背景
在蓝鲸社区“社区问答”帖子中发现这么一个需求:

究其原因,我在《不是CMDB筑高墙,运维需要一定的开发能力!》一文中已经介绍,在此我再简单重复下:
- 蓝鲸5.1 自带“事件推送”功能,当配置信息发生变化的时候,实时通知到关联的系统中;
- 蓝鲸6.1 不再提供“事件推送”功能,而是由“监听资源变化事件”的一个 CMDB API 实现,需要我们自行查询;
CMDB 版本的迭代,或许说明老版本的“事件推送”已经不符合蓝鲸的设计理念,作为此功能的对接使用者感同深受:
- 事件推送功能全面性,基本覆盖了CMDB全场景的信息变化;
- 事件推送更类似一个图形化的API,通过界面就让开发者知道该如何使用;
- “简单的背后的逻辑复杂化”,这是在对接事件推送接口的第一感受;
- 由于功能的全面性,意味着数据格式的多样性,对接过程你懂得;
通过对事件推送功能对接过程的回顾以及对替代服务resource watch的使用对比,就非常理解蓝鲸社区推陈出新的做法了!
需求
既然是小伙伴们“插眼关注”的问题,与其等待答案,不如我们自己去寻找答案!
API分析
”监听资源变化事件“接口, 可监听系统资源变化产生的事件。
该 watch 功能的主要特性包括:
- 在有限的时间内(目前为 3 小时,可能会调整,请勿依赖此时间)为用户提供高可用的数据变更 watch 服务。
- 在有限时间内,用户可以根据自己上一次事件的 cursor(游标)进行事件回溯或者追数据,适用于异常数据回溯,或者系统变更进行数据补录。
- 支持根据时间点进行变更数据回溯,支持根据游标进行变更数据回溯,支持从当前时间点进行数据变更 watch。
- 支持根据事件类型进行 watch 的能力,包括增、删、改。事件中包含全量的数据。
- 支持主机与主机关系数据变化的事件 watch 能力。
- 采用短长链的设计,当用户通过游标进行事件 watch 时,如果没有事件,则会保持会话连接,在 20s 内有事件变更则直接直接将事件推回。避免用户不断请求,同时保证用户能及时的拿到变更的数据。
- 支持批量事件 watch 能力,提升系统吞吐能力。
- 支持定制关注的事件数据字段,满足用户轻量级的 watch 需求。
链接:https://bk.tencent.com/docs/document/6.1/190/14399
事件先行
对接CMDB属于事件驱动,因此事件先行,先来分析通过API都能获取哪些事件:
- host 代表主机详情事件
- host_relation 代表主机的关系事件(主要使用)
- biz 代表业务详情事件
- set 代表集群详情事件
- module 代表模块详情事件
- process 代表进程详情事件
- object_instance 代表通用模型实例事件
- mainline_instance 代表主线模型实例事件
- biz_set 代表业务集事件
- biz_set_relation 代表业务集和业务的关系事件
以上事件未必都能用到,我们只要按需获取即可,这也体现了watch服务的灵活性!
动作其次
每类事件都有其相应的动作:
- create 创建
- delete 删除
- update 更新
我们的工作重点就是从事件中将增、删、改的动作分离出来,对下游系统进行事件回放,从而保证数据同步。
时间/事件回溯
虽然时间回溯最长间隔为3小时,我们还是希望对不同粒度的事件进行区分,原则如下:
- host_relation 主机关系事件,实时生效;
- module 模块事件,实时生效;
- set 集群事件、biz 业务事件等,可适当在不同时间间隔生效;
时间回溯保证我们能查到历史数据,而事件回溯的cursor游标能够保证我们避免重复的事件。
因此我们对于时间/事件回溯要有一个清醒的理解!
功能需求
通过API的分析,其实我们的功能需求也就同时梳理了出来:
- 核心目标:CMDB驱动资产同步,按业务/集群/模块/主机的结构与下游系统实现关系对应;
- 事件驱动:
- biz 业务名同步;
- set 集群名同步;
- module 模块名同步;
- host_relation 主机关系同步;
- 其他名称或关系同步;
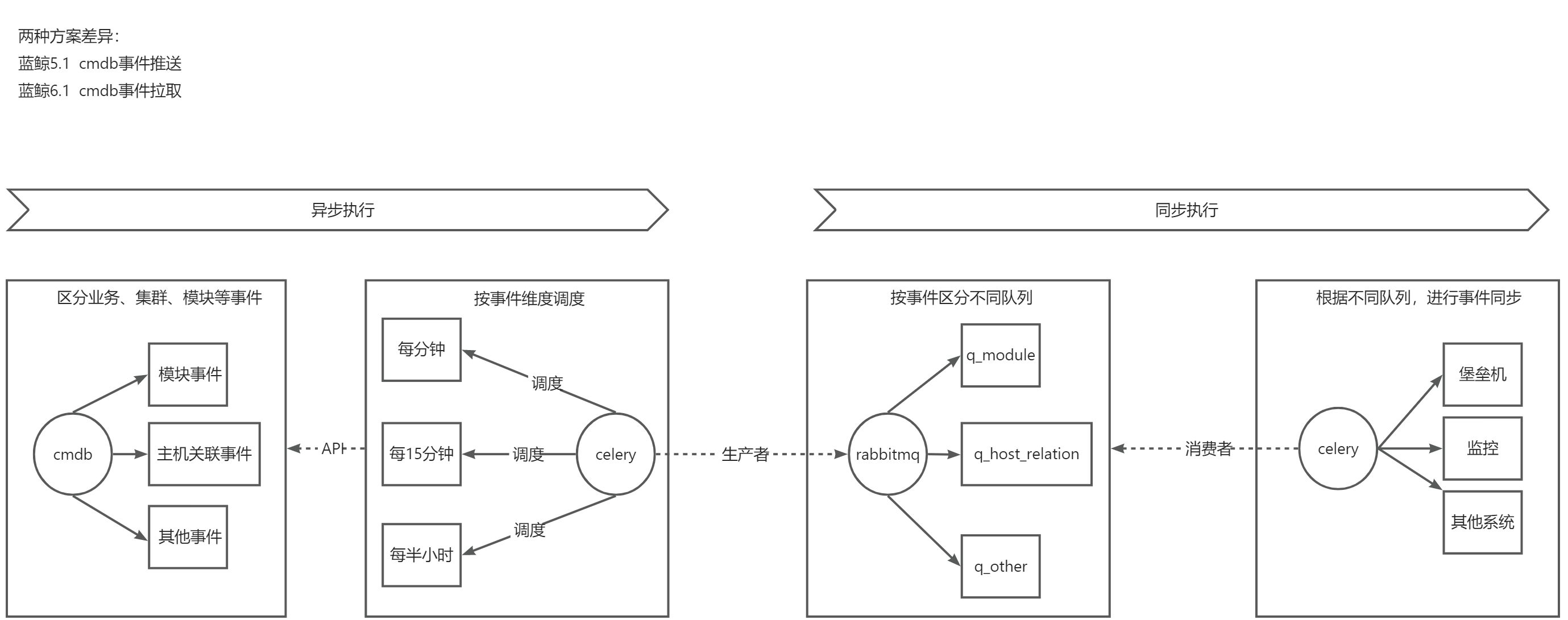
开发框架
根据”监听资源变化事件“接口的特性,我梳理了下开发过程的几个要点:
- 对于事件的获取、与下游系统同步,这是两个步骤。不需要等待同步完成再去获取事件,要进行解耦
- 事件获取,异步执行;
- 与下游系统对接,同步执行;
- 不同事件变化的频繁度不同,我们要按需获取,因此就需要一个调度器,可自定义调度计划;
通过以上分析,我们初步确认了python + celery + rabbitmq的几个组件:
- celery 用于对不同时间回溯间隔的调度;
- rabbitmq 通过交换机、路由、队列分别保存celery调度的任务;
- python对不同事件结果封装统一的数据与其他运维系统进行资产同步;
其具体的实现流程如下图:
具体部署
依赖组件
- Python 3.9
- Celery
- Rabbitmq 保存celery调度任务
安装
- python环境
conda create -n resource-watch python=3.9
source activate resource-watch
pip install requests celery pyamqp flower kombu
- rabbitmq环境
# 安装rabbitmq
yum install rabbitmq-server
systemctl start rabbitmq-server
systemctl enable rabbitmq-server
# 开启 RabbitMQ 的web管理界面
rabbitmq-plugins enable rabbitmq_management
# 创建admin用户并授权
rabbitmqctl add_user admin admin
rabbitmqctl set_user_tags admin administrator
rabbitmqctl set_permissions -p '/' admin '.' '.' '.*'
rabbitmqctl list_users
rabbitmqctl list_user_permissions admin
systemctl restart rabbitmq-server
# 访问rabbitmq管理界面
http://ip:15672
- 路由队列
针对不同事件,使用不同的队列
| 交换机 | 路由 | 队列 | 备注 |
|---|---|---|---|
| cmdb | cmdb.host_relation | cmdb.host_relation | 主机关联关系事件 |
| cmdb | cmdb.module | cmdb.module | 模块事件 |
| cmdb | cmdb.set | cmdb.set | 集群事件 |
| cmdb | cmdb.biz | cmdb.biz | 业务事件 |
- 运行
cd /app/resource-watch
# 启动beat,将定时任务发送至worker
celery -A celery_cmdb beat -l INFO --detach
# 启动worker,异步执行任务,绑定相应事件队列
celery -A celery_cmdb worker -Q cmdb.host_relation -l INFO -c 1 -D
celery -A celery_cmdb worker -Q cmdb.module -l INFO -c 1 -D
celery -A celery_cmdb worker -Q cmdb.set -l INFO -c 1 -D
celery -A celery_cmdb worker -Q cmdb.biz -l INFO -c 1 -D
# 启动flower,任务查看
总结
整个开发过程比较重要的是“对不同事件结果数据的封装”,除了部分开发经验外,就是要不断的试错,这样才能保证我们完成对最终的数据格式的解析,从而更好的匹配下游运维子系统!






![微信小程序:实名认证登录 [2018年]](https://img-blog.csdnimg.cn/6393da47fc4b45d9bd447f59cd8a48ab.png)