- 作者:Mohamed Elnoor
1
^{1}
1, Kasun Weerakoon
1
^{1}
1, Gershom Seneviratne
1
^{1}
1, Jing Liang
2
^{2}
2, Vignesh Rajagopal
3
^{3}
3,
and Dinesh Manocha 1 , 2 ^{1,2} 1,2 - 单位: 1 ^{1} 1马里兰大学帕克分校电气与计算机工程系, 2 ^{2} 2美国马里兰大学帕克分校计算机科学系, 3 ^{3} 3马里兰大学帕克分校James Clark工程学院
- 论文标题:Vi-LAD: Vision-Language Attention Distillation for Socially-Aware Robot Navigation in Dynamic Environments
- 论文链接:https://arxiv.org/pdf/250-09820
- 项目主页:https://gamma.umd.edu/researchdirections/crowdmultiagent/vilad/
主要贡献
-
视觉-语言注意力蒸馏:通过从大型视觉-语言模型(VLM)中提取注意力信息,并将其蒸馏到一个轻量级模型中,以实现实时导航。
-
社会引导的注意力微调:使用结构相似性指数(SSIM)损失来对齐注意力图,以提高模型对社会行为的理解和响应能力。
-
模型预测控制集成:结合MPC进行局部运动规划,确保机器人在导航时遵循社会规范并保持平滑的运动轨迹。
-
性能提升:在现实世界实验中,Vi-LAD在成功率上显著优于现有方法,显示出更高的成功率和更接近人类操作的轨迹。
研究背景
研究问题
- 传统的导航方法主要关注碰撞避免和几何路径规划,往往将人类视为静态或移动障碍物,而不是具有社会期望的交互智能体。
- 论文主要解决的问题是如何在动态环境中实现机器人导航,使其能够安全、高效且符合社会规范。
研究难点
该问题的研究难点包括:
- 动态环境的不确定性、
- 人类行为的复杂性和多样性、
- 以及大规模预训练模型的高计算需求和实时推理的延迟。
相关工作
动态场景中的机器人导航
- 经典导航方法:这些方法依赖于优化驱动和基于规则的策略,如模型预测控制(MPC)和速度障碍(VO)方法。它们主要用于静态障碍物避障,但在处理复杂的人类行为时缺乏适应性。
- 基于学习的导航方法:这些方法利用数据驱动的模型来提高适应性。模仿学习(IL)允许机器人模仿专家演示,而强化学习(RL)和逆向强化学习(IRL)则通过与环境互动来学习最优导航策略。然而,这些方法在现实应用中面临挑战,如数据质量和多样性限制、模拟到现实的迁移问题等。
大型模型在导航中的应用
- 大型预训练模型(LPMs):包括大型语言模型(LLMs)和视觉-语言模型(VLMs),这些模型在机器人感知、规划和导航方面表现出色。VLMs在语义分割和物体识别中广泛应用,支持基于自然语言的导航任务。
- VLMs的应用:VLMs在动态环境中的应用包括路径生成、场景理解和社会行为预测。尽管VLMs在理解社会规范和预测人类运动方面表现出色,但其计算需求高,限制了在资源受限机器人上的实时部署。
知识蒸馏
- 知识蒸馏技术:通过将大型、计算密集型的教师模型的知识转移到小型、高效的模型中,以促进在资源受限系统中的实时推理。
- 在机器人导航中的应用:知识蒸馏用于在机器人导航中传递高级推理能力,如语义场景理解和人类行为预测,而无需承担显著的计算成本。现有技术通常忽略了将社会推理整合到导航策略中。
背景
设置与约定
- 机器人设置:假设机器人是一个地面机器人,配备了一个RGB摄像头和一个IMU(惯性测量单元)。摄像头的坐标系以机器人的质心为中心,X轴指向前进方向,Y轴指向左侧,Z轴指向上方。
- 输入和输出:机器人接收来自RGB摄像头的图像和来自IMU的方向及运动反馈。机器人使用相同的控制器架构,接收线速度和角速度命令。
预训练模型
- 视觉特征提取:预训练模型用于提取视觉特征,帮助机器人导航。传统的模型(如ImageNet训练的模型)主要关注物体检测,而不是导航所需的特定线索(如路径、障碍物和人类运动)。
- 自监督学习:自监督学习(SSL)方法通过自我监督的方式学习特征,但许多方法需要大规模数据或缺乏泛化能力。
- VANP模型:论文采用了一个名为VANP的自监督视觉-动作模型。该模型通过将视觉观察与动作轨迹对齐来提取导航相关的特征。具体来说,VANP处理一系列过去的图像,并生成一个注意力图,突出显示对导航至关重要的区域。这个过程可以表示为:
A pretrained = F pretrained ( I RGB , t − n , … , I RGB , t ) \mathcal{A}_{\text{pretrained}} = \mathcal{F}_{\text{pretrained}}(I_{\text{RGB},t-n}, \ldots, I_{\text{RGB},t}) Apretrained=Fpretrained(IRGB,t−n,…,IRGB,t)
其中, F pretrained \mathcal{F}_{\text{pretrained}} Fpretrained 表示预训练模型, I RGB , t − n , … , I RGB , t I_{\text{RGB}, t-n}, \ldots, I_{\text{RGB}, t} IRGB,t−n,…,IRGB,t 表示作为输入的一系列过去RGB图像。
Vi-LAD方法
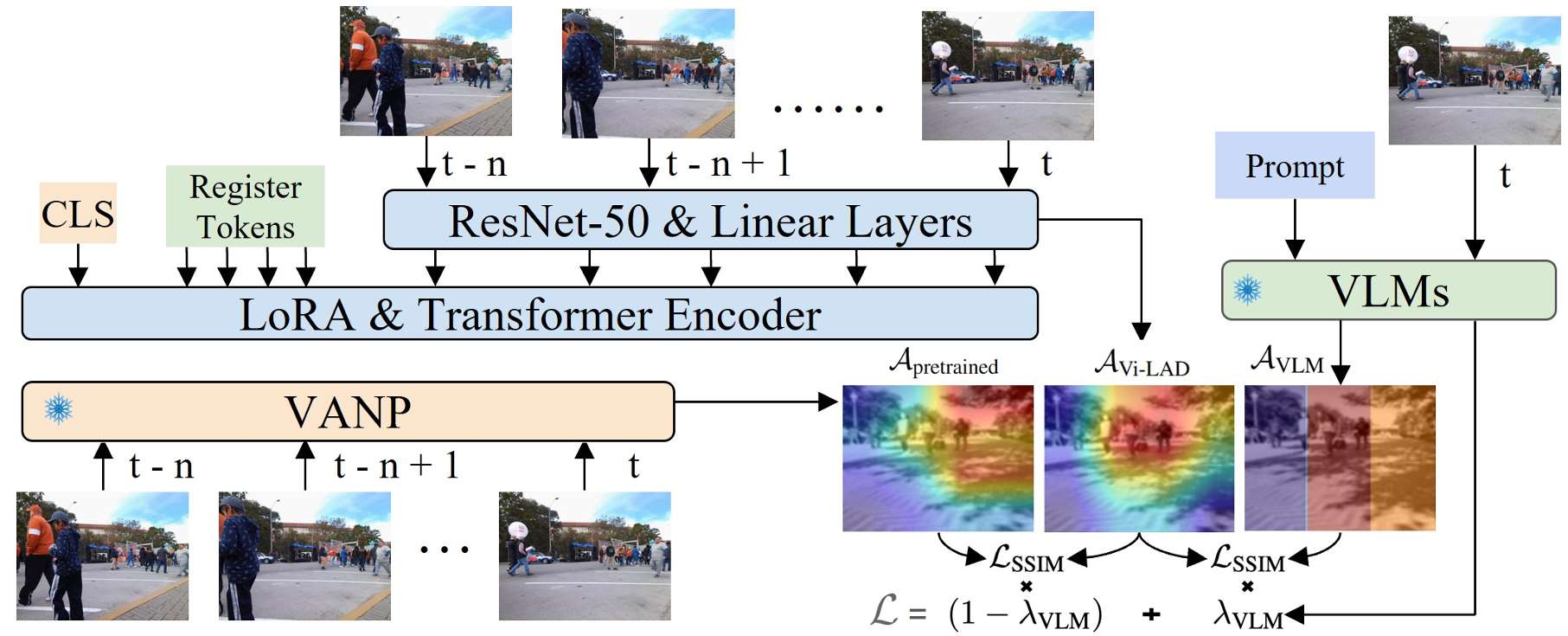
数据生成
- 数据集构建:通过利用视觉-语言模型(VLM)生成社会引导的注意力图来构建一个社会导向的导航数据集。这些注意力图突出了导航相关的区域。
- 标注过程:选择了一个定制化的SCAND数据集子集,并使用VLM进行标注。对于每个样本,定义了三个导航前沿(左、中、右),并在RGB图像上叠加彩色矩形以突出这些区域。
- VLM查询:使用链式思维(Chain-of-Thought, CoT)提示方法查询VLM,以估计每个前沿被人群占据的可能性。根据这些可能性,生成一个包含社会引导导航线索的注意力图。公式如下:
P ( f ) = VLM ( I RGB , T prompt ) P(f) = \operatorname{VLM}(I_{\text{RGB}}, \mathcal{T}_{\text{prompt}}) P(f)=VLM(IRGB,Tprompt)
其中, f ∈ { left , center , right } f \in \{\text{left}, \text{center}, \text{right}\} f∈{left,center,right} 表示导航前沿, T prompt \mathcal{T}_{\text{prompt}} Tprompt 是一个设计用来引出社会背景推理的结构化查询。
蒸馏模型
- 低秩适应(LoRA):使用低秩适应方法对预训练模型进行微调,而不是更新所有模型参数。这通过引入低秩可训练适配器来实现,同时保持原始模型权重的冻结。
- 并行管道:在训练期间,模型由三个并行管道组成:
• 预训练模型( F pretrained \mathcal{F}_{\text{pretrained}} Fpretrained):提取导航相关的注意力图。
• 蒸馏模型( F Vi-LAD \mathcal{F}_{\text{Vi-LAD}} FVi-LAD):在ResNet50的最后一层提取更新的注意力图。
• VLM监督:VLM处理RGB图像以生成社会引导的注意力图,提供微调的监督信号。
注意力引导的损失函数
- 注意力一致性损失:为了整合来自VLM的社会推理,同时保持预训练模型的导航先验,引入了一个注意力一致性损失函数。
- 损失函数公式:总损失函数结合了两个目标:
L = ( 1 − λ VLM ) ⋅ L SSIM ( A Vi-LAD , A pretrained ) + λ VLM ⋅ L SSIM ( A Vi-LAD , A VLM ) \mathcal{L} = (1 - \lambda_{\text{VLM}}) \cdot \mathcal{L}_{\text{SSIM}}(\mathcal{A}_{\text{Vi-LAD}}, \mathcal{A}_{\text{pretrained}}) + \lambda_{\text{VLM}} \cdot \mathcal{L}_{\text{SSIM}}(\mathcal{A}_{\text{Vi-LAD}}, \mathcal{A}_{\text{VLM}}) L=(1−λVLM)⋅LSSIM(AVi-LAD,Apretrained)+λVLM⋅LSSIM(AVi-LAD,AVLM)
其中, L SSIM \mathcal{L}_{\text{SSIM}} LSSIM 是注意力图之间的余弦相似度,定义为:
L SSIM ( A , B ) = 1 − ∑ ( A ⋅ B ) ∥ A ∥ ∥ B ∥ \mathcal{L}_{\text{SSIM}}(A, B) = 1 - \frac{\sum(A \cdot B)}{\|A\| \|B\|} LSSIM(A,B)=1−∥A∥∥B∥∑(A⋅B)

社会意识的运动规划器
- 模型预测控制(MPC)框架:采用一个修改后的MPC框架来生成社会意识的导航轨迹。MPC优化线速度和角速度对,以引导机器人朝向目标,同时确保平滑且社会合规的运动。
- 社会成本函数:引入一个社会成本函数,通过注意力图(
A
Vi-LAD
\mathcal{A}_{\text{Vi-LAD}}
AVi-LAD)对齐机器人的行为与人类导航规范。通过计算投影轨迹与蒸馏注意力图的对齐度来定义社会成本。公式如下:
s o c ( v , ω ) = max ( i , j ) ∈ traj C ( v , ω ) A Vi-LAD ( i , j ) soc(v, \omega) = \max_{(i, j) \in \text{traj}^C(v, \omega)} \mathcal{A}_{\text{Vi-LAD}}(i, j) soc(v,ω)=(i,j)∈trajC(v,ω)maxAVi-LAD(i,j)
其中, traj C ( v , ω ) \text{traj}^C(v, \omega) trajC(v,ω) 是投影到代价图的轨迹, A Vi-LAD ( i , j ) \mathcal{A}_{\text{Vi-LAD}}(i, j) AVi-LAD(i,j) 表示在给定位置的分散注意力代价图。
结果与分析
实现与机器人设置
- 实现:论文使用PyTorch实现了他们的方法,并在Nvidia A6000 GPU上进行模型训练。
- 机器人设备:在现实世界的实验中,使用了Clearpath Husky机器人,配备了Velodyne VLP16激光雷达、Intel RealSense D435i相机和一台搭载Intel i9处理器和Nvidia RTX 2080 GPU的笔记本电脑。
- 数据集标注:使用GPT-4o对数据集进行标注,以生成社会引导的注意力图。
比较方法
- 动态窗口方法:一种基于MPC的方法,使用2D激光雷达扫描进行避障。
- CoNVOI:一种基于VLM的上下文感知导航方法,使用VLM生成参考轨迹,并由经典规划器执行。
- VANP:一个自监督预训练模型,用于生成注意力图,并与论文的规划器结合使用。
评估指标
- 成功率:成功导航试验的比例,即机器人能够到达目标而不冻结或碰撞障碍物的比例。
- 到达时间:成功试验中机器人到达目标的平均时间(秒)。
- Fréchet距离:衡量人类遥控机器人轨迹与比较方法轨迹之间的相似性。
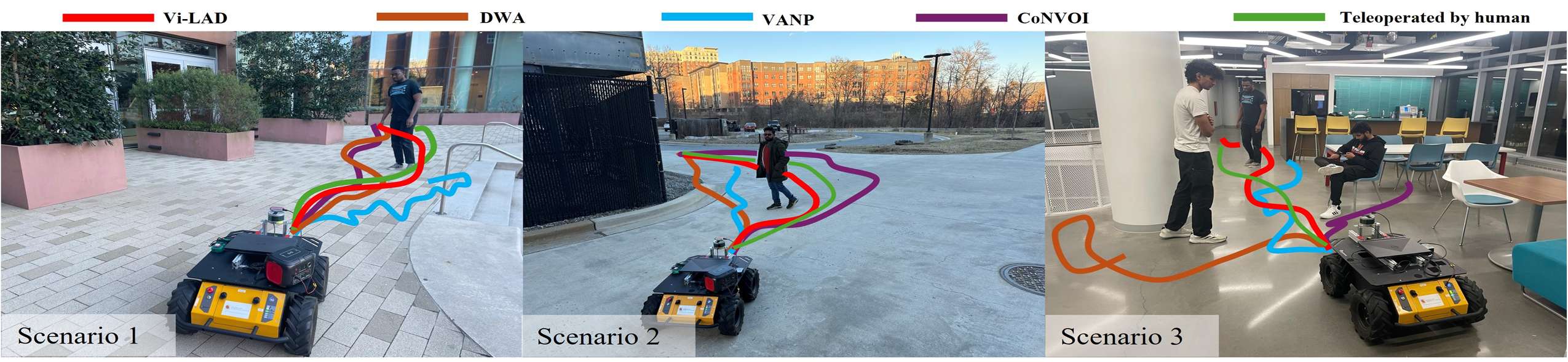
测试场景
- 场景1:包含动态智能体和静态障碍物。
- 场景2:包含动态智能体、围栏和低矮路缘。
- 场景3:多个智能体(坐着和行走)、嵌套的围栏柱、椅子和桌子。
- 场景4:在不同光照条件下有多人行走。
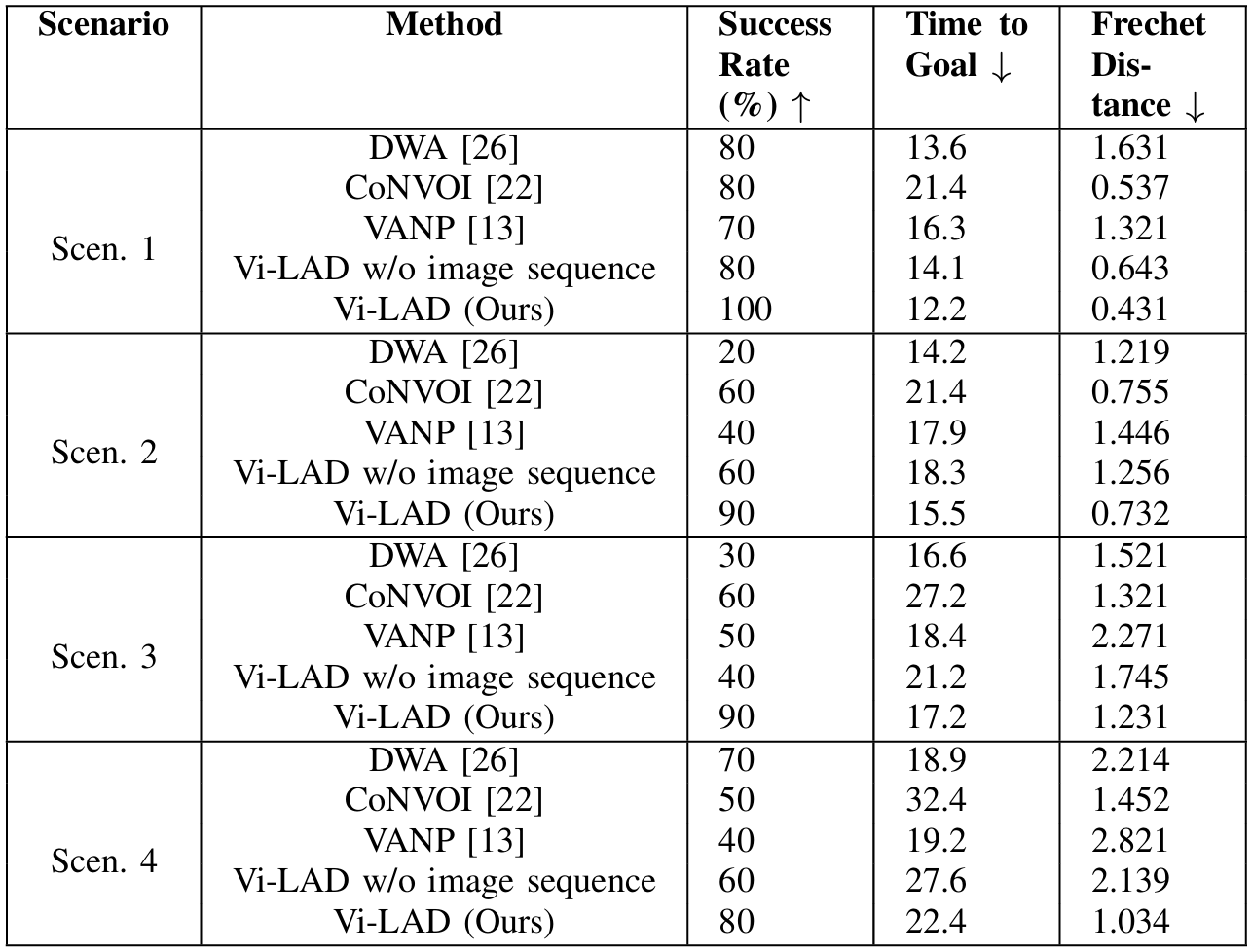
分析与讨论
- 定量分析:结果显示,Vi-LAD在所有场景中均取得了最高的成功率,并且在所有场景中都表现出与人类遥控操作相似的行为,Fréchet距离较低。
- 场景1:Vi-LAD比DWA更早开始移动,并且比CoNVOI更快地到达目标,显示出更低的Fréchet距离。
- 场景2:Vi-LAD能够准确识别路缘并调整轨迹,避免了障碍物和人类的碰撞。
- 场景3:Vi-LAD成功地绕过障碍物,并保持了对环境中人类存在的意识,显示出更社会合规的导航。
- 场景4:Vi-LAD能够动态调整其轨迹以应对移动障碍物,确保了安全和高效的导航。
总结
- 论文提出了Vi-LAD视觉语言注意力蒸馏方法,通过将大型VLM中的社会推理知识蒸馏到轻量级基于变换器的模型中,实现了社会合规且实时的机器人导航。
- 实验结果表明,Vi-LAD在真实世界实验中显著优于现有的最先进方法,具有更高的成功率和更平滑的运动执行。
- 未来的工作将探索多模态预训练模型、在线适应策略以及复杂环境中的长距离导航扩展。