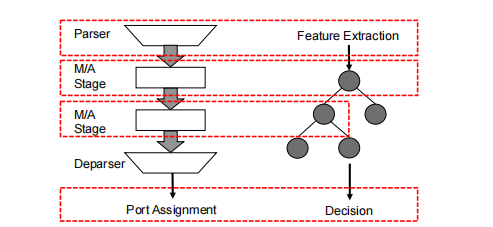
图1:一个决策树和一个简单的交换机管道之间的相似性。类似的组件被圈了起来。M/A表示匹配操作。管道的输出可以不仅仅是一个端口分配。
3. 关键观点
迄今为止,机器学习算法尚未在网络设备中得到实现的原因之一是所需的数学运算的实现复杂性。在交换机硬件中实现加法、异或或位移等操作很容易,但是乘法、多项式或对数等操作无法很好地进行流水线化处理,可能会增加延迟或影响吞吐量。然而,尽管交换机不支持loд(x)或loд(y)等操作,一旦已知loд(x)和loд(y),就可以轻松地进行loд(x × y)等操作。
我们不尝试在交换机内部实现数学运算。相反,我们借鉴了可编程硬件(例如FPGA)和高性能计算中的一种常见做法:使用查找表来存储计算结果或等效的结果。查找表完全符合可编程交换机所使用的匹配-动作范式。
实际上,实施并不像听起来那么容易。硬件交换机拥有有限的资源,无法存储无限大小的表来支持所有可能的值。我们在这项工作中采用的解决方案是不在表中存储任何潜在值,并愿意在可行性的代价上失去一些准确性。我们进一步通过存储分类结果或代码(§5)而不是计算结果来节省内存,从而更有效地使用三进制和最长前缀匹配(LPM)表。
第二个已经提到的观点是,交换机已经被设置为分类机器,解析器充当特征提取模块,而匹配-动作流水线则用于进行分类。
在许多交换机架构中,只有部分数据包经过可编程数据平面,其余部分被缓冲[8]。为了处理整个数据包,一种解决方案是数据包循环处理,将数据包(和特征)分割为头部大小的数据单元,并逐步通过流水线。这种方法会降低吞吐量,并需要调整以维护元数据,但在网络利用率较低或具有足够速度提升的情况下仍然可以表现良好。
4. 实际资源分配
到目前为止,我们已经讨论了将分类算法映射到匹配-动作流水线的关键观点。在本节中,我们采用了更加现实的方法来考虑商品交换机在网络中进行分类的限制。
首先,我们注意到交换机可能不仅仅进行分类,还包括重要的交换功能。因此,预计在我们将交换和其他交换机功能视为机器学习行为之前,大量资源将被基本的网络功能占用。
其次,上面介绍的所有网络内分类解决方案都具有一个重要特性:它们不需要任何外部依赖,也就是说不需要特定于目标的功能。这种纯匹配-动作实现使得在不同的目标之间进行移植成为可能,并且意味着解决方案不会被锁定在单一平台上。
我们观察到,现在的可编程交换机每个流水线支持12到20个阶段,每个设备有多个(例如四个)流水线[3, 34],这限制了支持的功能。表的内存可能在几百兆位的数量级上[9],可能分布在多个流水线之间。此外,解析器只能提取有限数量的头部,可能与流水线的深度相当,因此在某些分类实现中,特征的数量将与类别的数量相当。另一方面,特征的宽度可能相当大,例如IPv6地址宽度为128位。期望表的深度与键的宽度成比例是不现实的,而是与网络规模(对于交换机)或分类问题(对于网络内分类)成比例。
在实际应用中,使用多个特征作为表的键将不容易实现:硅供应商一直努力实现IPv6的128位地址的查找表,目前最先进的存储器深度仅达到300K-400K条目[4, 5],因此任何显著大于这个数量(例如,超过10倍)的情况都可以被认为是不现实的。然而,假设128位是一个可行的键宽度,就会打开重要的机会:由于TCP源端口和目标端口各占16位,标志通常只有几个位,以太网类型也是16位,多个特征可以连接成一个单一的键,而不需要达到IPv6地址的宽度。
我们避免对实施不同算法所需的资源量设置界限,因为这样的界限与现实几乎没有相似之处。例如,如果表的键宽度为w,那么表的深度将只有2^w,只有在表是直接映射的情况下,它才能作为简单的内存实现,并且只需要存储动作。使用精确匹配、最长前缀匹配和范围类型表旨在避免表深度的要求,但会导致增加表的宽度(键宽度加上动作宽度)。我们在第6.3节中进一步讨论这个问题。
增加在分类中使用的特征(或类别)的一种方法是将多个流水线连接起来,其中一个流水线的输出将作为下一个流水线的输入。这种方法将面临两个挑战。首先,它将使设备的最大吞吐量降低,降低因子为连接的流水线数量。其次,我们在各个阶段之间使用的元数据在流水线之间不共享[3],因此可能需要将信息嵌入中间头部。
5.从机器学习到匹配-动作
在这项工作中,我们采用了可编程数据平面的P4方法[8],假设通用的PISA或RMT [9]形式的流水线模型。我们探索了使用四种算法进行数据包分类,包括有监督和无监督学习:决策树、K均值、支持向量机(SVM)和朴素贝叶斯。选择这些算法是因为它们之间的差异,并且结果可以进行泛化。神经网络超出了本工作的范围。表1总结了我们的方法。
5.1 决策树
决策树可以直观地映射到匹配-动作流水线。在每个阶段,一组条件被应用于一个特征,它们的结果导致树的不同分支。由于条件是简单的操作,它们可以在P4中实现。然而,这种方法是浪费的,因为树的深度和条件定义了流水线中的阶段数。我们提出了一种不同的方法,更适合匹配-动作流水线:流水线中实现的阶段数等于使用的特征数加一。在每个阶段中,我们将一个特征与其所有可能的值进行匹配。结果(动作)被编码到元数据字段中,并指示树中选择的分支。流水线中的最后一个阶段从元数据总线中获取所有特征的编码字段,并将值映射(匹配)到结果叶节点。
决策树可以使用范围类型表[37]来实现,但这些表在许多硬件目标上不可用。如果特征值的数量是已知且有限的,可以使用精确匹配表来替代。另外,三值和最长前缀匹配(LPM)表可以用于将范围分成多个条目,从而增加资源消耗(与范围类型表相比),但提供了可行的使用路径。
5.2 支持向量机(SVM)
第二个有监督学习算法是支持向量机(SVM),它使用超平面来分离不同的类别。训练过程的输出采用多个方程的形式,其中每个方程表示一个超平面^5:
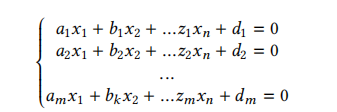
其中n是特征的数量,k是类别的数量,m = k * (k - 1) / 2。
一种实现SVM的方法(表1.2)是实现m个表,每个表专用于一个超平面,并指示给定输入在超平面的哪一侧。用于访问匹配-动作表的键是特征集合,并且为了避免复杂的操作,动作是“投票”。一个“投票”是一个映射到元数据总线的一位值,指示输入是否属于超平面内部或外部。一旦一个输入与所有m个表匹配,所有“投票”(跨类别的元数据总线之和)被计数,获得“投票”最多的类别是分类结果。
第二种方法(表1.3)是为每个特征专用一个表,表的输出是一个形如a1x1,a2x1,…amx1的向量。在匹配-动作流水线的末尾,计算每个超平面的值,即所有向量的总和,并做出决策。这种方法需要更小的表,但存在一些限制:生成向量中的值具有有限的精度(例如,不能表示浮点数),可能需要很多位。此外,在匹配-动作流水线的末尾可能需要进行重要的逻辑运算(求和操作)。
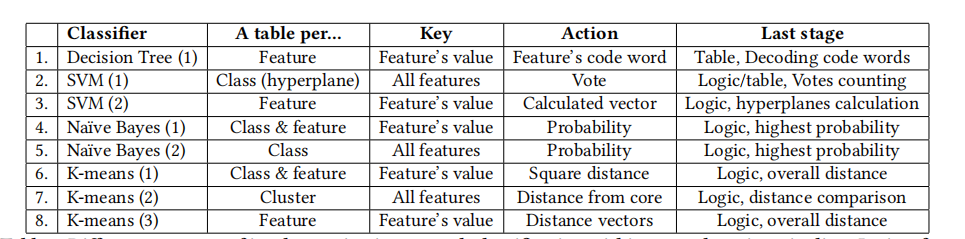
表1:在匹配动作管道中实现网络内分类的不同方式。逻辑仅指加法操作和条件。
5.3 朴素贝叶斯
我们对有监督的朴素贝叶斯分类器[30]进行探索,假设特征之间服从独立的高斯分布[20]。与网络流量分类可能更准确的相关方法,如核估计[32],将遵循类似的实现概念。在这个假设下,特征xi的似然性表示为:
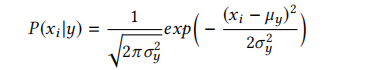
以及分类规则将是:
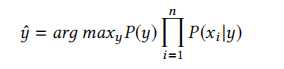
对于一个包含k个分类的问题,使用n个特征,有k×n个(µy,σy)对。一种朴素的实现方法(表1.4)将使用k×(n+1)个匹配-动作表,用于计算k个分类的n个概率,以及该类别的所有n个计算概率的乘积。这个过程不仅浪费资源,而且在概率值较小时难以在硬件中近似计算。
第二种方法(表1.5)使用每个类别一个表,所有特征作为键。返回的不是浮点值作为分类的概率,而是代表概率的整数值。只要在表(不同的分类)中使用相似的值来表示概率,这种方法可以产生准确的结果。不足之处在于所需表的大小:它使用了非常宽的键(将所有输入特征值连接起来),其深度与这个宽度成比例。
5.4 K-means
K-means聚类是无监督学习的一个例子。对于k个类别,它提供了k个聚类中心,每个聚类中心由n个坐标值组成,每个坐标值对应一个特征。给定输入x到聚类i的中心的距离计算如下:
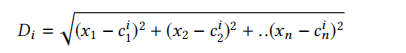
其中x1到xn是特征的值。输入将被分类到具有最小距离的聚类。
为了基于最短距离选择聚类,只考虑平方距离即可。一种选择是使用每个聚类一个表的方法(表1.7),表的键是所有特征。与每个坐标一个表的方法相比(表1.6),这种方法需要更少的表,但使用更深更宽的表。另一种方法(表1.8)是使用每个特征一个表,它的动作将一组距离值分配给元数据总线的单个轴,每个聚类一个值。在这种方法中,最后一个阶段同时累加距离向量并分类到最小距离的聚类。
可行性:根据第4节和表1,我们对实际交换机的理解显示了每种实现方法的可行性和限制。实现 4 6 4^6 46(朴素贝叶斯)和6(K-means)都非常有限。即使在一个专门用于分类的数据平面中,使用超过4-5个特征和4-5个类别是不切实际的,会超过可用的阶段数量,或者反过来,使用2个类别和10个特征(反之亦然)。其他方法提供了更大的灵活性:支持多达20个类别或特征。分类器1(决策树)、3(支持向量机)和8(K-means)具有最佳的可扩展性,可以通过表的数量、键的宽度和动作的宽度的组合来实现。
6 原型和评估
我们实现了名为IIsy(简化网络中推理)的原型,作为我们观察的验证。我们的框架包括基于软件的实现,展示了将分类算法自动映射到网络设备的能力,以及基于硬件的实现,探索资源需求和性能。
IIsy包括三个组件。第一,是一个机器学习训练环境。第二,是网络设备内的可编程数据平面。第三,是用于将训练好的算法映射到网络设备的控制平面。该框架如图2所示。
我们使用Scikit-learn [40]作为训练环境。虽然训练的输入可以是任何数据集,但我们使用带标签的数据包跟踪作为输入,以展示真实的流量场景。选择Scikit-learn是为了易用性,并可以用其他训练环境替代,只要它们的输出可以转换为与我们的控制平面匹配的文本格式。
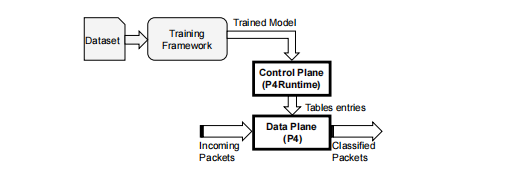
图2:IIsy的高级体系结构。IIsy的组件是白色的。外部部件为灰色
6.1 基于软件的原型
我们的基于软件的原型使用P4在v1model架构中实现了数据平面。控制平面使用了P4Runtime [38]。我们使用bmv2和mininet进行测试。我们为每个用例编写一个P4程序。一个用例指的是一对参数:使用的机器学习算法和预期的网络流量。网络流量决定了数据平面解析器的设计(即需要解析哪些报头),而机器学习算法定义了需要实现的匹配-动作设计。
我们使用Python脚本生成控制平面。我们将机器学习训练阶段的输出转换为对匹配-动作流水线的表写操作,使用P4runtime。尽管这个阶段很简单,但它是最重要的阶段:它使我们能够更改网络设备的操作,并在不更改P4程序的情况下实现不同的分类规则,只要机器学习模型的类型和使用的特征集不改变即可。
6.2 基于硬件的原型
IIsy的硬件原型是在NetFPGA SUME [59]上使用P4→NetFPGA工作流程 [22]进行实现的。目前,P4→NetFPGA不支持P4runtime,我们使用P4→NetFPGA控制平面接口来实现控制平面配置。我们的硬件实现主要探索了移植到硬件目标的可行性和分类速率。我们使用的P4程序与基于软件的原型非常相似,但在硬件目标方面进行了轻微的修改:范围类型表被精确匹配或三值表替代,并且语法根据P4→NetFPGA工作流程的要求进行了调整。与我们的软件实现的另一个区别是,P4→NetFPGA使用的体系结构是SimpleSumeSwitch [22]。
对于性能评估,我们使用OSNT,一个用于以线速(4×10G)生成流量和测量延迟的开源网络测试工具 [1]。由于OSNT可以重放有限大小的数据包跟踪,因此使用tcpreplay在标准的X520网卡上进行功能测试以使用大型跟踪文件。
6.3 示例:物联网流量
物联网是网络中分类的驱动应用场景,如第1节所述。我们使用Sivanathan等人发布的物联网设备的pcap跟踪作为我们的数据集[48]。我们的目标是使用IIsy根据设备类型对传入流量进行分类。我们将被监控的设备分为五个类别:静态智能家居设备(例如电源插座)、传感器(例如气象传感器)、音频(例如智能助手)、视频(例如安全摄像头)和“其他”。我们选择了可以映射到不同服务质量组的类别:从高带宽(视频)到最佳努力(“其他”类)。我们选择了11个特征进行评估,例如EtherType、IP协议和标志位以及TCP端口。所有特征直接从数据包的头部提取。我们没有使用识别信息,如MAC或IP地址,这样既可以避免结果偏差(因为设备具有固定地址),又可以展示基于地址的匹配-动作实践之外的分类部署能力。
表2总结了数据集的属性。对于其中六个特征,在数据集中只存在很少数量的值,这意味着非常小的表,甚至寄存器可能足以保存它们的计算值。保存数据包大小的表仍将适合标准查找表 [56] 中。对于TCP和UDP端口号,使用精确匹配表是可行的,但在FPGA目标上成本很高:每个这样的表将消耗接近2Mb的内存 [56],并且可能无法满足时序约束。因此,我们使用三值表,允许在值范围内进行匹配。
我们选择了11个特征,适用于像Barefoot Tofino这样的设备,其中每个特征都使用一个表,并且有一个决策表,与流水线中的阶段数相等 [3, 34]。我们期望未来的工作能够探索更复杂的特征,以及更多的特征数量(见第7节),并且在NetFPGA平台上实现的可行性。优化规则与表的匹配是本文讨论之外的内容,并且已经进行了广泛研究(例如[10, 11, 27])。
我们使用Scikit-learn对模型进行训练,并获得模型的统计数据。我们根据端口映射验证分类。我们的目标是交换机的分类输出与模型的分类结果相匹配。
我们在IIsy中实现了所有四个模型,每个模型采用一种方法,并评估功能和资源消耗。我们的性能测试衡量吞吐量和延迟,并且仅针对决策树实现进行了测试。
表3提供了在NetFPGA平台 [59] 上实现这些模型所需的资源概述。利用率数据是指使用在该板上使用的Virtex-7 690T FPGA之间的相对比较。我们使用64个条目的小表,除了最后一个(决策)表,它使用精确匹配,并设置为可能的选项数。512个条目的表适合于FPGA,但无法在200MHz下满足时序。
对小型表的研究提供了有趣的见解。例如,对于决策树,每个特征需要2到7个匹配范围,而这些范围适合于不超过47个条目的表中,相对于64K个潜在值(例如TCP端口)来说,这是一个显著的节省。相反,将多个特征作为表的键来使用的模型更难映射到表条目,并且需要对特征之间的位进行重新排序(首先交错最高有效位,然后交错最低有效位),以实现跨范围的匹配。正如可以预料的,64个条目不足以进行无损匹配。
最准确的实现使用决策树。深度为11的训练模型的准确率达到0.94,精确率、召回率和F1分数也类似。降低决策树深度会使预测的准确率每级下降1%-2%。在NetFPGA上,我们实现了一个只有五个级别的流水线,准确率和F1分数约为0.85。因此,只需要五个特征。值得提醒的是,我们的目标不是找到最佳的流量分类模型,而是进行与训练模型一样准确的分类。我们通过回放数据集的pcap跟踪并检查数据包是否到达分类预期的端口来评估实现的准确性。我们的分类结果与训练模型的预测完全一致。我们还使用OSNT评估了实现的性能,并验证了我们达到了全线速的要求。我们的设计的延迟(与工具链版本有关)为2.62µs(±30ns),与具有类似阶段数的参考(非机器学习)P4→NetFPGA设计相当。
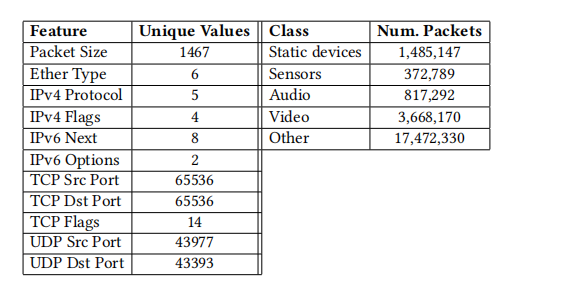
表2:物联网训练数据集的所选属性
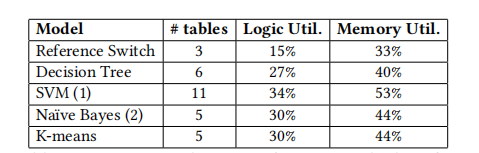
表3:NetFPGA-SUME上网络内分类实现的资源利用率。
7 讨论
网络内计算:网络内分类是网络内计算的一种形式。虽然在这项工作中,我们认为网络内计算是理所当然的,遵循一些知名的工作(例如[24, 25, 44]),但这个研究领域仍然被认为是具有争议和不成熟的 [7, 41]。一个重要的挑战是,网络内计算会消耗其他网络目的所需的资源。将交换机作为网络附加加速器,可以保持吞吐量的优势而不共享资源,但需要消耗几乎为零的功耗和空间,而这些在作为数据包的网络遍历的一部分进行计算时几乎是免费的。
特征提取:在我们的原型中,我们主要使用了从数据包头部提取的特征。类似地,可以提取诸如缓存查询 [50] 或DNS请求 [55] 等特征。诸如队列大小之类的特征可能通过流水线的元数据总线可用,但这些特征与体系结构有关。提取需要状态的特征,例如流大小,是可能的 [29, 49],但需要使用计数器或外部组件,并且可能是特定于目标的。许多机器学习模型需要复杂的特征,在交换机上可能无法提取这些特征。
性能和可扩展性:我们的实现只使用匹配-动作表,而没有复杂的操作。因此,在硬件目标上,IIsy的性能将类似于平台的数据包处理速率。尽管IIsy可以通过吞吐量进行扩展,但它可能无法随着特征数量或每个特征的取值进行扩展。这是一个在硬件目标之间变化的属性(§4)。我们提供的解决方案在资源上以分类的准确性为代价,预计准确性较低的类别会被标记为需要主机进一步处理,类似于 [54]。
交换机ASIC:将IIsy移植到商用交换机是未来的工作。与交换机供应商的讨论表明,这是可行的,并且可能实现线速性能。
应用场景:IIsy最期望的应用场景是与网络流量相关的,例如流量分类 [32],因为IIsy提供了一种处理流量容量可扩展性挑战的手段 [16]。相关的应用场景包括流量过滤和分布式拒绝服务攻击的缓解。拥塞控制是另一个可能的应用场景,某些硬件目标上可用的特征(如队列大小)可以用于拥塞控制。
8 相关工作和结论
近年来,机器学习(ML)和网络领域的研究取得了飞速发展。这些研究涉及网络流量分类 [17, 32, 58]、使用ML进行调度和拥塞控制 [23, 52] 等方面。ML框架正在使用网络设备进行加速 [18, 44],可以作为参数服务器或用于聚合和组播流量 [28, 45]。
在网络设备内实现推断仍处于起步阶段。N2Net [47] 和BaNaNa Split [43] 已经展示了在网络设备内实现二值神经网络,并分析了处理和通信开销。Li [28] 提出了在交换机内实现强化学习的方法,但使用了自定义加速模块。本文与这些工作是互补的,讨论了非神经网络的ML算法。
在本文中,我们介绍了名为IIsy的网络内分类框架。我们将监督学习和无监督学习的算法映射到了匹配-动作流水线,并讨论了这些实现的适用性。我们的原型实现了软件和硬件两种版本,并能以全线速对真实世界的数据包进行分类。这只是在网络设备内实现ML的第一步,下一个重要挑战是实现网络内训练。




![[mmcv系列] pip安装mmcv记录](https://img-blog.csdnimg.cn/39c99d86c5664d0db73536fb335494ab.png)