写在前面
2021 年年底,OpenAI 发布了 CLIP,利用带噪的图像-文本配对数据预训练的视觉语言模型,展示了前所未有的图像-文本关联能力,在各种下游任务中取得了惊人的结果。虽然取得了很大的进展,但是这类通用视觉语言基础模型并不能在一些特定域的数据集表现良好,比如遥感数据、医学数据。因此,一个关键的挑战是如何利用现有的通用大规模预训练视觉语言模型,来执行特定于域的迁移,以完成与域相关的下游任务。
在本文中,作者提出了一个新的框架来弥合了通用基础模型和领域特定下游任务之间的差距。此外,作者提出了遥感领域最大的图像-文本配对数据集 RS5M,其中包含 500 万张带有英文描述的遥感图像。该数据集由两方面构成:1)过滤公开的大规模图像-文本配对数据集;2)用预训练的大模型对大规模遥感数据集生成图像描述。
此外,作者还在 RS5M 数据集上尝试了几种参数高效微调方法(PEFT)来实现领域基础模型。实验结果表明,本文提出的数据集在遥感图文相关的下游任务上是有效的,其中在零样本分类任务上将准确率提高了 8%~16%,在遥感视觉语言检索和遥感语义定位任务上也都取得了不错的效果。

论文标题:
RS5M: A Large Scale Vision-Language Dataset for Remote Sensing Vision-Language Foundation Model
论文链接:
https://arxiv.org/abs/2306.11300
代码链接:
https://github.com/om-ai-lab/RS5M

简介
遥感技术(RS)在环境监测、城市规划、自然灾害管理等方面发挥着重要作用。然而,遥感图像数量的急剧增长为高效和有效地处理、分析和理解RS数据中包含的信息带来了新的挑战。在过去的十年中,基于监督的深度学习模型已经成为应对这些挑战的强大工具,在场景分类、目标检测、语义分割和变化检测等 RS 任务中取得了巨大成功。尽管取得了这些进展,但在遥感下游应用中深度学习模型的性能往往因为标注数据集规模太小而受到限制。
此外,遥感图像的解译通常需要专业的领域知识,因此对遥感图像进⾏标注的成本十分昂贵,而这造成了模型在遥感下游任务上性能提升的瓶颈。作为一种对遥感图像的天然监督,配对的文本描述在帮助学习更好的数据表征方面具有很大的潜力。
近几年,深度学习模型在 CV 和 NLP 领域都有了很快速的发展,研究人员开始探索结合视觉和文本模态的潜力,以开发能够理解多模态内容的更强大、更通用的模型。预训练视觉语言模型 (pre-trained VLMs) 是一种很有前景的方法,它可以利用自然语言的词语切分信息和图像中丰富的视觉信息来实现通用基础模型。例如,CLIP 利用对比损失函数连接两个模态,从而在许多下游任务和领域迁移中实现了很强的通用性。
VLM 的另一个重要应用是生成模型,如 DALLE 和 stable-diffusion。然⽽,由于⽬前⼤部分性能优异的视觉语⾔模型都使⽤通⽤物体数据进⾏训练,pre-trained VLMs 通常在特定领域表现不佳,如遥感和医学图像,其原因在于训练数据和下游任务数据的域不够匹配。
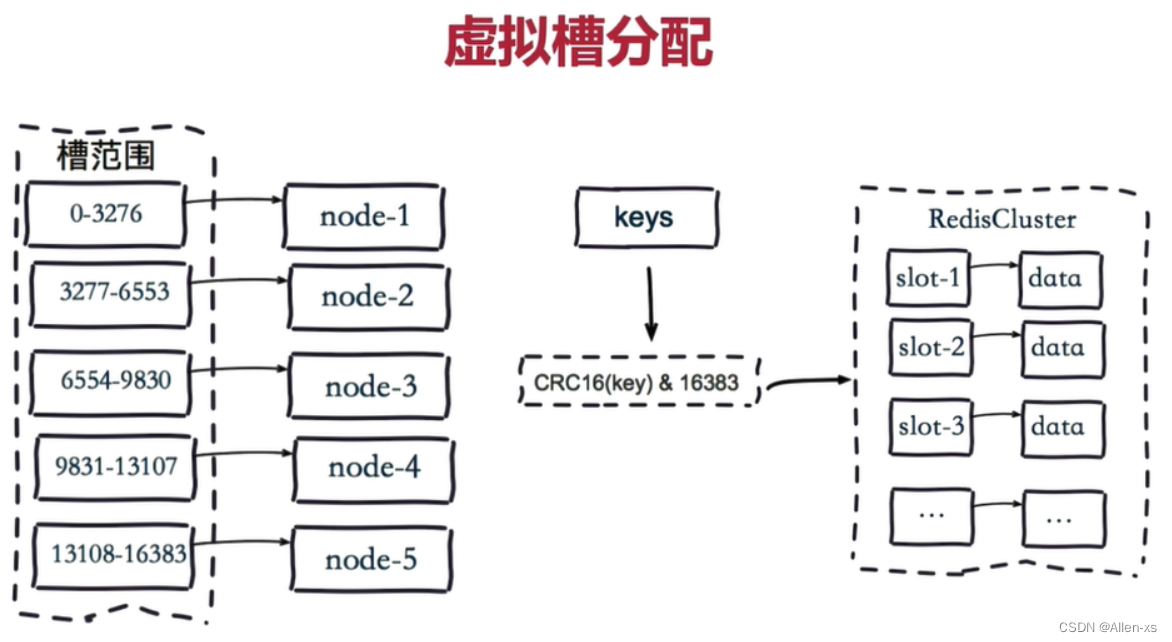
为了在 RS 领域中能够更好地利用通用基础模型(GFM)强大的表征提取能力和图文配对能力,使用一个能够利用 GFM 的泛化性的特定域基础模型(DFM),并结合外部的领域先验知识,再通过合适的学习范式将这些知识迁移到特定领域的下游任务模型 (DTM) 十分重要。该过程如下图所示。
之前有工作(比如 FETA)提出了用于专家任务的基础模型,他们使用 LoRA 直接对通用基础模型进行调优,将之用于公共汽车手册和销售目录手册的检索任务,但 GFM→DFM→DTM 结构和 DFM 的重要性并未得到广泛讨论。尽管训练 DFM 所需的数据量可以比训练 GFM 的少很多,但数据量仍然是能否得到一个优质 DFM 的基础。
就遥感而言,地理空间元数据、土地覆盖注释、专家描述和图像标题等文本信息为遥感图像提供了自然的监督,提供了比单独的类级别标签更丰富的上下文。现有的⼀些⼯作使⽤来⾃ GLIDE 的合成数据对分类器进⾏微调,在 EuroSAT 数据集上将 CLIP 零样本图像识别 top-1 的准确率提高了 17.86%,显示了出很好的潜力。
一些研究提出了 RS 图像-文本配对数据集。然而,这些数据集包含的样本太少,无法有效地迁移或微调大规模预训练的 VLM。同时,还有⼤规模的包含数百万张遥感图像的遥感数据集,但只有类级标签。总的来说,⼤规模的图像-⽂本配对数据在遥感领域是罕⻅的,因此收集⼤量的遥感域内配对数据是十分重要的。
本文的主要贡献如下:作者构建了第一个大规模遥感图像-文本配对数据集 RS5M,该数据集完全基于对已有大规模图像-文本配对数据集的过滤,以及使用预训练模型对大规模遥感图像数据集生成对应的图像描述,并使用了广泛的去噪方法。RS5M 的规模是现有最大的遥感图像-文本配对数据集的近 1000 倍。为了更好地利用通用基础模型 (GFM) 和领域数据,作者显式地提出了领域基础模型 (DFM) 和 GFM→DFM→DTM 的框架。
作者使用了多种参数高效调优方法来实现遥感领域的 DFM,并将通用视觉语言模型作为遥感领域视觉语言任务的一个很强的基线。此外,作者还证明了 RS5M 可以用于训练其他类型的模型,如专门用于遥感图像生成的 Stable Diffusion。通过大量的实验,作者证明了本文的框架结合提出的 RS5M 数据集,可以成功地将 pre-trained VLM 迁移到遥感领域,并在相关的下游任务上表现得更好。

数据集构建
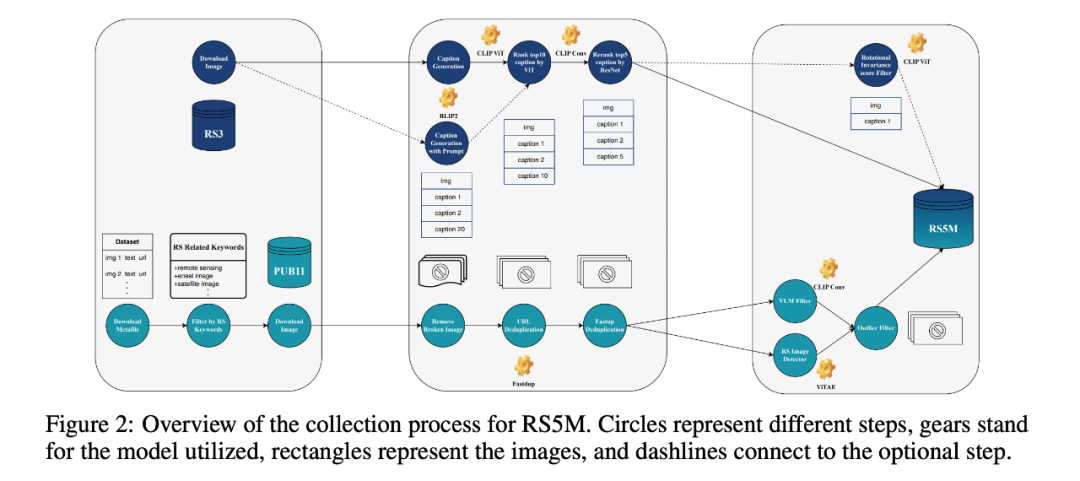
如上图所示,RS5M 数据集由两部分组成。在第一个部分中,作者收集了 11 个公开可用的图像-文本配对数据集 (PUB11),并使用遥感关键词对它们进行过滤。然后,作者利用 url 和其他工具比如 fastdup 对数据进行去重。接下来,作者使用 pre-trained VLM 和遥感图像检测器来去除非 RS 图像。在第二个部分中,作者利用 BLIP2 为 3 个只有分类级标签的大规模遥感数据集 (RS3) 生成描述文本。
3.1 过滤大规模图像-文本对数据集
作者选择的 11 个公开的大规模英文图像-文本配对数据集包括 LAION2B-en、LAION400M、LAIONCOCO、COYO700M、CC3M、CC12M、YFCC15M、WIT、Redcaps、SBU 和 Visual Genome。在这个过程中,作者收集了 300 万图像-文本对,它们以航拍图为主,但也有许多卫星图。
作者建立了一组与遥感密切相关的关键词,它由遥感相关的名词和遥感相关的应用或公司名称组成。作者通过正则表达式对数据进行筛选。在下载所有相关图像后,作者首先过滤掉损坏的图像,并基于 url 删除重复数据。然后使用 fastdup 对数据集进行聚类(所有重复图像归于一类)。对于每一组重复的图像,作者保留其中一组并舍弃剩余的。
执行完上一步清洗后,作者继续使用 pre-trained VLM 和遥感图像检测器清理数据集。首先,作者手工设计了一组 RS 相关文本提示模板(数量为 , 提示记为 )。对于每张图像 ,作者选择一个基于 CNN 的 CLIP-ConvNext-XXL 模型来计算提示模板的平均文本特征 与图像特征 之间的余弦相似度 ()。
然后,作者构建了一个二分类的遥感分类数据集(遥感图像和非遥感图像两类),并用该数据集对基于 ViT 的 ViTAE 模型的分类器进行微调,以此作为 RS 图像检测器。作者将一张图像 是遥感图像的概率记为 。最后,作者基于这两个模型给出的联合分数 对 RS5M 中的数据进行过滤(具体实现、参数选择和更多分析可见附录)。
3.2 标注大规模遥感图像数据集

尽管遥感图像和通用图像存在域差异,但使用在具有通用目标的图像上预训练的 VLM 对遥感图像生成文本描述已是有用的,如上图所示。因此,作者使用 Huggingface 版本的 BLIP2 模型来生成文本描述。处理的数据集包括 BigEarthNet、FMoW 和 MillionAID。具体来说作者使用了 FMoW (727,144 张图像) 和 BigEarthNet (344,385 张图像) 的训练集,MillionAID 的测试集 (990,848 张图像),RS3 子集共有 2,062,377 张图像。
作者为每张图像生成 20 个候选文本描述,并使用 CLIP ViT-H/14 对它们进行排名。然后,使用 CLIP Resnet50x64 对前 10 个结果重新排序,并保留前 5 个文本描述。对于 BigEarthNet 和 FMoW,类别名称被编入生成提示。对于 MillionAID,需要在没有提示的情况下生成描述。作者采样了 10,000 个描述并人工对其进行评估,排名靠前的文本描述有着令人满意的水平。在上图提供的示例中,诸如机场、河流、农田、桥梁、街道、海湾和环形交叉路口等都是出现在图像中的目标。
旋转不变特征在遥感领域至关重要,因为卫星或无人机捕获的地面目标通常保持其形状,大小和颜色,例如河流,森林和耕地。但是,拍摄角度的变化可能导致地面目标旋转。因此,作者希望能够获得一些文本描述,使得无论拍摄角度如何变化,描述始终能够准确地形容图像。为了实现这一点,作者设计了一个旋转不变标准来获得高质量的文本。
首先,对于一个图像 ,作者通过前面的步骤生成 个文本描述,表示为 ,其中 )。接着,作者通过旋转旋转图像至 12 个不同的角度(间隔为 30 度)来对图像进行增广,记为 。作者希望找到一个 ,使得 能够最小化不同角度的图像特征与文本特征之间的余弦相似度的方差。换句话说,无论图像旋转的角度如何,文本描述与多个旋转后的图像的相似度的波动都非常小()。

数据集描述分析

上图显示了在图像标题中出现的关键词的频率统计。短语“航拍图”在标题中占主导地位,这说明了 RS5M数据集中有大量航拍视角的遥感图像。中间的图显示了从 RS5M 标题中提取的词云。所有的特殊字符和数字以及大部分介词都被移除了。标题中经常出现的词包括“卫星”、“田野”、“建筑”、“道路”和“农场”等。右图为对数尺度下的描述文本的长度分布,分布呈长尾分布,平均描述语句的长度为 40 个单词。
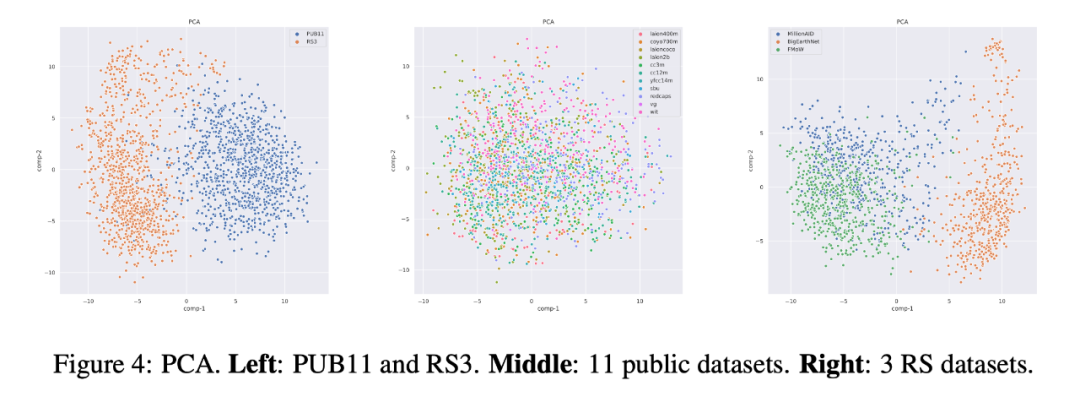
作者使用 CLIP 的视觉编码器 (CLIP-ConvNext-XXL) 从 PUB11 和 RS3 这两个子集中提取图像特征,再使用 PCA 将特征可视化。作者从 PUB11 和 RS3 中平均采样了 1000 张图像,上图(左)显示了 PUB11 和 RS3 的域差异,这个差异可能是由于 PUB11 中有大量的航拍图像,而 RS3 基本全是卫星图像。
上图(中)显示了 PUB11 中 11 个数据集的 2200 个样本的 PCA 可视化。有趣的是,11 个不同数据集的数据之间没有观察到显著的域差异。上图(右)显示 BigEarthNet 和其他两个 RS3 中的数据集之间 (每个数据集采样 500 个样本) 存在明显差异,这可能是由于 BigEarthNet 与其他两个数据集的分辨率差异较大(BigEarthNet 图像的分辨率都是 120x120 像素)。

实验
作者选择 CLIP ViT-B32 模型作为 GFM,并采用 4 种不同的参数高效微调 (PEFT) 方法作为 DFM: Pfeiffer Adapter、LoRA Adapter、Prefix-tuning Adapter 和 UniPELT Adapter。由于本文中的遥感下游任务只需要图像和文本的特征,因此不需要 DTM。然后,对于 RS3 子集,作者随机选择 rank 1 的文本描述或旋转不变的文本描述。
作者从 3 个视觉语言任务:零样本分类 (ZSC)、视觉语言检索 (图像到文本和文本到图像,VLR) 和语义定位 (SeLo) 评估了由 RS5M 数据集调优的 DFM 的领域泛化性。作者选择了完整的 AID、RESISC45 和 EuroSAT 数据集进行 ZSC 任务,RSICD 和 RSITMD 数据集进行 VLR 任务,AIR-SLT 数据集用于 SeLo 任务。作者使用 top-1 准确率来评估 ZSC 任务,使用 recall@1/5/10/mean_recall 来评估 VLR 任务,使用 Rsu, Ras, Rda, Rmi 来评估 SeLo 任务。
5.1 主要实验结果
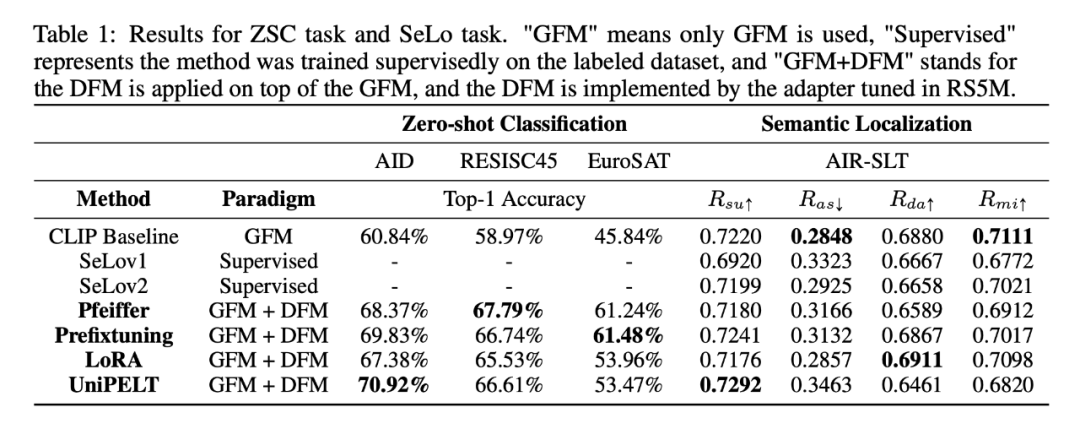
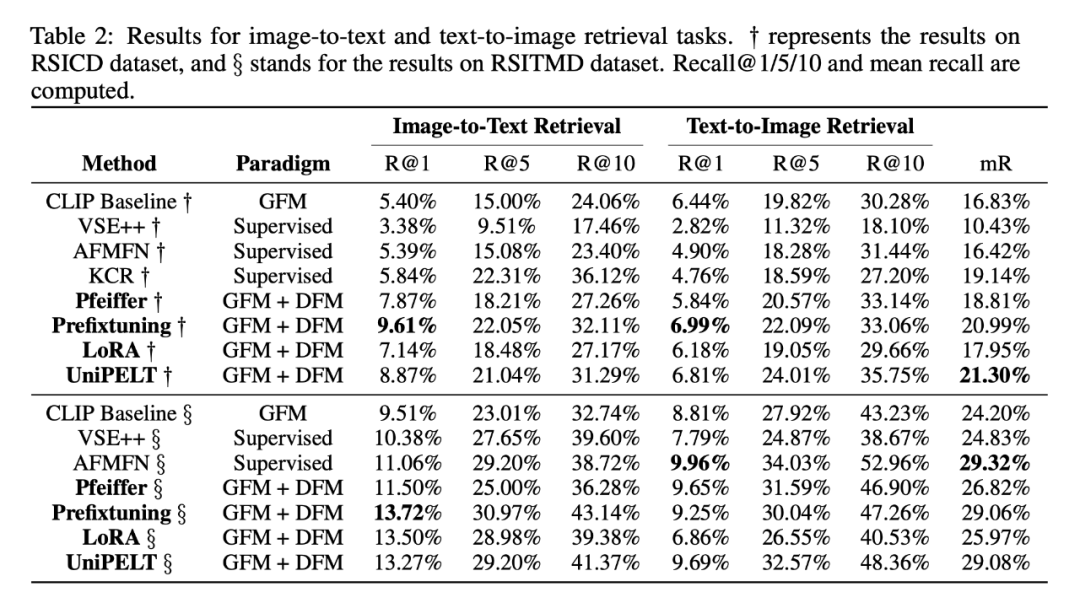
表 1 和表 2 报告了在 VLR、ZSC 和 SeLo 任务上的基线和微调结果。“CLIP baseline” 方法是指未调过的 ViT-B32 CLIP 模型,也就是 GFM-only 方法。“SeLov1”、“SeLov2”、"VSE++"、"AFMFN" 和 "KCR" 都是一些非常有竞争力的、在 RSICD 和 RSITMD 上进行监督训练的结果。在 ZSC 任务上,所有用了 RS5M 的 PEFT 方法都有显著的提升,从 8% 到 16% 不等。在 SeLo 任务上,CLIP 的基线分数已经超过了当前最好的方法。微调后的 UniPELT adapter 在 上表现亮眼,LoRA Adapter 则是在 上。
但是比起 CLIP baseline,所有的 PEFT 方法都使模型在 和 上的表现有所退步,其中一个原因可能归咎于生成的文本描述质量不高(后文会有分析)。另一个因素可能是任务图像域和训练图像域的差异,RS5M 有显著数量的航拍图像,而下游任务以卫星图像为主。VLR 中的图搜文任务最多有 3% 的 recall@1 提升,文搜图任务最多也有 2% 的提升。我们认为这部分还有很大的进步空间,因为我们没有搜索过训练时的超参数,同时也仅仅使用了弱监督的对比学习损失来训练 DFM。
5.2 RS5M的Stable Diffusion

考虑到很难仅用 5M 数据就从头开始训练 Stable Diffusion 模型,作者提出了一个由 1% 的 RS5M 数据微调的 Stable Diffusion 模型,称之为 RS-SD。如上图所示,使用包含“satellite”的提示语句时,vanilla SD 倾向于生成不真实的或偏气象卫星图像风格的图像,而 RS-SD 可以生成更真实、更贴合遥感下游任务的遥感图像。
图上抽样出来的例子显示 RS-SD 对“积雪覆盖的土地”、“有雪的建筑”和“周围的田野”等不常见的描述的理解明显优于 SD。总的来说,RS-SD 在定性和定量生成 RS 图像方面优于普通 SD(见附录)。RS-SD 模型能够生成更真实的 RS 图像,更好地匹配提示描述,无论图像是卫星还是航拍视角。
5.3 消融研究
5.3.1 子集分析
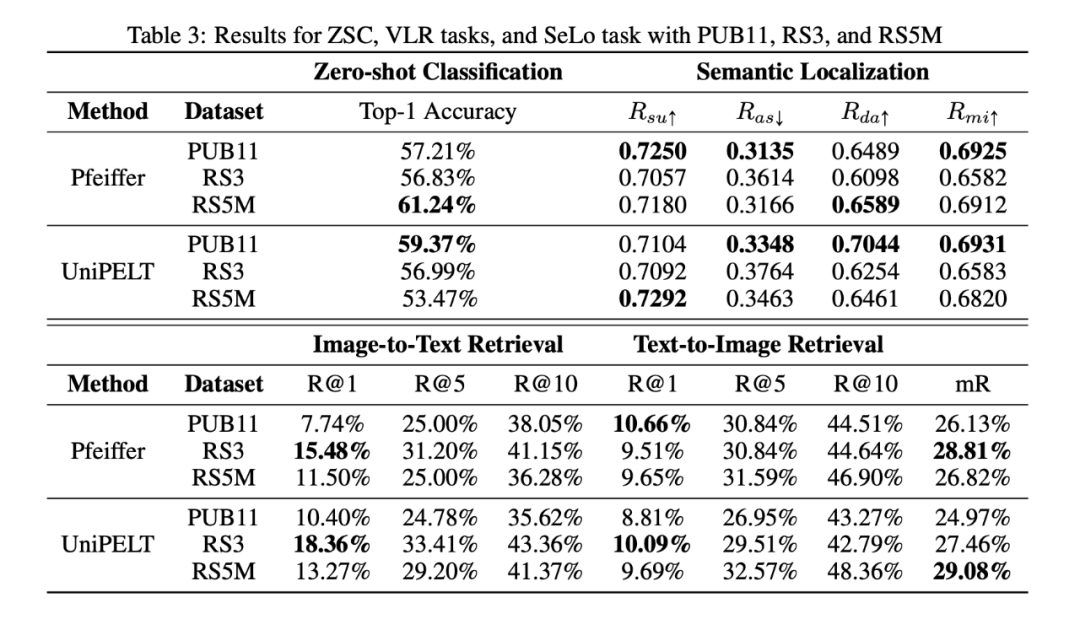
RS5M 数据集由 PUB11 和 RS3 两部分组成。鉴于 PUB11 主要包含航拍图像,而 RS3 仅包含卫星图像,作者对他们进行了独立的分析。这种方法使我们能够分析每个子集的贡献,特别是在理解用大量航拍图像训练模型对基于卫星图像的下游任务的潜在影响这方面。为了便于调查,作者尝试了带有 Pfeiffer 和 UniPELT 适配器的 CLIP 模型,分别选择 RSITMD、EuroSAT 和 AIR-SLT 数据集来评估 VLR、ZSC 和 SeLo 任务。
表 3 说明了在不同任务中使用不同子集训练的模型的性能。对于 ZSC 任务,PUB11 子集对结果有相当大的正面影响,可能是由于来自互联网的大量的和多样化的语料。有趣的是,在 RS5M 上训练的模型比那些只在 PUB11 或 RS3 上训练的模型表现更好。在 SeLo 任务中,PUB11 子集的贡献是积极的,大部分使用该子集训练的多个 DFM 都比使用 RS5M 训练的有更好的表现。此外,RS3 子集在图像到文本检索任务中具有明显的优势(比 RS5M 高 5% 的 recall@1)。这一优势可能与 RS3 域内卫星图像丰富有关。
5.3.2 PUB11中噪声水平的影响
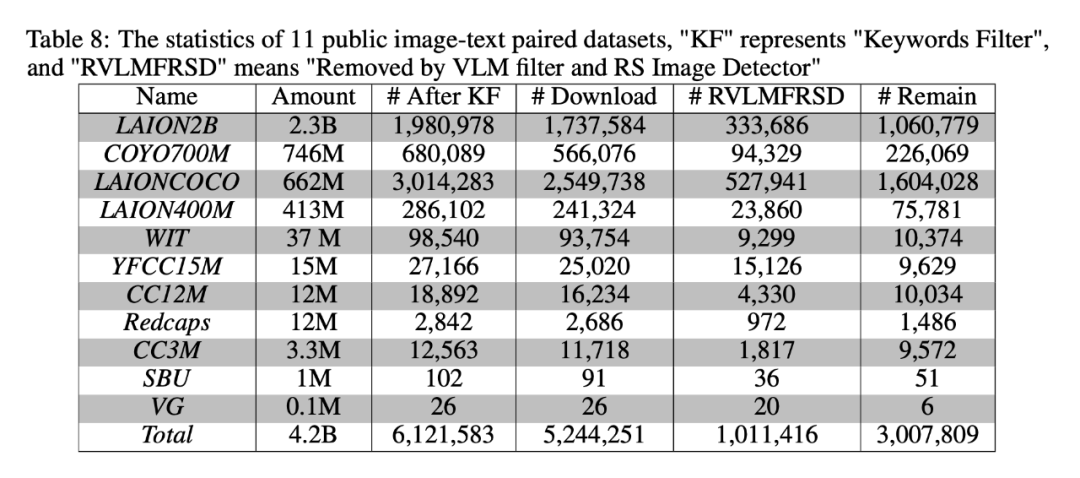
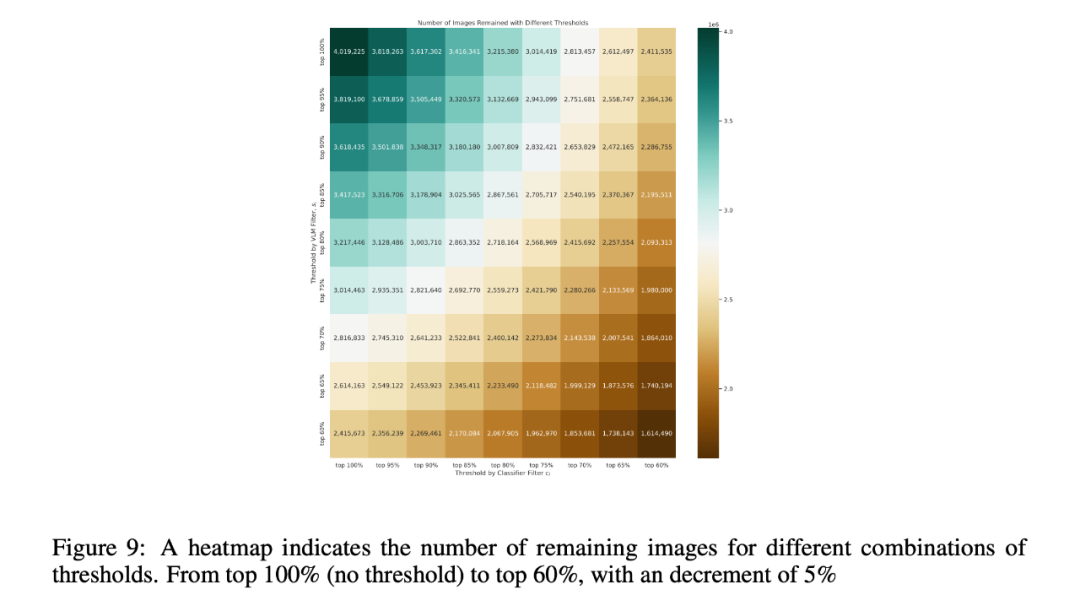
如表 8 和图 9 所示,如果使用前 90% 和前 80% 作为 和 的阈值,VLM Filter 和 RS 图像检测器大概过滤出了 100 万对图像-文本对。这些参数在调节 PUB11 子集的噪声水平方面起着关键作用。理论上,减少 和 的值应该会导致更低的噪声水平。
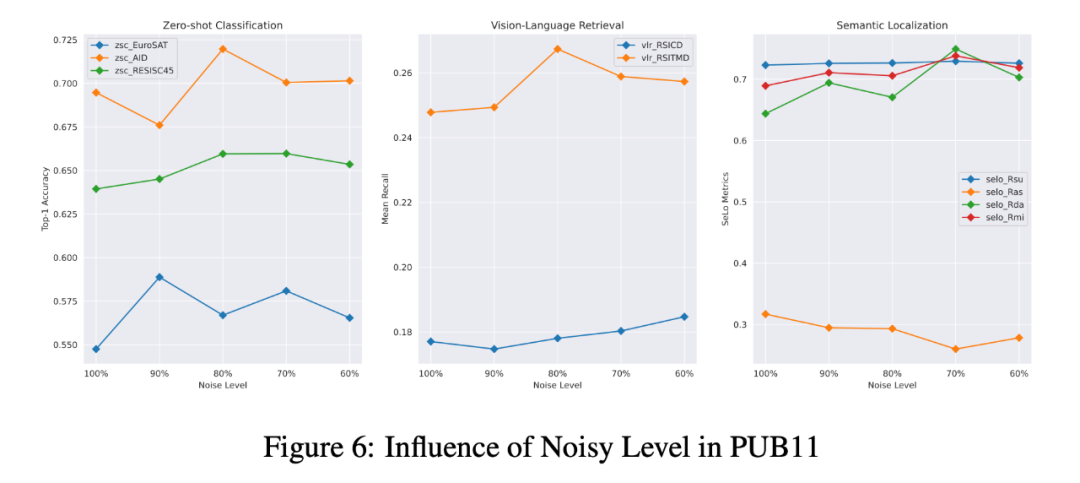
为了弄清 PUB11 噪声水平对 DFM 在下游任务上的表现的影响,作者调整了 和 ,以产生更多具有不同噪声水平的 PUB11 子集。随后,作者用这些子集训练了 Pfeiffer Adapter,并用于 ZSC, VLR 和 SeLo 任务。如下图所示,噪声水平的降低通常会导致 PEFT 方法性能的提高。但是,如果 PUB11 ⼦集中图文对的数量减少过度,则模型的性能会下降。
5.3.3 为文本或图像编码器添加适配器
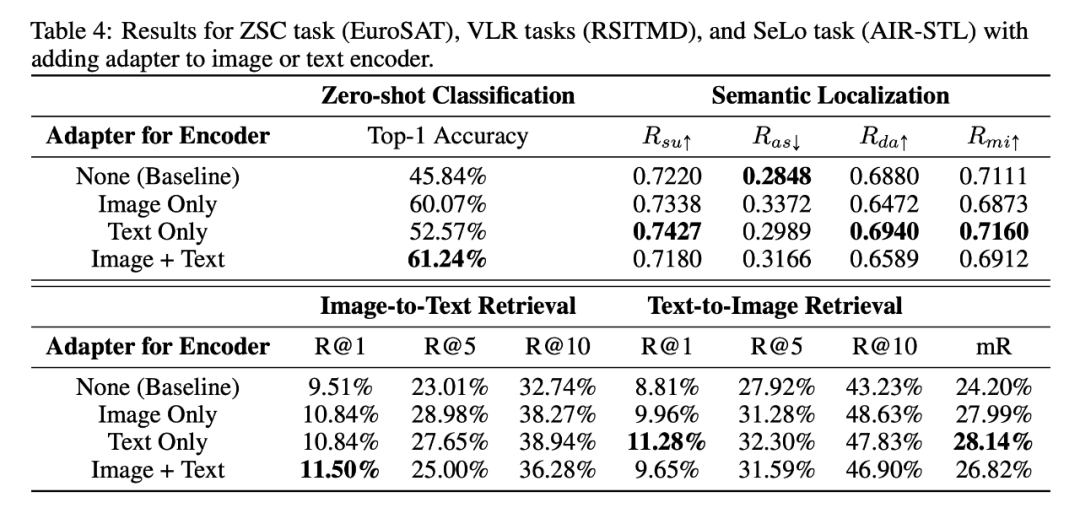
如上表所示,作者显示了仅将 Pfeiffer Adapter 添加到图像编码器或文本编码器 (或同时添加到两者) 的结果。所有模型都使用RS5M数据集进行训练。结果表明,删除图像编码器中的 Adapter 后 、 和 的结果要优于基线和将 Adapter 同时添加到图像和文本编码器中的场景。
这表明图像编码器的 Adapter 会从 RS5M 数据集学到一些特定于图像的知识 (例如,风格),而这可能与语义定位 (SeLo) 任务不太兼容。然而,域内图像显著提高了模型在零样本分类任务上的表现。此外,文本到图像检索任务也受益于向文本编码器单独添加 Adapter。
5.3.4 模型尺寸的影响
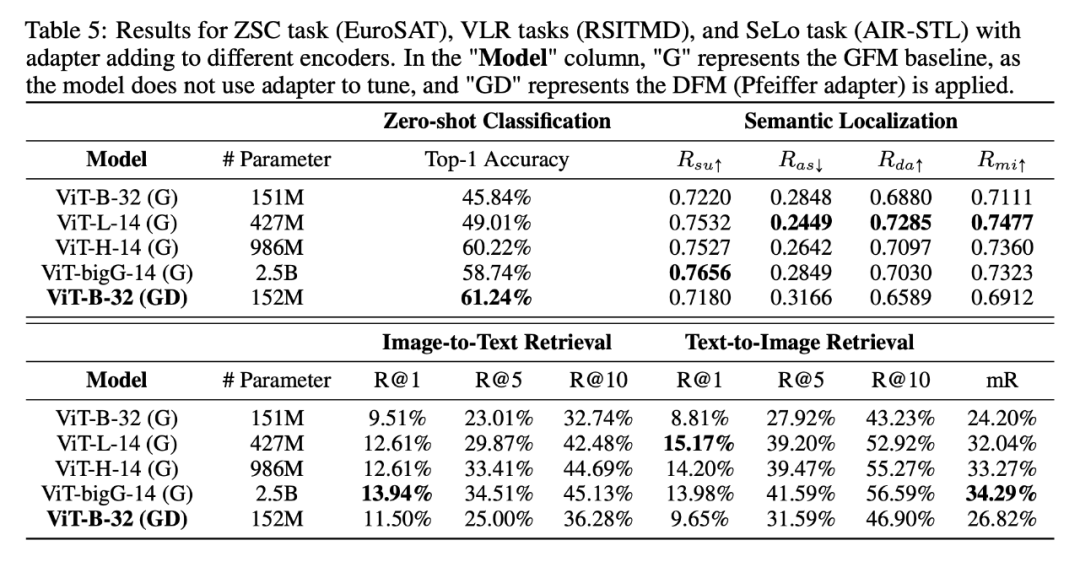
表 5 表明了增加模型大小并不一定保证性能的提高。2.5B 参数的 ViT-bigG-14 模型在 SeLo 和 ZSC 任务中表现不如 ViT-H-14 模型。对于 VLR 任务,最大的模型在平均召回率方面表现最好,比其他模型高出 1% - 10%。令人惊讶的是,RS5M 微调的 ViT-B-32 模型,包含 152M 参数,在 ZSC 任务中表现出色,甚至超过了 ViT-H-14 和 ViT-bigG-14,后者的参数数量分别是前者的 7 倍和 17 倍。
5.3.5 损失函数
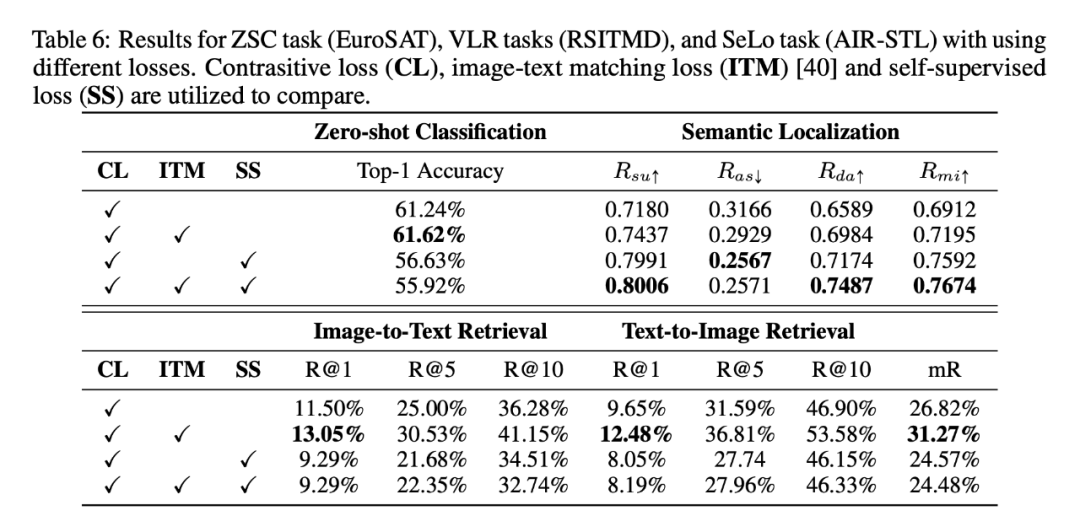
上表展现了额外增加图像-文本匹配损失 (ITM) 能大大提高 DFM 在 ZSC、SeLo 和 VLR 任务上的性能。这个提升要归功于图像和文本内容之间的更好的对齐。然而,对于使用自监督 (SS) 损失的模型,ZSC 和 VLR 任务的性能下降了 4% 到 5%。
有趣的是,这些模型在 SeLo 任务中表现出色,在各种指标上都有显著优势 (为0.06, 为 0.04, 和 为 0.05)。在 ZSC 和 VLR 任务中使⽤ SS 损失的模型性能有所下降,其原因可能是因为训练不充分,因为 SSL 通常需要很⻓的训练时间才能收敛,而我们只训练了几个 Epoch。

总结
作者在本文中引入了一个新的框架 (GFM→DFM→DTM),并构建了首个大规模的遥感图像-文本配对数据集 RS5M。作者尝试了 4 种用 RS5M 训练的 PEFT 方法来实现 DFM,该框架在 ZSC、VLR 和 SeLo 等任务中被证明是有效的。然而,大多数 PEFT 方法并没有考虑到图像和文本模态之间的相互作用,因为它们最初是为 LLM 设计的。这就需要在今后的工作中创建更复杂的 DFM。
此外,虽然本文使用了 VLM 模型对生成的描述文本进行排序,但未来将应该尝试使用更复杂的选择标准,例如将标题分解为短语并将其 ground 到图像细节,从而实现图像与描述之间的细粒度对齐。另一个值得改进的点与作者在数据集制作 pipeline 中对 CLIP 模型的依赖有关,这可能会使得我们的数据集包含 CLIP 中固有的偏见。
最后,作者认为设计更先进的 DFM,并与 RS5M 配合,探索如何将遥感视觉语言模型扩展到其他遥感相关的下游任务是至关重要的。这些任务包括变化检测、目标检测、场景分类、语义分割、RSVQA、RS 域适应以及 UAVs 和卫星图像的匹配等。
更多实验结果和数据集展示可见附录。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·