CVPR 2023 | SAN: Side Adapter Network for Open-Vocabulary Semantic Segmentation
- 论文:https://arxiv.org/abs/2302.12242
- 代码:https://github.com/MendelXu/SAN

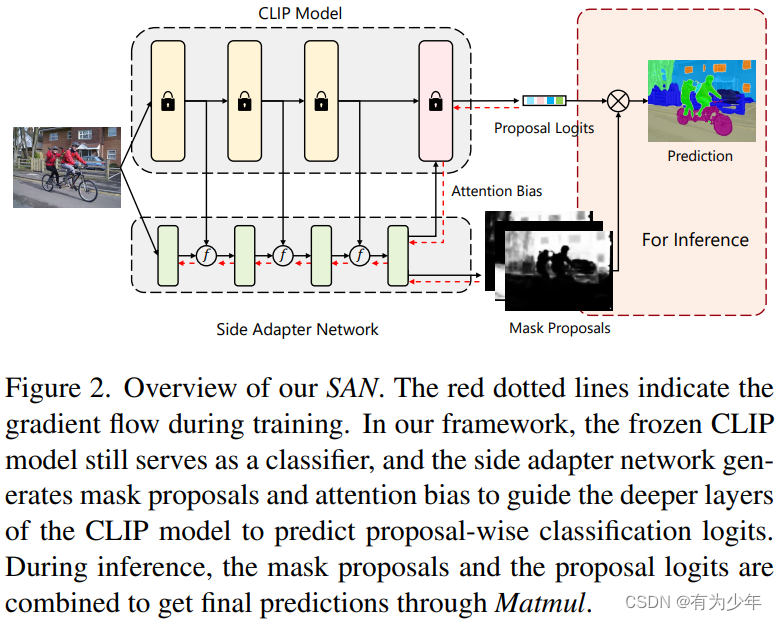

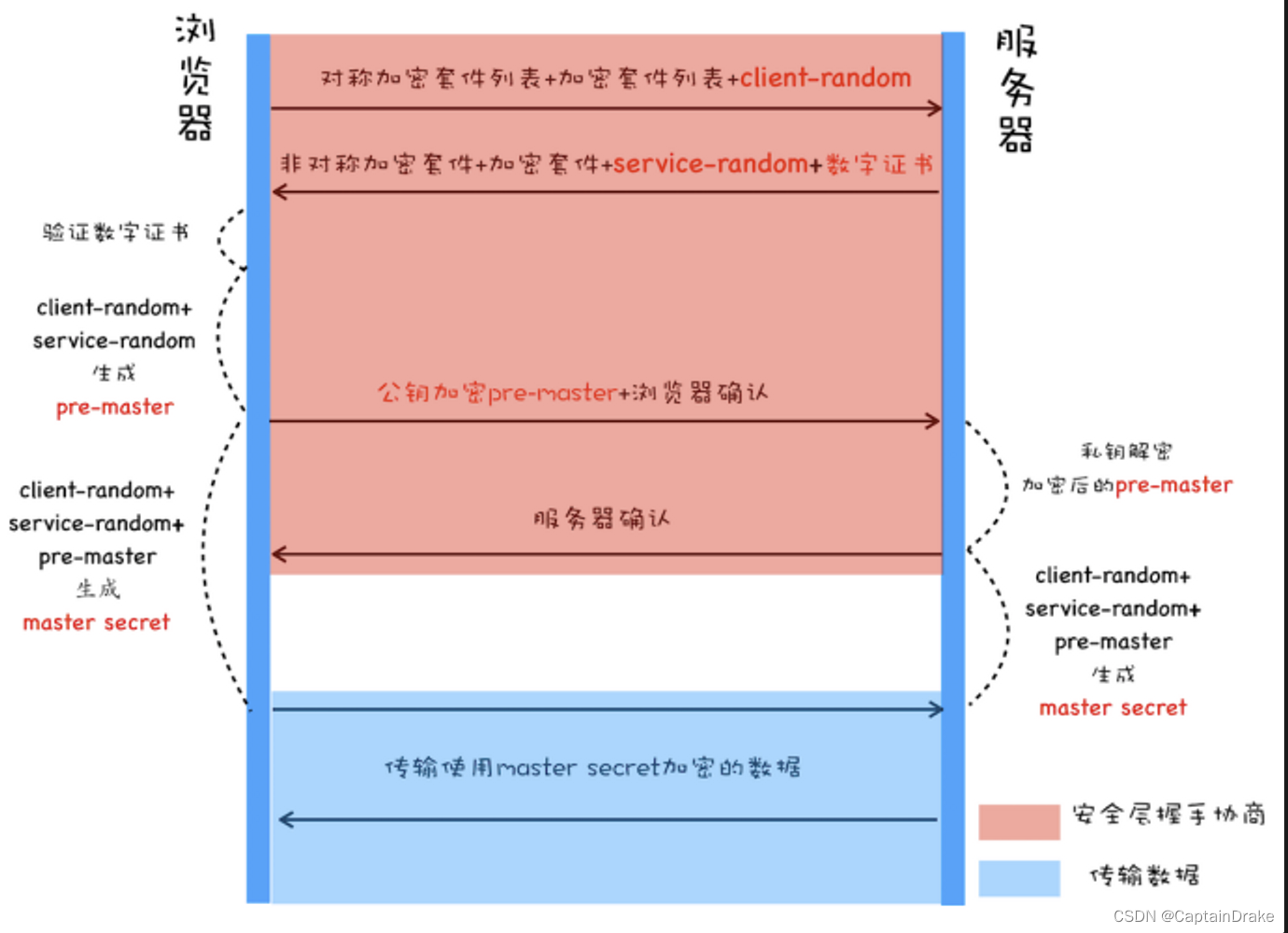
架构设计
- 冻结的 CLIP,其位置编码为了适应不同于预训练的输入分辨率,需要进行微调。
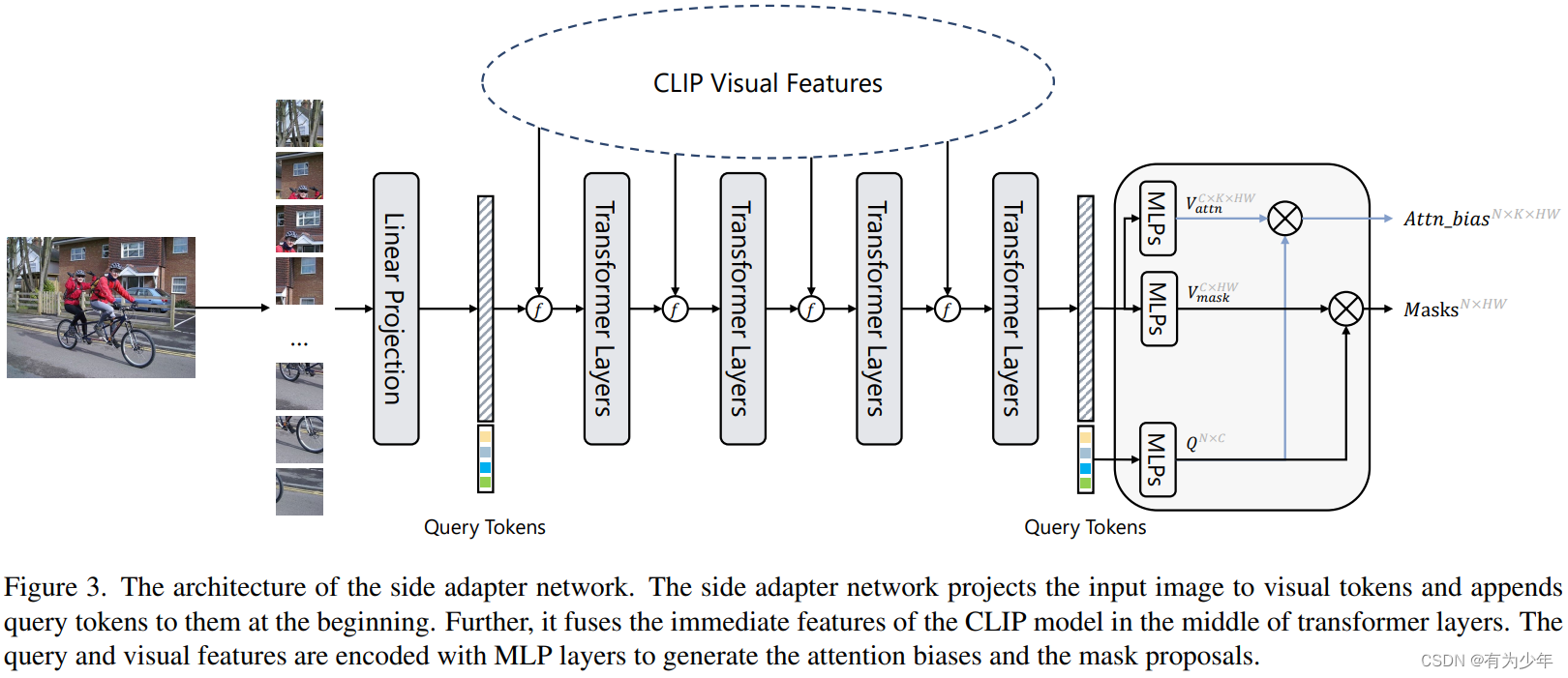
- 基于 Transformer (使用各层共享的绝对位置编码)的可训练的与 CLIP 交互的轻量 Adapter 模型。其输入为高分辨率图像,中间的 Transformer 层中附加了可学习的 N(默认为 100)个 token 作为特殊的 query,在模型最后用于 Mask Proposal 生成。
解码设计
- Adapter 结构与 CLIP 交互。并将 CLIP 分成浅层和深层两个不同的阶段。
- 融合 visual token:浅层 CLIP 块的特征中 CLS 之外的 visual token 特征被重排、1x1 卷积和放缩操作后,加到 Adapter 的对应特征上。
- Mask 预测与识别:深层 CLIP 块则会使用 Adapter 生成的 Mask Proposal 和对应的 Attention Bias 用于 Mask Recognition。
- Mask Recognition
- Adapter 端:N 个 query token 与自身的 visual token 之间通过变换和内积获得形状为 H / 16 × W / 16 × K × N H/16 \times W/16 \times K \times N H/16×W/16×K×N(K 为 Attention 头的数量)的用于调整 CLIP Attention 中运算的 Attention Bias。
- CLIP 端:为了不改变 CLIP 的参数,这里利用 Attention Bias 引导原本用于图像级别分类的 CLS token 在感兴趣区域的注意力图,从而实现 Mask 识别。这里引入了使用 CLS 初始化的 N 个 SLS tokens(类似于 Openvocabulary panoptic segmentation with maskclip 中的设计,但本文中是否是可训练的并不清楚,直观理解应该是在初始化的基础上不断更新,本身不额外优化)。而 SLS tokens 的更新过程独立于 CLIP 中原始的其他 token(visual tokens 和 CLS token),不直接影响他们,而仅仅会利用 visual token 更新自身。这一更新过程中:Q 和 V 都来自 SLS,K 来自 CLIP 的 visual token。Adapter 中预测得到的 Attention Bias 会被加到 QK 结果上。
- 通过类别文本嵌入与 SLS 之间计算相似性获得了 N 与不同类别之间的对应关系矩阵,即 Proposal Logits。从而可以用于分类(论文未说明如何分类),使用分类损失监督。
- Mask Prediction:Adapter 中附加的 N 个 query token 与自身的 visual token 之间通过变换和内积获得形状为 H / 16 × W / 16 × N H/16 \times W/16 \times N H/16×W/16×N的 Mask Proposal。利用已经获得的 Proposal Logits,相乘可以获得每个类别对应的分割图。使用分割损失监督。
- Mask Recognition
其他设计
- Prompt Engineering:CLIP 文本模型基于 14 个模板嵌入的平均作为最终的文本嵌入。
- 基于 Adapter 的思想,在 CLIP 的视觉编码器上构建了轻量可学习的辅助结构,通过单次前向传播同时完成了 Mask 预测与识别的任务。
- 将 Mask 预测与识别进行了解耦,作者认为,在 CLIP 中用于识别 Mask 的区域可能并不是 Mask 本身所对应的区域。
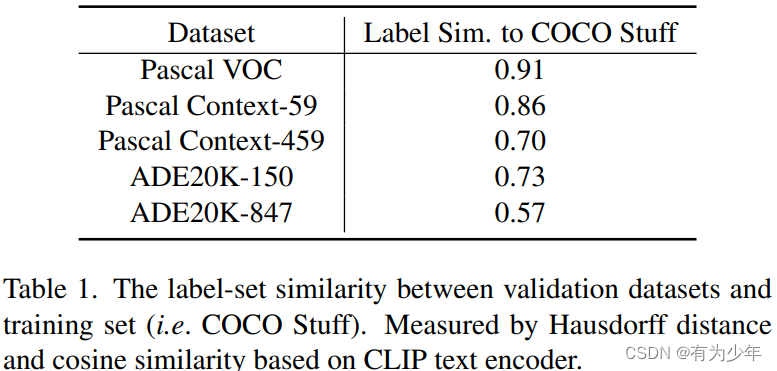
- 利用 CLIP 文本编码器统计了不同测试集与 COCO stuff 测试集之间的类别标签集合的相似程度,从这些不同程度的相似情况可以反映出这些数据集实际上可以展现出模型的在 in-domain 和 cross-domain 两种类型的 open-vocabulary 能力。
- 实验展现了一些有意思的结论:
- CLIP-aware 的 Mask Prediction 的设计对于模型性能的重要性。
- 微调位置编码(优于固定的位置编码)来适应新尺寸的设定下,CLIP 模型最优的输入尺寸并非是预训练尺寸。这与 CLIPSeg 中的实验现象类似。
- 微调 CLIP 模型会破坏 CLIP 的开集能力。冻结的使用形式是最优的。
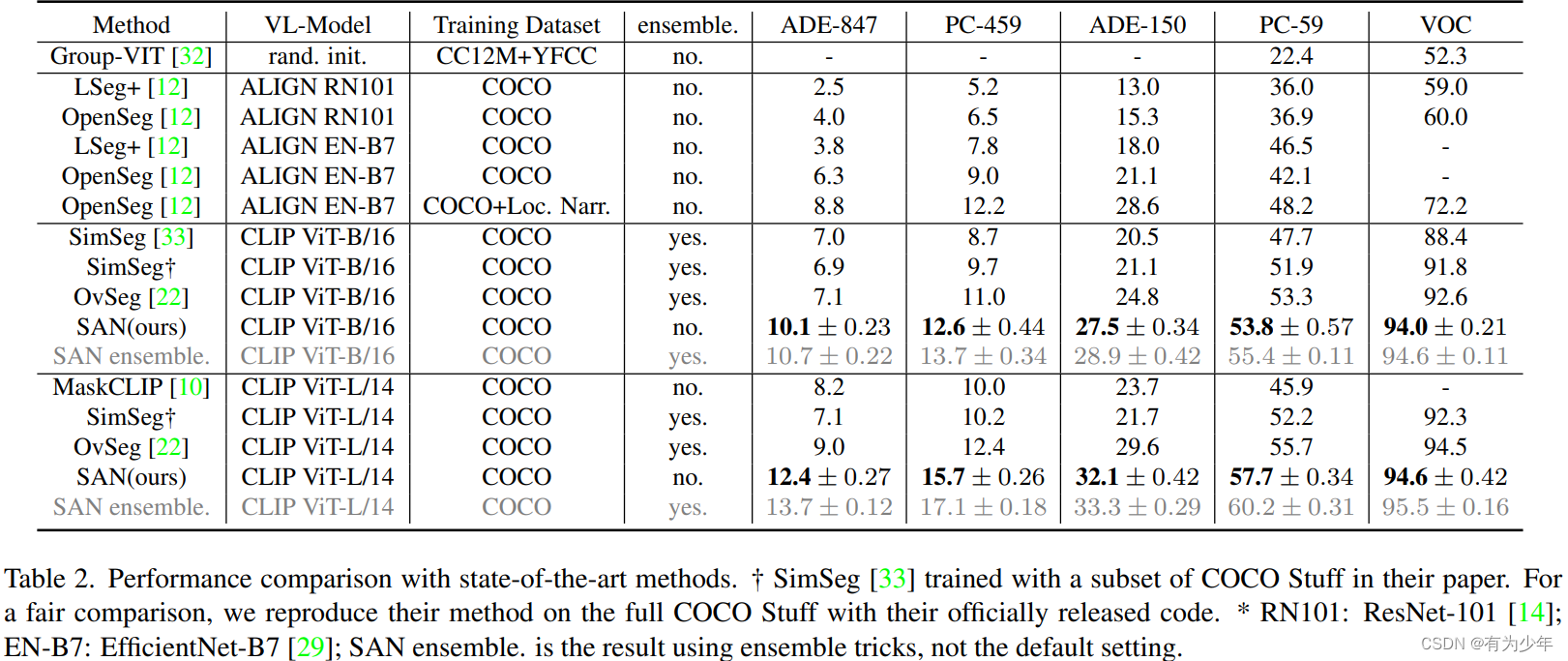
性能对比